
덤
- 프로그래밍할 때 소수(float)는 등호로 비교하는 거 아닙니다,, 부동소수점이라는 게 있잖아요 사람 눈에만 안보이는거지 사실 저 뒤에 숫자가 또 붙어있을 수도 있다고요(이진 표현의 한계) 등호 비교하는 거 아닙니다. 근데 뭐 엄밀하게 따질 거 아니면 어느 정도는 계산이 되긴 함
- 부동소수점 오차의 원인
컴퓨터는 데이터를 이진수(Binary)로 처리합니다. 정수는 이진수로 정확히 변환되나, 0.1이나 0.2와 같은 십진수 소수는 이진수로 변환 시 무한 소수가 발생합니다 [1].
- IEEE 754 표준: 대부분의 현대 컴퓨팅 시스템은 실수를 표현하기 위해 IEEE 754 표준을 사용합니다. 유한한 비트(예: 32비트, 64비트) 내에 무한 소수를 저장해야 하므로, 특정 지점에서 값을 절삭하거나 반올림하게 됩니다.
- 오차 발생: 이 과정에서 실제 값과 저장된 값 사이에 미세한 차이(Rounding error)가 발생합니다. 예를 들어, $0.1 + 0.2$의 결과는 이진 부동소수점 연산에서 $0.30000000000000004$와 같이 계산됩니다 [2].
- 부동소수점 비교 방법 ($a == b$)
부동소수점 오차 때문에 산술 연산 결과로 얻은 두 소수를 직접 비교 연산자(
==)로 비교하면False가 반환될 가능성이 높습니다. 따라서 다음과 같은 방법을 권장합니다.앱실론(Epsilon)을 이용한 허용 오차 비교
두 값의 차이의 절대값이 기계 앱실론($\epsilon$) 또는 사용자가 정의한 아주 작은 임계값보다 작은지 확인합니다 [3].
수식: $ a - b < \epsilon$
프로그래밍 언어별 전용 함수 사용
대부분의 언어는 부동소수점 비교를 위한 내장 함수를 제공합니다.
- Python:
math.isclose(a, b) - C++:
std::abs(a - b) < std::numeric_limits<double>::epsilon() - JavaScript:
Number.EPSILON활용
- Python:
정밀도가 중요한 경우 (금융, 과학 계산)
이진 부동소수점 대신 십진법을 기반으로 하는 라이브러리를 사용하여 오차를 원천 차단합니다.
- Python:
decimal모듈 - Java:
BigDecimal클래스 - 참고문헌
- Python:
[1] IEEE. (2019). IEEE Standard for Floating-Point Arithmetic. IEEE Std 754-2019. https://ieeexplore.ieee.org/document/8766229
[2] Goldberg, D. (1991). What Every Computer Scientist Should Know About Floating-Point Arithmetic. ACM Computing Surveys (CSUR). https://docs.oracle.com/cd/E19957-01/806-3568/ncg_goldberg.html
[3] Microsoft Learn. (2023). Floating-point numerical types (C# reference). https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/builtin-types/floating-point-numeric-types
요약
- matplotlib 시각화 기본 개념
- Figure / Axes 구조 이해 :
plt.figure(),plt.subplots()로 캔버스·좌표축 생성 - 기본 설정 :
figsize,title(),xlabel(),ylabel(),legend(),grid() - 한글·마이너스 폰트 설정 :
rcParams['font.family'],axes.unicode_minus = False
- Figure / Axes 구조 이해 :
- 라인 플롯(일별 생산량 추이)
plot()으로 일자별 생산량 변화 그리기 (01_daily_production.png)- 마커·색상·선 스타일 변경, 최대/최소 지점 표시
- x축 회전(
plt.xticks(rotation=45))과 레이아웃 정리(plt.tight_layout())
- 부분 필터 + 시각화
- 특정 교대조(예: shift 1)만 필터링 후 라인 그래프 (
02_daily_production_shift1.png) - 동일 지표를 교대조별로 비교할 수 있도록 색상·레이블 통일
- 특정 교대조(예: shift 1)만 필터링 후 라인 그래프 (
- 막대그래프(설비·제품별 비교)
- 설비별 생산량 막대그래프(
03_eq_production.png), 정렬·레이블 표시 - 가로 막대그래프(
barh)로 설비명이 긴 경우 가독성 개선 (04_eq_production_h.png) - 제품별 생산량 vs 불량률을 한 눈에 비교하는 복합 그래프 (
05_product_vs_defect.png)
- 설비별 생산량 막대그래프(
- 분포·구성 비율 시각화
- 생산량 분포 히스토그램(
hist)으로 편향·분산 확인 (06_hist.png) - 교대조별 생산 비중 파이 차트 (
07_pie_shift.png) - 설비별 생산 비중 파이 차트 (
08_pie_eq.png)
- 생산량 분포 히스토그램(
- 시각화 인사이트 (해석·활용 관점)
- 핵심 질문 : “어느 설비·교대·제품이 생산을 가장 많이 담당하고 있는가?”, “일별 생산량·불량률 추세에서 이상 패턴은 없는가?”, “어떤 설비·라인에 개선·투자를 먼저 해야 하는가?”
