
table of contents
고지
- 코드 길어서 보기 불편하니까 파일로 따로 올리겠음 알아서 보기: https://drive.google.com/file/d/1Y-fVglgvgpS73qxviT8dSUmNeUkqIenD/view?usp=sharing
- 오늘은 분석 방법론과 인사이트 위주로
실습 프로젝트 1 OEE 분석
님은 스마트팩토리 팀의 데이터 분석가임. 공장에는 3개 라인(A·B·C), 총 12대의 가공설비가 가동 중이며, 6종의 제품을 생산함. 그리고 다음과 같은 요청을 받음.
공장 설비들의 OEE를 쳬게적으로 분석하라
어떤 라인과 설비에서 로스가 가장 큰지, 3월에 시작했던 개선활동 이후 실제로 효과가 있었는지 보여라
고로 할일은 다음과 같음
- 데이터 품질 확인: 기본 정보 확인 후 결측치와 이상치 처리
- OEE 산출: 산수죠?
- Six Big Losses 분석: 비가동 유형별 로스 정량화
- 개선 효과 검증: 3월부터 한 거 그거
- 경영진 보고용 대시보드: 자료는 뭐다? 한 장에 다 보여야 한다
1. 데이터 탐색 및 전처리
데이터 기본 정보
파일 설명 주요 컬럼 p1_equipment.csv설비 마스터 (13대) equipment_id, line, equipment_type, rated_capacity_per_hour p1_product.csv제품 마스터 (6종) product_code, standard_cycle_time_sec, target_defect_rate_pct p1_production_log.csv일별 생산 실적 (~3,100건) production_date, shift, actual_quantity, good_quantity, actual_operating_time_min p1_downtime_log.csv비가동/로스 기록 (~430건) downtime_type, duration_min, cause 공식 다시 봐두세요
- OEE = 가동률(Availability) × 성능률(Performance) × 양품률(Quality)
- 가동률 = 실제가동시간 / 계획가동시간
- 성능률 = (실제생산량 × 기준사이클타임) / 실제가동시간
- 양품률 = 양품수량 / 실제생산량
1-1. 데이터프레임 기본 탐색
설비
1 2 3 4 5 6 7 8 9 10 11 12 13 14
<class 'pandas.DataFrame'> RangeIndex: 13 entries, 0 to 12 Data columns (total 7 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 equipment_id 13 non-null str 1 equipment_name 13 non-null str 2 line 13 non-null str 3 equipment_type 13 non-null str 4 manufacturer 13 non-null str 5 install_date 13 non-null str 6 rated_capacity_per_hour 13 non-null int64 dtypes: int64(1), str(6) memory usage: 860.0 bytes
![]()
제품
1 2 3 4 5 6 7 8 9 10 11 12 13
<class 'pandas.DataFrame'> RangeIndex: 6 entries, 0 to 5 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 product_code 6 non-null str 1 product_name 6 non-null str 2 standard_cycle_time_sec 6 non-null int64 3 category 6 non-null str 4 weight_kg 6 non-null float64 5 target_defect_rate_pct 6 non-null float64 dtypes: float64(2), int64(1), str(3) memory usage: 420.0 bytes
![]()
생산 기록
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
<class 'pandas.DataFrame'> RangeIndex: 3120 entries, 0 to 3119 Data columns (total 13 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 log_id 3120 non-null str 1 production_date 3120 non-null datetime64[us] 2 shift 3120 non-null str 3 equipment_id 3120 non-null str 4 product_code 3120 non-null str 5 planned_quantity 3120 non-null int64 6 actual_quantity 3120 non-null int64 7 good_quantity 3036 non-null float64 8 defect_quantity 3120 non-null int64 9 planned_time_min 3120 non-null int64 10 actual_operating_time_min 3054 non-null float64 11 setup_time_min 3009 non-null float64 12 operator_id 3120 non-null str dtypes: datetime64[us](1), float64(3), int64(4), str(5) memory usage: 317.0 KB
![]()
info에서 양품량이 float로 나오는 게 이상해서 확인해봤는데 값이 잘못 쓰인 건 없고 nan 때문이었음. nan이 float라서.
1 2 3 4 5 6 7
# 양품 갯수가 float로 표기된 사례 확인 has_decimal = (prod_log['good_quantity'].notna()) & ((prod_log['good_quantity'] % 1) != 0) prod_log[has_decimal] # 양품 갯수 != (실제 생산량 - 불량 수) 인 사례 확인 is_calculated = (prod_log['good_quantity'].notna()) & ((prod_log['actual_quantity'] - prod_log['defect_quantity']) != prod_log['good_quantity']) prod_log[is_calculated]
근데 어쨌든 nan이 있으면 확인을 해야지
NA Count NA Ratio (%) setup_time_min 111 3.56 good_quantity 84 2.69 actual_operating_time_min 66 2.12 어떤 놈들이 nan이 들어가나 봤는데 딱히 규칙 없는 것 같더라
![]()
고장 기록
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
<class 'pandas.DataFrame'> RangeIndex: 427 entries, 0 to 426 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 downtime_id 427 non-null str 1 date 427 non-null datetime64[us] 2 equipment_id 427 non-null str 3 shift 427 non-null str 4 downtime_type 427 non-null str 5 start_time 427 non-null datetime64[us] 6 end_time 427 non-null datetime64[us] 7 duration_min 422 non-null float64 8 cause 412 non-null str 9 line 427 non-null str dtypes: datetime64[us](3), float64(1), str(6) memory usage: 33.5 KB
![]()
na 확인 당연히 하죠
NA Count NA Ratio (%) cause 15 3.51 duration_min 5 1.17 어떻게 생겨먹은 nan인지도 한번 봤지
![]()
근데 하필 저 샘플에 고장 타입이 “소정지”인 것들만 자꾸 cause가 비어있는 거야 일부러 그랬나 싶어서 봤는데 아니었음
1 2 3 4 5 6 7 8 9 10 11 12 13
# 고장 타입이 '소정지'인 경우의 원인만 다시 확인, na 포함 카운트 downtime[downtime['downtime_type'] == '소정지']['cause'].value_counts(dropna=False) ''' cause 칩 막힘 22 냉각수 부족 18 공구 파손 17 센서 오감지 13 소재 걸림 10 NaN 4 Name: count, dtype: int64 '''
1-2. 생산 실적 결측치 처리
아까 비어있던 데이터 3개 있잖아. 양품량, 셋업시간, 실가동시간. 그거 채울거임
- 양품량 = 실생산량 - 불량량
- 셋업시간(교대 인수인계 시 기록 누락) = 해당 설비의 평균 셋업 시간
- 실가동시간 = 해당 설비 평균값
fillna를 써도 되고, loc으로 직접 넣어도 된다. 기록 똑바로 있는 원본만 건드리지 말기.