- 라인 그래프 : 일별·교대별 생산량 추이를 한 눈에 보면 증가·감소 트렌드와 이상일(outlier)을 빠르게 찾을 수 있음. 이동평균·전일 대비 변화율과 함께 보면 단기·중기 흐름을 동시에 해석 가능.
- 막대그래프 : 설비·제품별 생산량을 비교하면 주력 설비·제품과 부하가 과도하게 몰린 설비를 파악할 수 있음. 생산은 많은데 불량률도 높은 설비·제품은 품질 개선 1순위 후보.
- 히스토그램·파이 차트 : 생산량 분포를 보면 평균 근처에 몰려 있는지, 일부 설비만 과도하게 높은지를 확인할 수 있고, 파이 차트로 교대·설비 비중을 보면 특정 교대조·설비 의존도를 파악해 리스크·인력 배치 전략을 세울 수 있음.
- 시각화 표준화 : 같은 스타일·색상·범례 규칙을 통일하면, 대시보드·보고서에서 한 번에 의미를 해석할 수 있어 협업·커뮤니케이션 효율이 크게 올라감. matplotlib 기본기를 익혀 두면 이후 seaborn·대시보드 도구로 확장할 때도 기반이 단단해짐.
실습 문제 풀이함
강사님 답안은 아니고 내가 cursor랑 만든 답지임: 260210_05_advanced_practice.html
저장해서 크롬으로 열어보면 보인다.
그래프를 그려
- 목적
- 시간 변화: 선 그래프
- 항목 비교: 막대 그래프
- 상관관계: 히트맵
- 분포 파악: 히스토그램
- 비율 비교: 파이차트
- 데이터 특성
- 시계열: 선 그래프
- 범주: 막대
- 두 변수 간 관계(딱 2개만): 산점도
- 분포: 히스토그램
- 구성: 파이차트
내가 그래프 그릴 때마다 쓰는 코드 있어
1
2
3
4
5
6
7
8
9
10
11
12
13
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = "Malgun Gothic"
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.size'] = 13 # 기본 폰트 크기
plt.rcParams['axes.labelsize'] = 13 # x,y축 label 폰트 크기
plt.rcParams['xtick.labelsize'] = 13 # x축 눈금 폰트 크기
plt.rcParams['ytick.labelsize'] = 13 # y축 눈금 폰트 크기
plt.rcParams['legend.fontsize'] = 12 # 범례 폰트 크기
plt.rcParams['figure.titlesize'] = 15 # figure title 폰트 크기
print(plt.rcParams['font.family'])
매번 하던 데이터 불러오기
1
2
3
4
5
6