처리 후 결과 깔끔하죠?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
log_id 0
production_date 0
shift 0
equipment_id 0
product_code 0
planned_quantity 0
actual_quantity 0
good_quantity 0
defect_quantity 0
planned_time_min 0
actual_operating_time_min 0
setup_time_min 0
operator_id 0
dtype: int64
1-3. 이상치 탐지
빈 건 그렇다 치고, 썼는데 오타났을 수도 있잖아. 생산량 기준으로 이상치 거르기.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# prod_log의 actual_quantity 컬럼에서 IQR 이상치 탐지해 따로 플래그(is_outlier 컬럼에 True) 추가
Q1 = prod_log['actual_quantity'].quantile(0.25)
Q3 = prod_log['actual_quantity'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
prod_log['is_outlier'] = ~prod_log['actual_quantity'].between(lower_bound, upper_bound)
# 결과 확인
prod_log['is_outlier'].value_counts()
'''
is_outlier
False 3120
Name: count, dtype: int64
'''
해봤는데 이상치 없더라
1-4. 마스터 데이터 결합
산발적으로 로드된 정보를 합쳐서 다같이 써먹자 → 생산 실적에 설비 정보와 제품 정보를 결합
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
결합 전 행 수: 3120 | 결합 후 행 수: 3120
<class 'pandas.DataFrame'>
RangeIndex: 3120 entries, 0 to 3119
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 log_id 3120 non-null str
1 production_date 3120 non-null datetime64[us]
2 shift 3120 non-null str
3 equipment_id 3120 non-null str
4 product_code 3120 non-null str
5 planned_quantity 3120 non-null int64
6 actual_quantity 3120 non-null int64
7 good_quantity 3120 non-null float64
8 defect_quantity 3120 non-null int64
9 planned_time_min 3120 non-null int64
10 actual_operating_time_min 3120 non-null float64
11 setup_time_min 3120 non-null float64
12 operator_id 3120 non-null str
13 is_outlier 3120 non-null bool
14 line 3120 non-null str
15 equipment_type 3120 non-null str
16 equipment_name 3120 non-null str
17 standard_cycle_time_sec 3120 non-null int64
18 category 3120 non-null str
dtypes: bool(1), datetime64[us](1), float64(3), int64(5), str(9)
memory usage: 441.9 KB
1-5. 분석용 파생 컬럼 생성
이 데이터는 아무래도 시계열이 좀 중요한 편. 시간을 조각조각 나눠서 컬럼으로 만들자
| count | mean | min | 25% | 50% | 75% | max | std | |
|---|---|---|---|---|---|---|---|---|
| production_date | 3120 | 2024-03-30 18:57:13.846153 | 2024-01-01 00:00:00 | 2024-02-15 00:00:00 | 2024-04-01 00:00:00 | 2024-05-15 00:00:00 | 2024-06-29 00:00:00 | NaN |
| month | 3120.0 | 3.482372 | 1.0 | 2.0 | 4.0 | 5.0 | 6.0 | 1.701802 |
| week | 3120.0 | 13.504167 | 1.0 | 7.0 | 14.0 | 20.0 | 26.0 | 7.468088 |
| defect_rate | 3120.0 | 1.717106 | 0.07 | 0.97 | 1.54 | 2.3225 | 8.9 | 1.020116 |
| achievement_rate | 3120.0 | 88.988032 | 12.02 | 81.92 | 89.79 | 97.06 | 112.77 | 12.347681 |
요일은 월요일부터 토요일까지 6개만 있다는 점 확인하기
1
2
3
weekday : <StringArray>
['월요일', '화요일', '수요일', '목요일', '금요일', '토요일']
Length: 6, dtype: str
2. OEE 산출
OEE(Overall Equipment Effectiveness, 설비종합효율)은 제조업에서 가장 중요한 KPI 중 하나입니다.
세계적 제조기업들의 OEE 벤치마크:
등급 OEE 의미 World Class 85% 이상 글로벌 상위 Good 70~85% 양호 Average 55~70% 개선 필요 Poor 55% 미만 심각한 로스 왜 OEE인가? 단순 가동률만 보면 ‘속도 로스’와 ‘품질 로스’를 놓칩니다.
OEE는 시간·속도·품질 세 관점을 곱해 진짜 효율을 보여줍니다.
2-1. 건별 OEE 3요소 계산
| count | mean | std | min | 25% | 50% | 75% | max |
|---|---|---|---|---|---|---|---|
| availability | 3120.0 | 0.824858 | 0.073429 | 0.5523 | 0.779150 | 0.8296 | 0.877400 |
| performance | 3120.0 | 0.915007 | 0.080157 | 0.1668 | 0.886775 | 0.9214 | 0.956225 |
| quality | 3120.0 | 0.982829 | 0.010201 | 0.9110 | 0.976775 | 0.9846 | 0.990300 |
| OEE | 3120.0 | 0.743702 | 0.105779 | 0.0960 | 0.682675 | 0.7509 | 0.813400 |
표를 보면 졸려 그러니까 그림을 그려야돼
이건 내가 다른 프로젝트 할 때 그리던 방식임
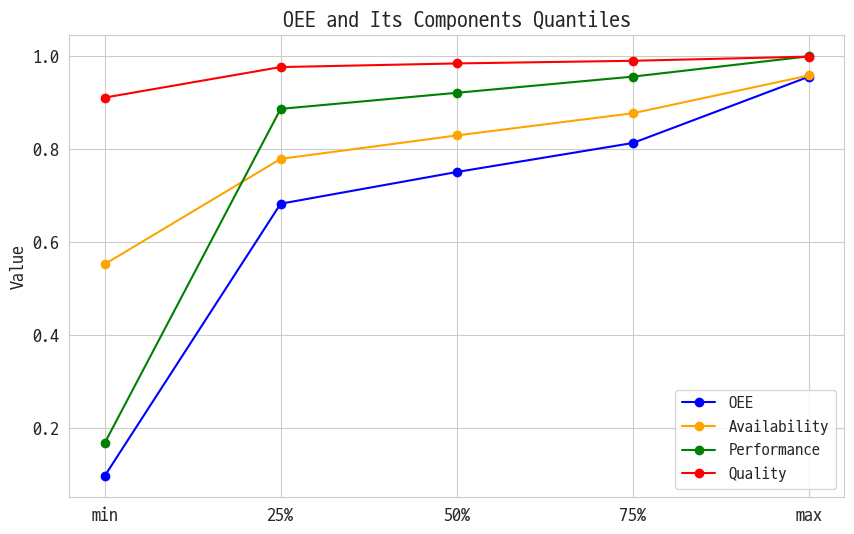
이건 아마도? 정석적인 비교 그래프지 않을까 싶음
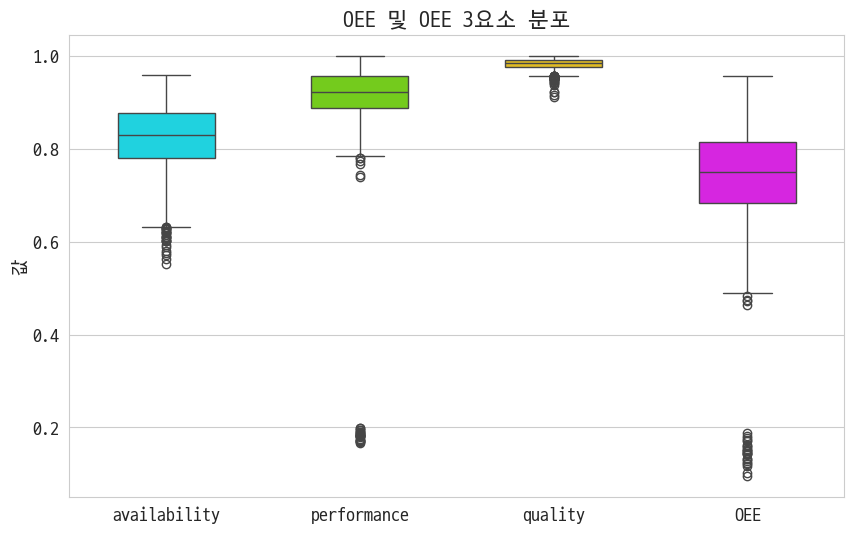
퀄리티는 뭐 거의 문제 없는데 가동률이 제일 떨어짐. 그게 떨어지니까 OEE도 당연 떨어지지.
2-2. 설비별 OEE 집계
설비별 OEE 집계하고 누가 제일 못하는지 확인하기
| equipment_id | availability | performance | quality | OEE | equipment_name | line | |
|---|---|---|---|---|---|---|---|
| 2 | EQ-A03 | 0.698126 | 0.878415 | 0.964568 | 0.592373 | 밀링머신-A3 | A라인 |
| 0 | EQ-A01 | 0.787263 | 0.879343 | 0.980208 | 0.678936 | CNC선반-A1 | A라인 |
| 1 | EQ-A02 | 0.783244 | 0.884347 | 0.980889 | 0.679683 | CNC선반-A2 | A라인 |
2-3. 라인별·월별 OEE 추이
상부의 요구사항 중 하나가 3월 전후로 개선 변화량을 보는 거였음. 그걸 하겠다.
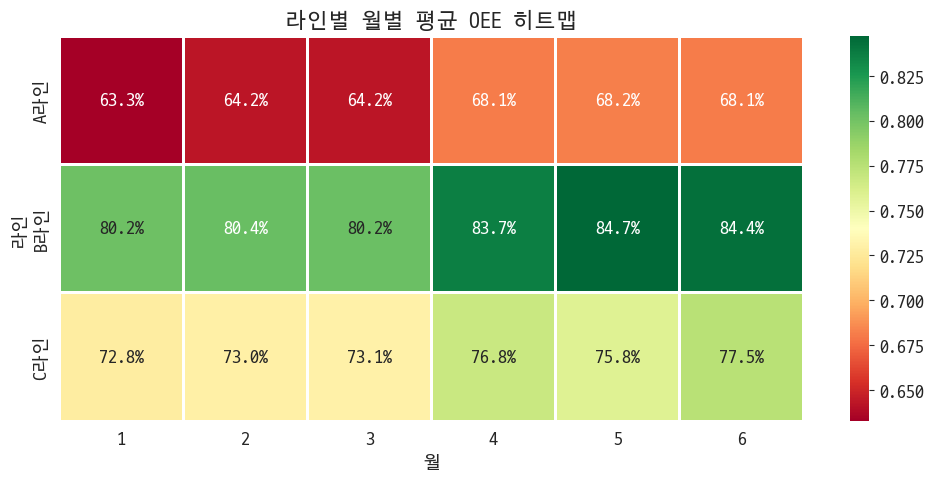
밝아지긴 했네
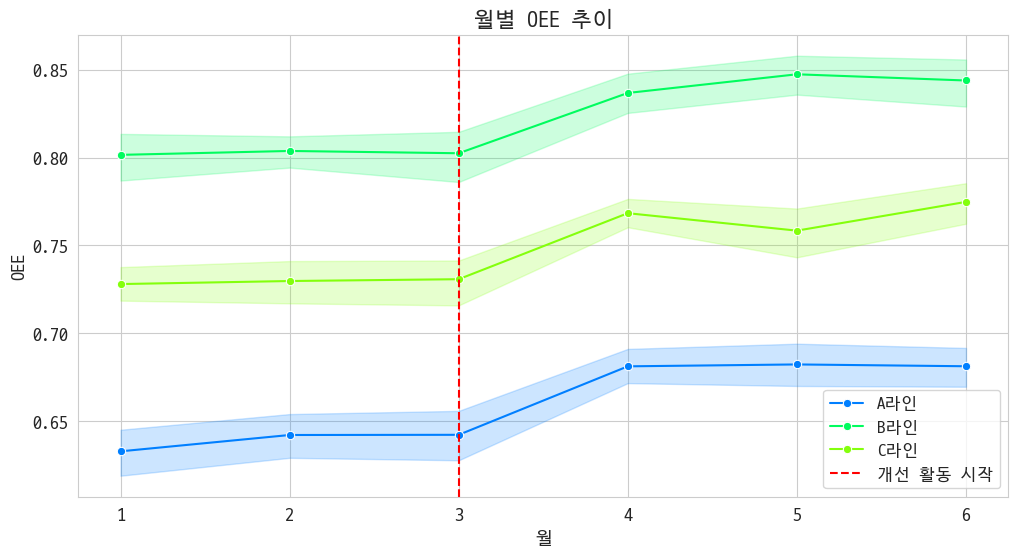
약간 오르긴 했음
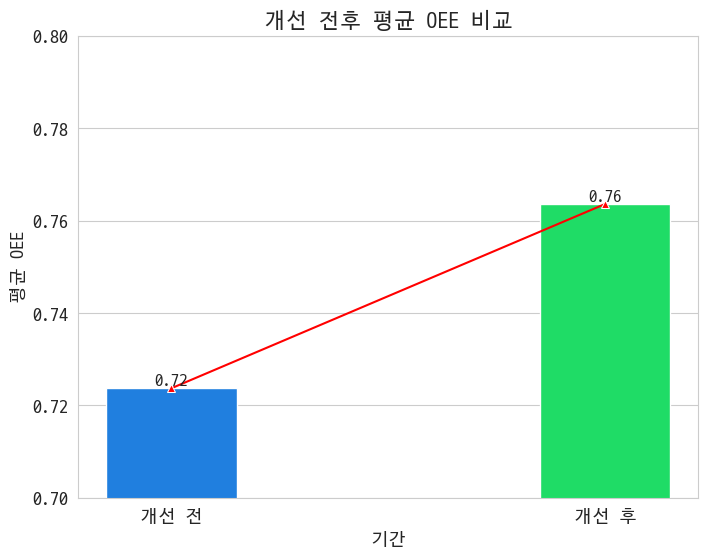
사실 이 그래프 과장했음. 아주 쪼끔 개선됐음. 0.04밖에 안오름. 암튼 개선은 됐는데 미미하죠?