7
8
9
10
import os
import numpy as np
import pandas as pd
data_route = '../강의자료/smart-practice/data'
data_list = os.listdir(data_route)
data_list = [os.path.join(data_route, data_list[i]) for i in range(len(data_list))]
img_save = '../img/260211/'
os.path.exists(data_route), len(data_list), data_list[0]
라인 차트
일별 생산량
1
2
3
4
data_prd = pd.read_csv(data_list[4], parse_dates=['production_date'])
data_eq = pd.read_csv(data_list[0])
data_prd['defect_rate'] = (data_prd['defect_quantity'] / data_prd['actual_quantity'] * 100).round(2)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 일별 생산량
day_prd = data_prd.groupby('production_date')['actual_quantity'].sum()
figname = '01_daily_production.png'
plt.figure(figsize=(12, 4))
plt.plot(day_prd, marker='.', color='blue', linewidth=0.7, linestyle='--')
plt.title(f'[{figname}] 일별 총 생산량')
plt.xlabel('날짜')
plt.ylabel('생산량')
plt.xticks(rotation=0, backgroundcolor='yellow', color='blue')
plt.grid(alpha=1)
plt.tight_layout()
plt.savefig(img_save + figname)
plt.show()
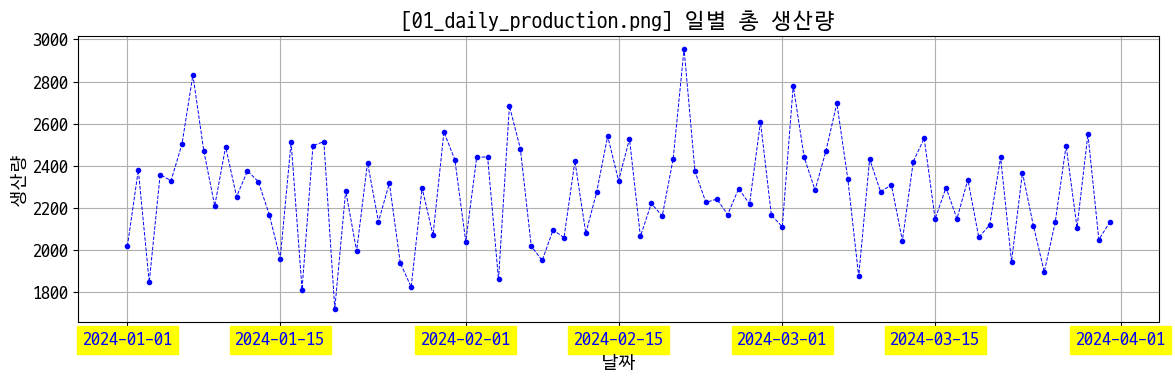
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 일별 생산량
figname = '02_daily_production_shift1.png'
plt.figure(figsize=(12, 4))
plt.plot(day_prd, color='grey', linestyle='--')
plt.plot(day_prd.shift(1), marker='.', color='blue')