3. 심화 분석
- 개선은 했지만 아직 좀 더 할 수 있을 것 같고
- 문제가 있어 보이긴 하는데 어디가 문제인지는 모른다
라는 사유로 좀 더 보겠다
3-1. 교대조별 OEE 비교
야간 교대조가 주간 교대조보다 일을 못하는 것 같다는 그런 설정~
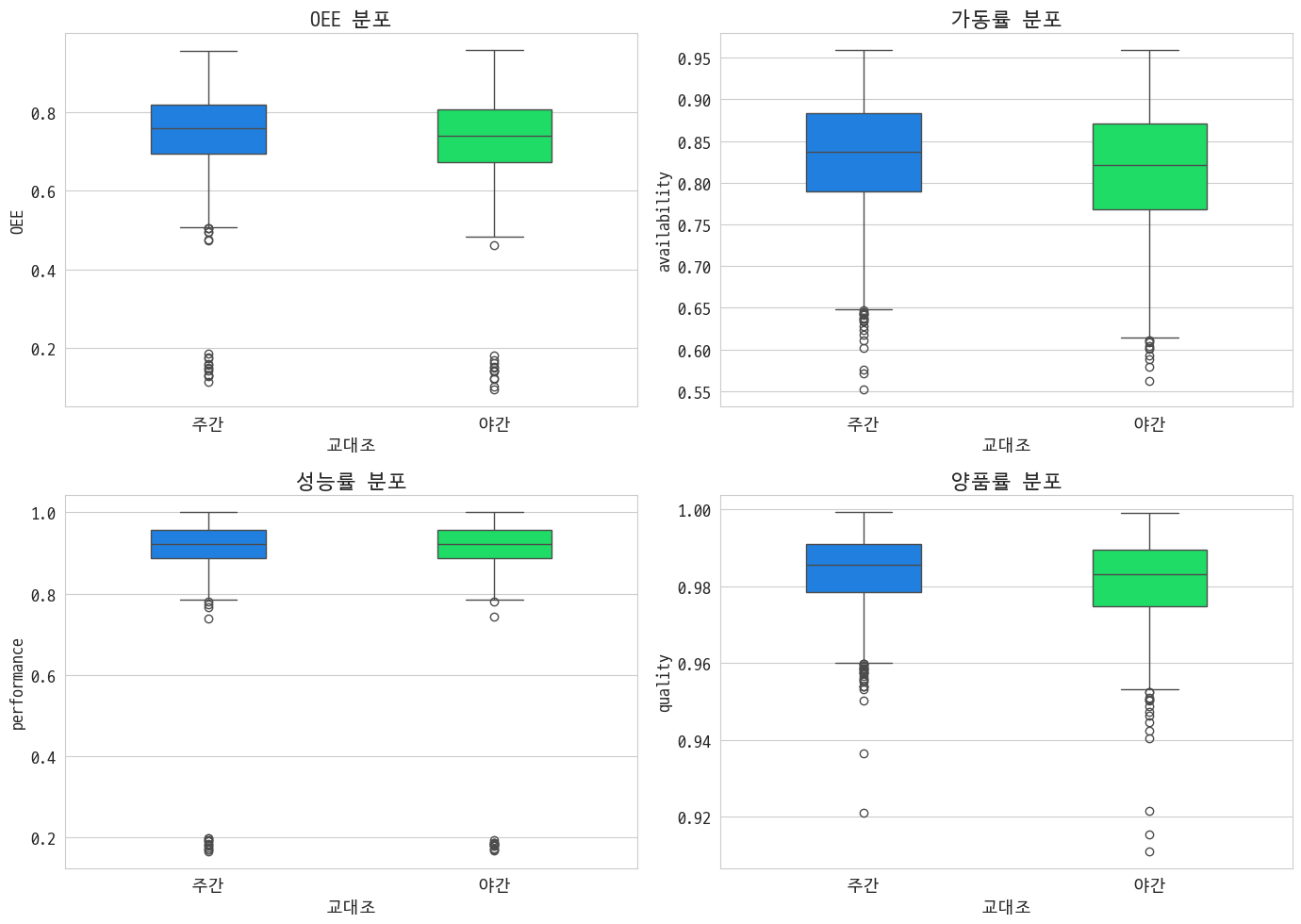
T-test 결과: t-statistic = 4.6184, p-value = 0.0000
근데 비교해보니 실제로 못한 게 맞았다는 결과~ 가동률이랑 양품률이 떨어짐
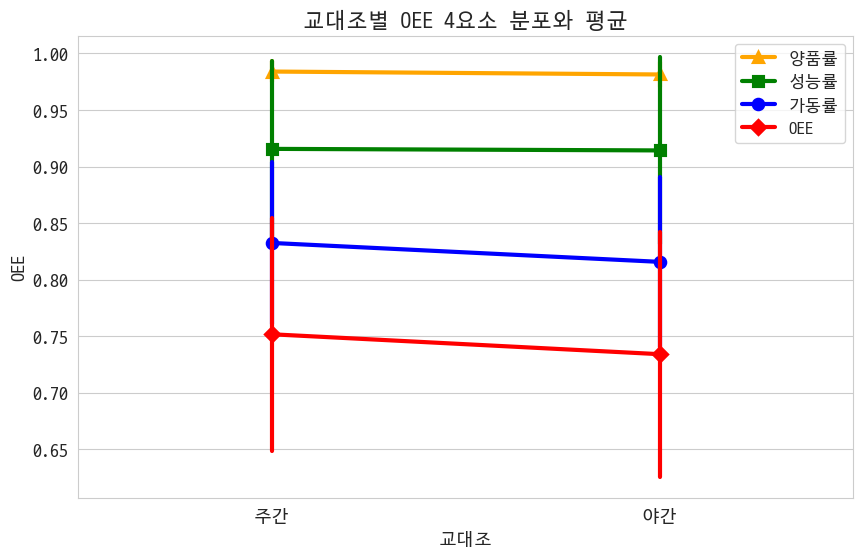
한 데 모아서 다시 봐도 차이가 난다~ 가동률이 차이였다~
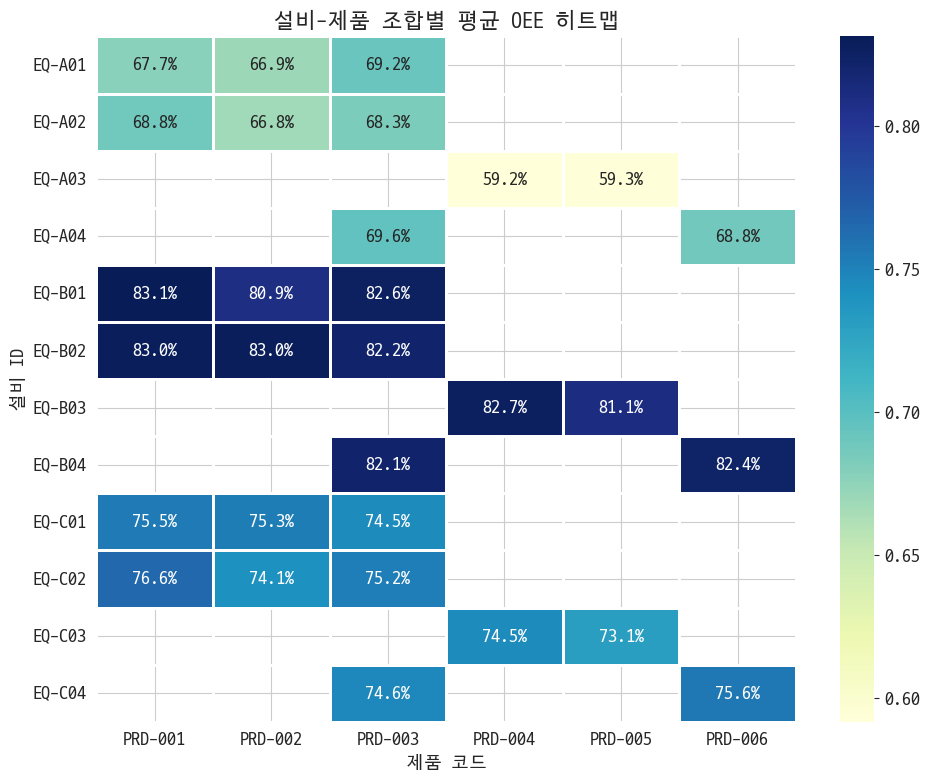
3-2. 설비-제품 매트릭스 분석
이번엔 설비*제품별 성능을 확인해보겠다
상위 5개와 하위 5개를 비교해보겠다
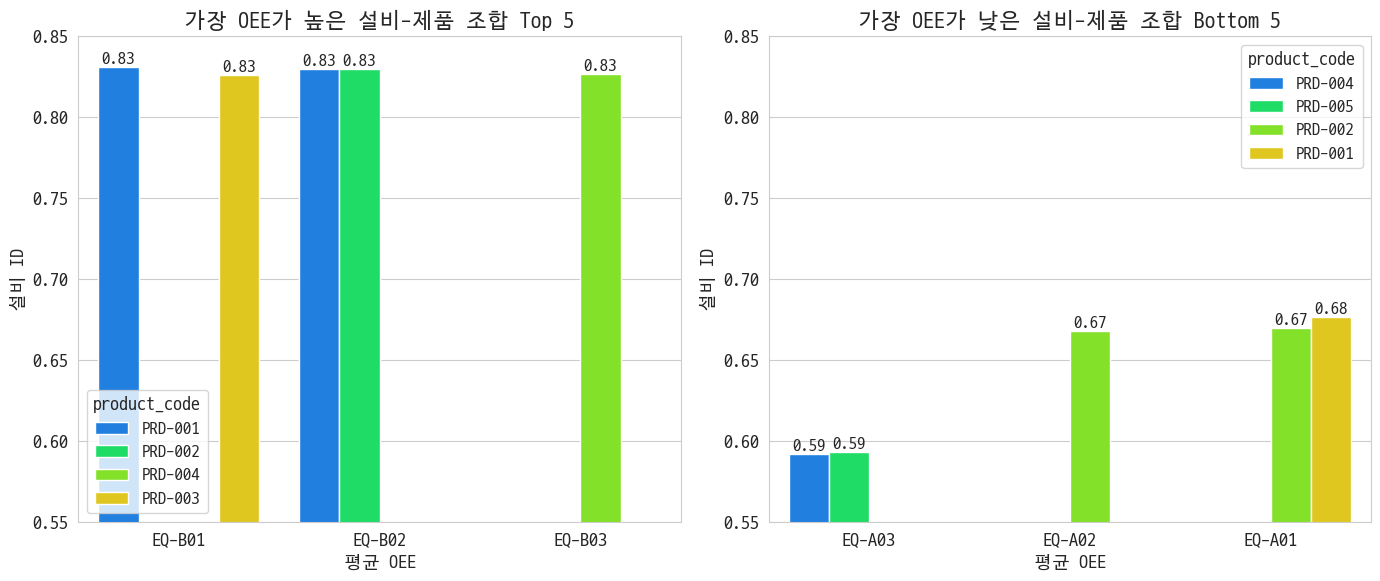
대체로 A라인이 못하고 B라인이 잘하네. 제품이 거기서 거기인 걸 봐선 제품 문제는 아닌듯
3-3. 요일별 생산성 패턴 분석
월요병과 불금병이 있다는 소문이 있으니 확인해봐라
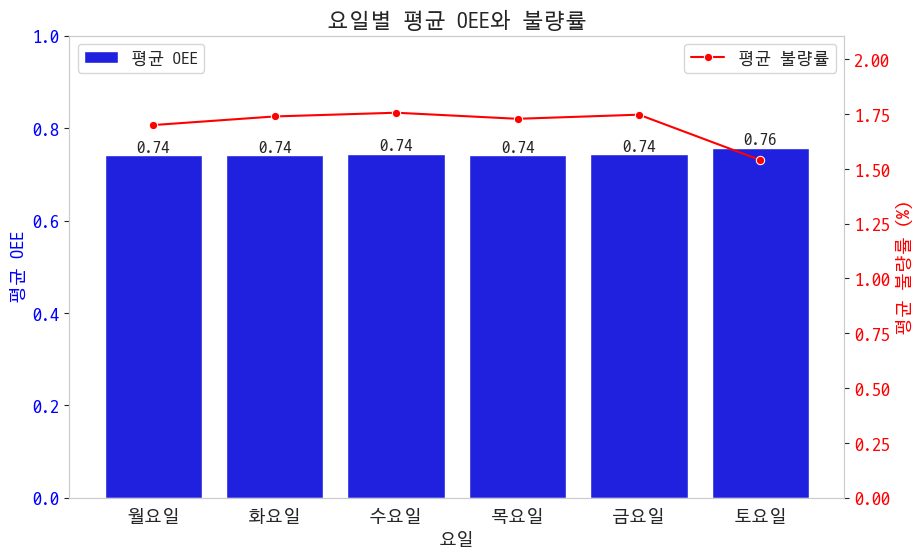
그냥 평일이 문제인 것 같은데요 토요일에만 일 시키자 주말 특근하시는 분들이 일을 더 잘하시네
3-4. 계획 달성률 vs 불량률 관계 분석
???: 주문량이 많으니까 불량이 늘어나는 거 아니냐
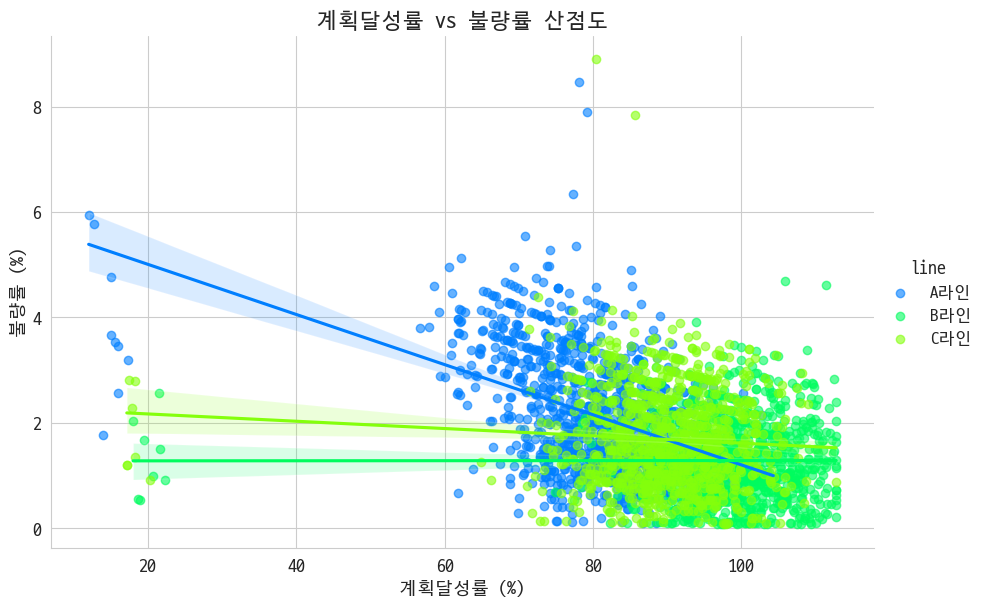
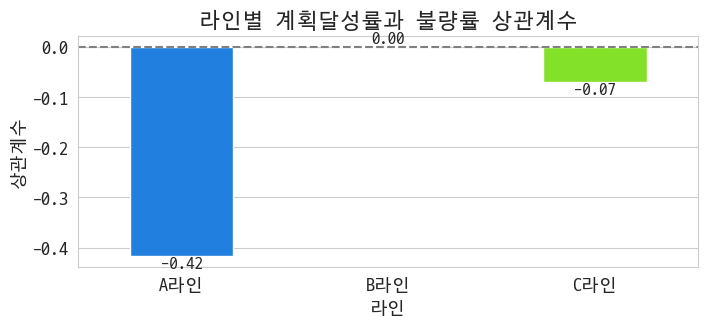
그러나 밝혀지는 진실: 생산량이 많으면 오히려 불량률이 떨어진다~ 특히 A라인에서~
근데 여기 아까는 OEE 혼자 떨어졌는데 왜 잘함?
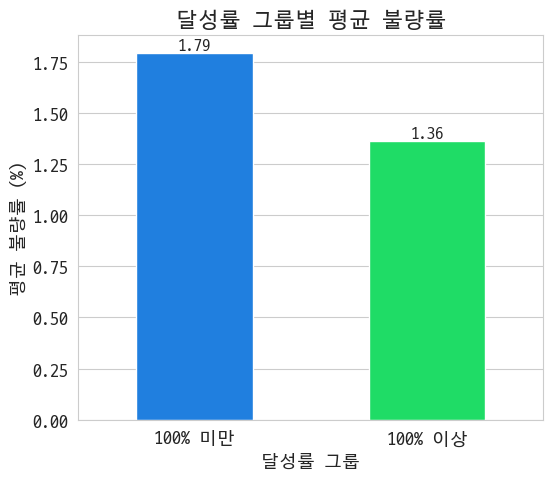
라인 구분 없이 계획 생산량을 똑바로 지키면 오히려 불량률이 떨어진지기도 한다~
T-test 결과: t-statistic = -10.7551, p-value = 0.0000
두 달성률 그룹 간 불량률 차이는 통계적으로 유의하고, 왠지 A그룹이 불량률 감소에 기여하고 있을 것 같다~
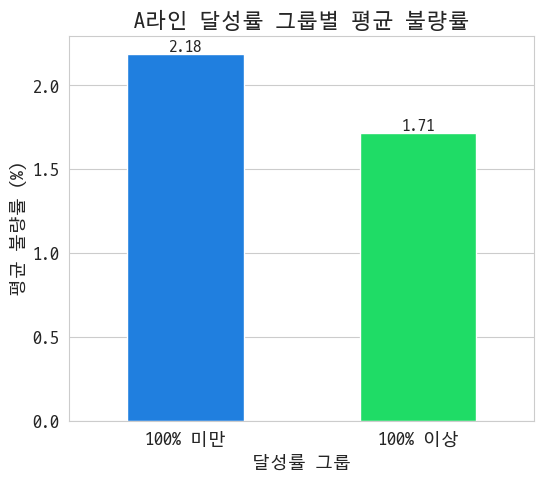
근데 A라인만 떼놓고 보니까 평균보다 불량률이 높음. 역시 A라인은 통나무였던 거임~
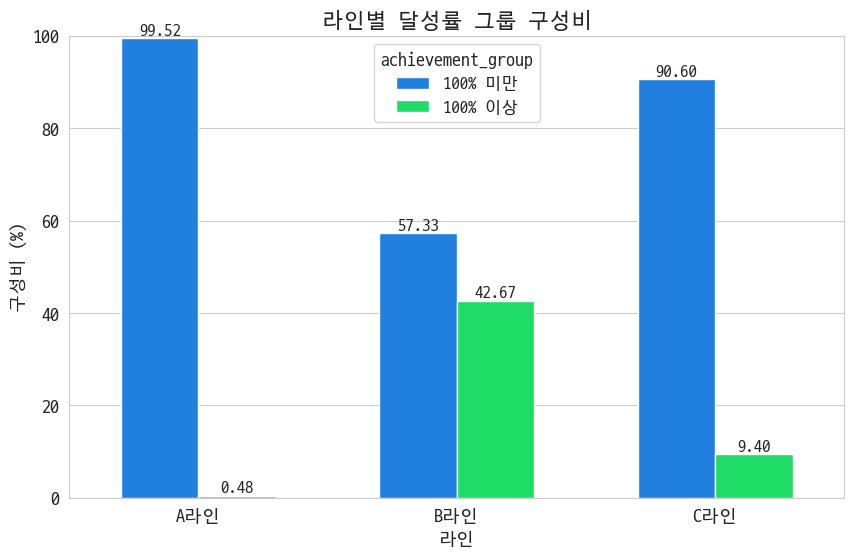
그래 이게 통계의 함정이지 A라인이 그거네 1%의 우수사원이 나머지를 먹여살렸네. 그럼 A라인이 OEE가 떨어지는 게 좀 이해가 됨.
4. Six Big Losses
TPM(Total Productive Maintenance)에서는 설비 효율을 떨어뜨리는 원인을 6대 로스(Six Big Losses)로 분류합니다:
분류 로스 유형 OEE 영향 정지 로스 ① 설비고장, ② 셋업/조정 가동률 ↓ 속도 로스 ③ 소정지, ④ 속도저하 성능률 ↓ 불량 로스 ⑤ 초기불량, ⑥ 공정불량 양품률 ↓
4-1. 비가동 유형별 분석
일단 고장 기록의 결측치를 먼저 처리하고
duration_min결측: 같은downtime_type의 평균값으로 대체cause결측: ‘원인미상’으로 대체
비가동 유형별 데이터를 그려봤다
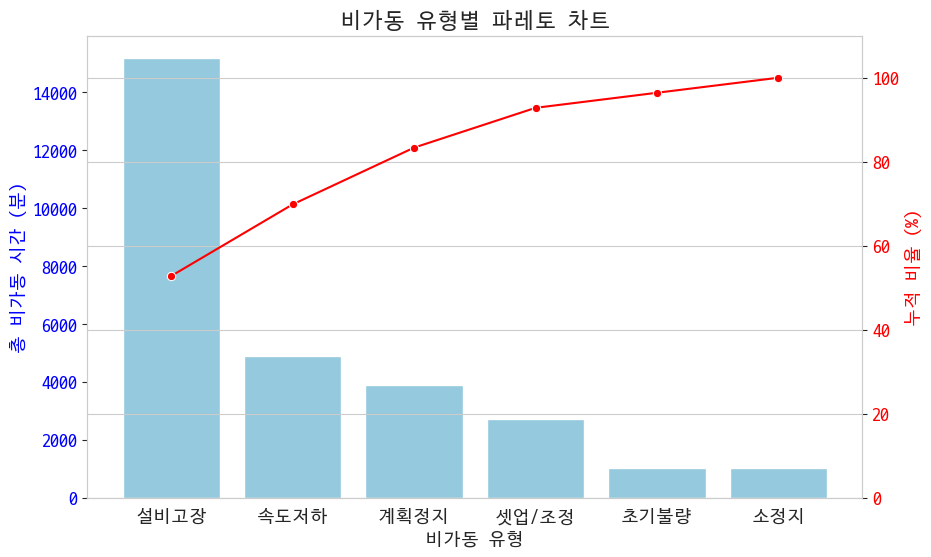
설비 고장이 압도적
근데 이거 봐봤자 그래서 뭐요 싶죠
4-2. 설비별 비가동 패턴 분석
어떤 설비에서 어떤 비가동이 많은지 보자
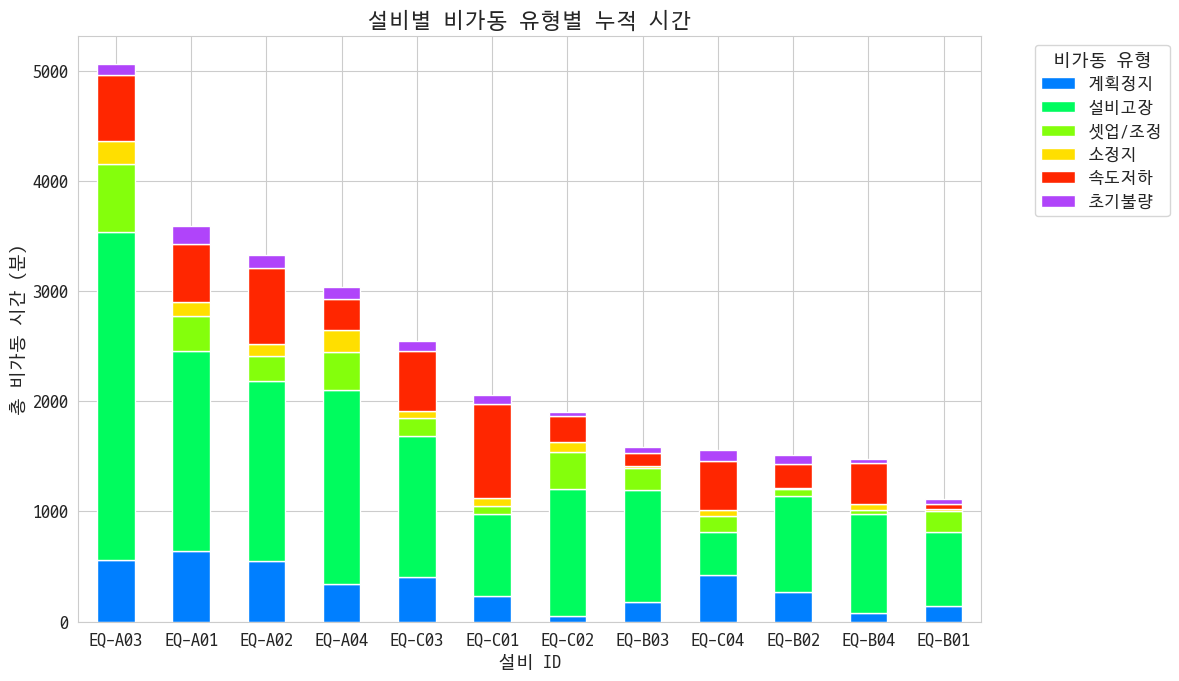
역시나 또 A라인이 다들 문제인 거임
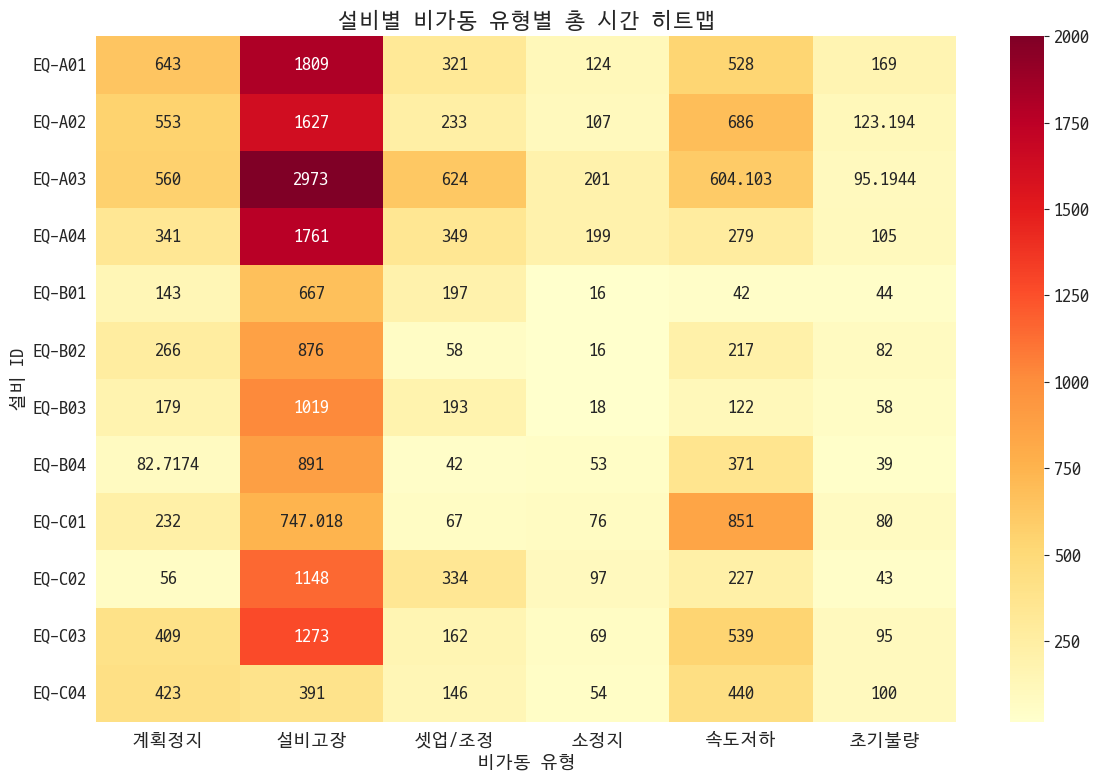
고장 자체는 설비고장이 제일 많았던 거임
그와중에 EQ-D01은 새로 추가된 설비라 비가동 기록이 아예 없었다~
4-3. 설비고장 원인 Top 분석
그럼 이제 고장은 왜 났는지 보겠다는 거지
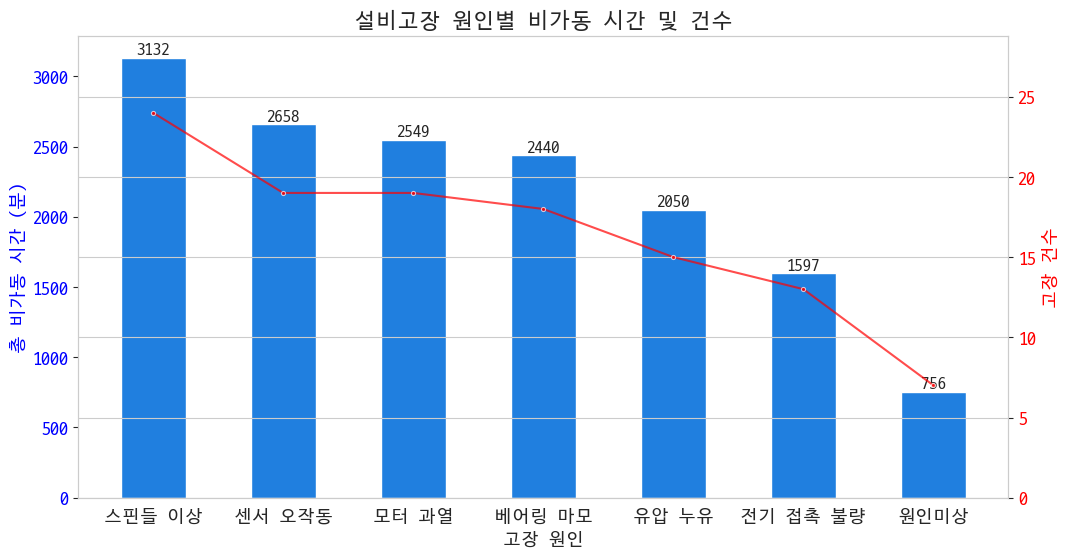
스핀들 이상이 제일 많고 오래걸렸구나~
그럼 이제 또 무슨 라인이 문제야?
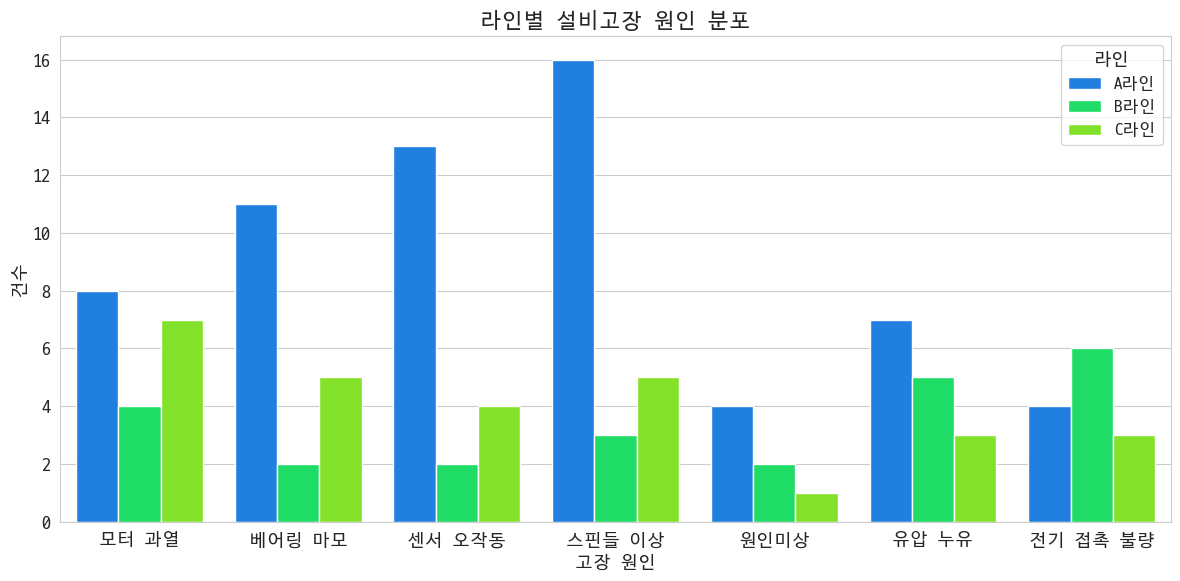
역시나 A라인이 문제야
개선 효과가 있니?
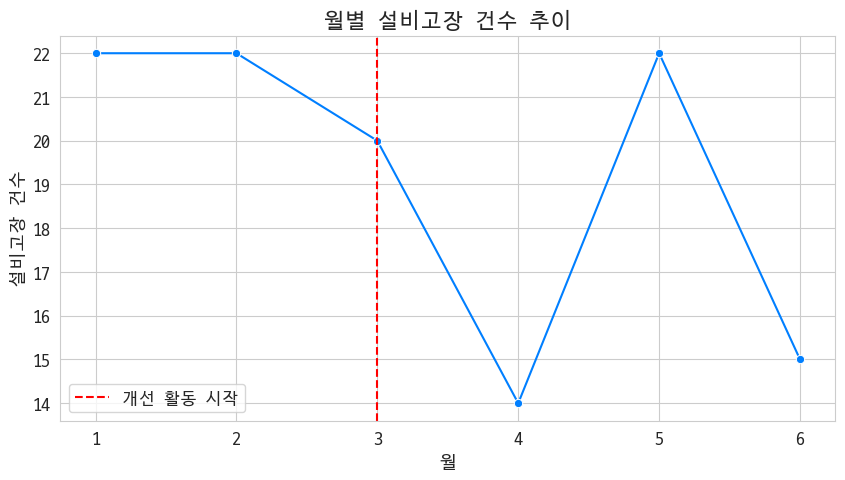
개선 효과는 일시적인듯^^ 5월엔 무슨 일이 있었나요?
5. 경영진 보고용 대시보드
나는 무슨 일이 있었던 건지 아직도 똑바로 파악을 못한 것 같은데 실습문제가 최종 대시보드를 만들래
예쁜 것보다 한눈에 보이는 게 중요하댑니다
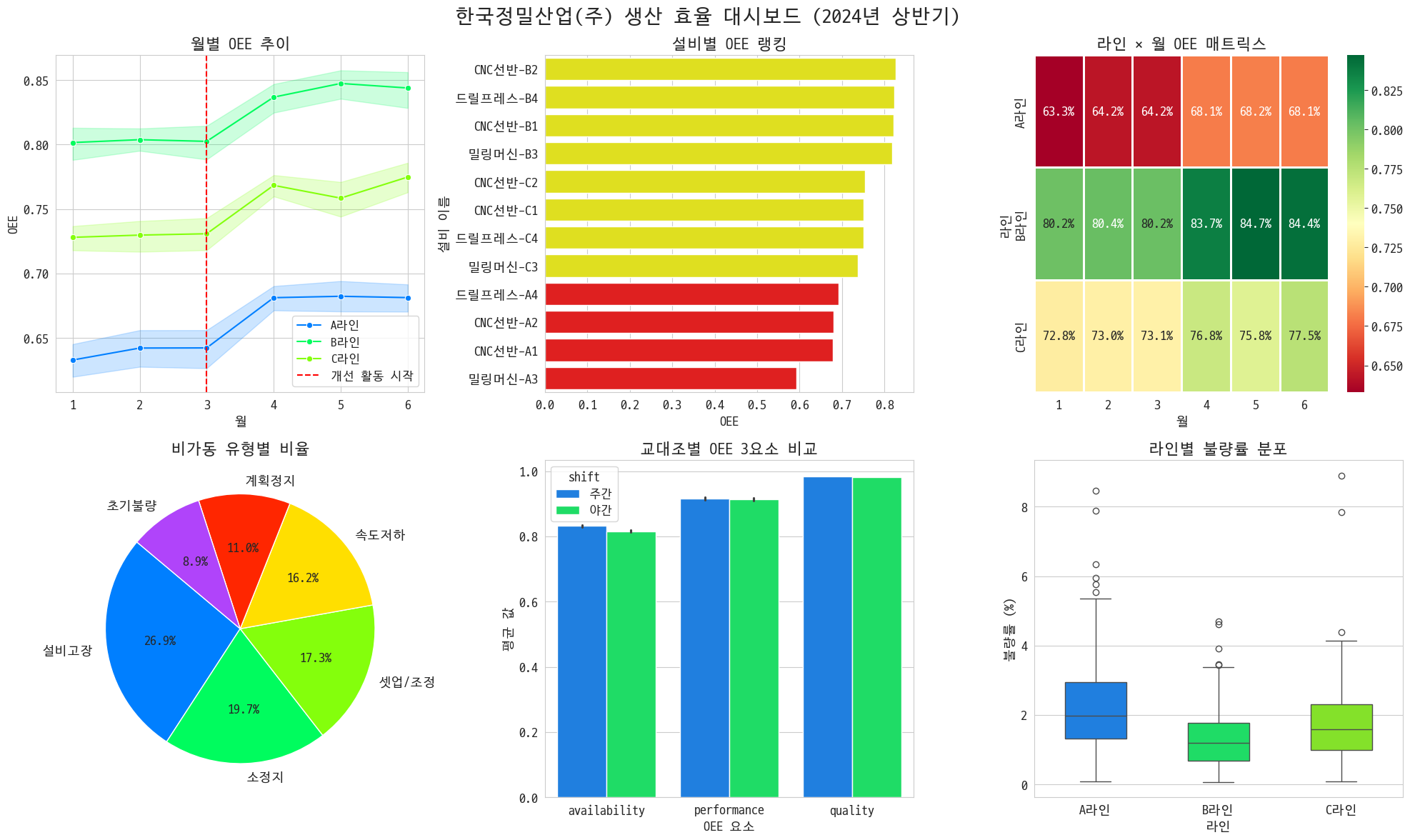
근데 나는 맘에 안들어서 저게 나름 덜 못생기게 만든 거임
분석 결론
- 현재 공장 OEE 수준: 좀 별로인듯
- OEE를 끌어내리는 주요 요인: A라인 가동률이요
- 개선 활동 효과: 별로인듯
- 라인별 차이: 좀 큼 A라인 사원들 교육 좀 잘 시키고 설비 좀 잘 관리하고 뭐 그래라
- 우선 개선 대상: A라인이요 스핀들 좀 똑바로 고쳐라
- 구체적 개선 제안: 설비를 똑바로 고치고 달성률을 좀 높이세요. 야간 교대조는 일 좀 똑바로 하라고 하세요 피곤하시겠지만