plt.title(f'[{figname}] 일별 총 생산량')
plt.xlabel('날짜')
plt.ylabel('생산량')
plt.xticks(rotation=0, backgroundcolor='yellow', color='blue')
plt.grid(alpha=1)
plt.tight_layout()
plt.savefig(img_save + figname)
plt.show()
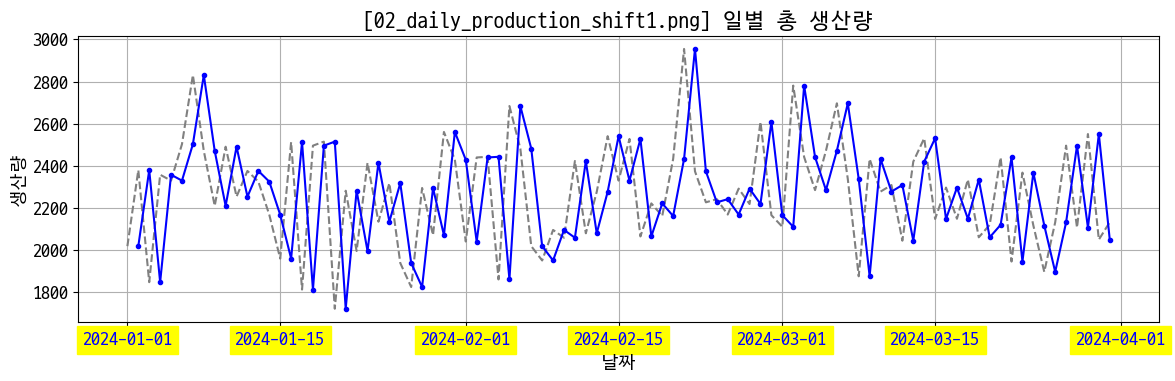
바 그래프
설비별 생산량
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 설비별 생산량
eq_prd = data_prd.groupby('equipment_id')['actual_quantity'].sum().sort_values(ascending=False)
figname = '03_eq_production.png'
plt.figure(figsize=(10, 6))
plt.bar(eq_prd.index, eq_prd.values, color='blue', width=0.4)
plt.title(f'[{figname}] 설비별 총 생산량')
plt.xlabel('설비')
plt.ylabel('생산량')
plt.grid()
plt.tight_layout()
plt.savefig(img_save + figname)
plt.show()
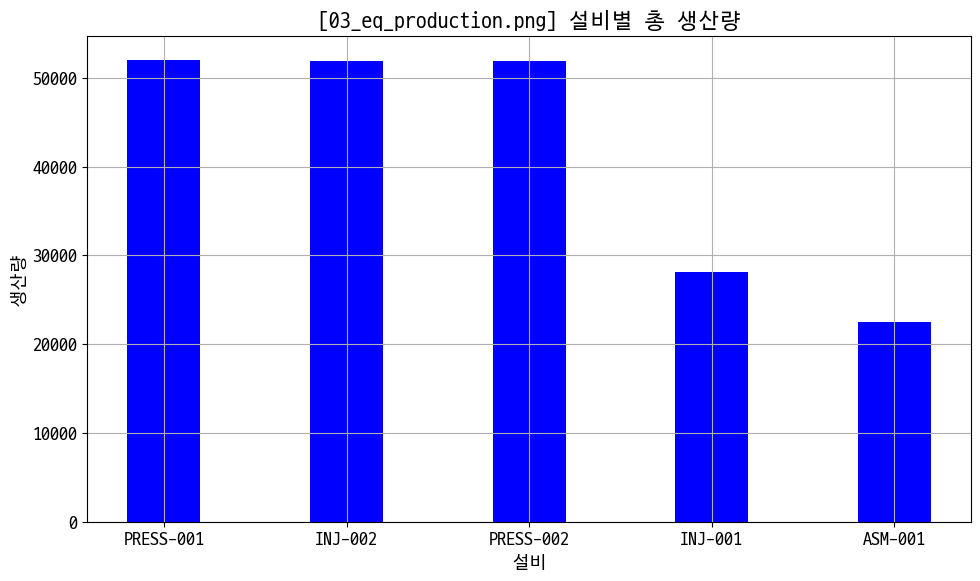
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 설비별 생산량
eq_prd = data_prd.groupby('equipment_id')['actual_quantity'].sum().sort_values(ascending=False)
figname = '03_eq_production.png'
plt.figure(figsize=(10, 6))
plt.barh(eq_prd.index, eq_prd.values, color='blue', height=0.4)
plt.title(f'[{figname}] 설비별 총 생산량')
plt.xlabel('설비')
plt.ylabel('생산량')
plt.grid()
plt.tight_layout()
plt.savefig(img_save + figname)
plt.show()
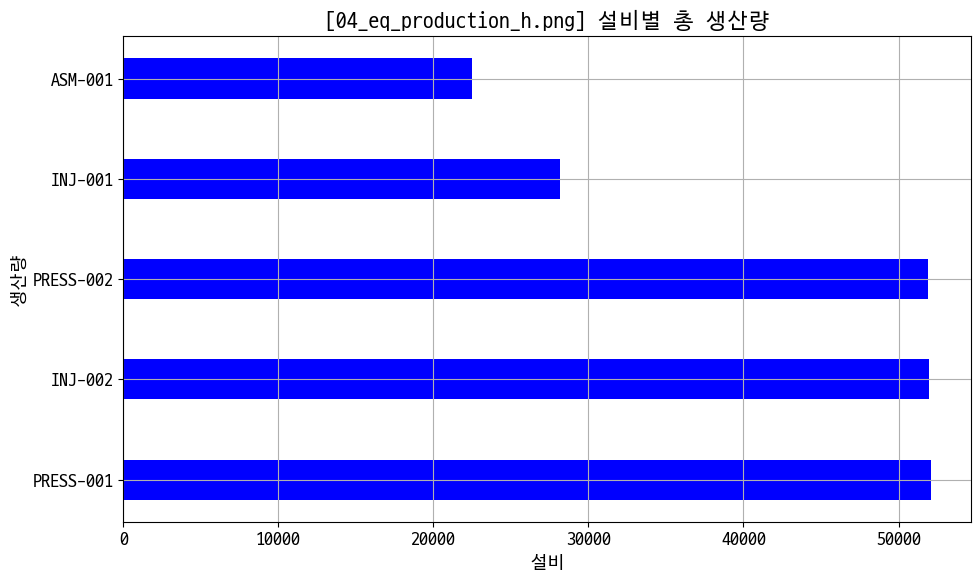
산점도
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
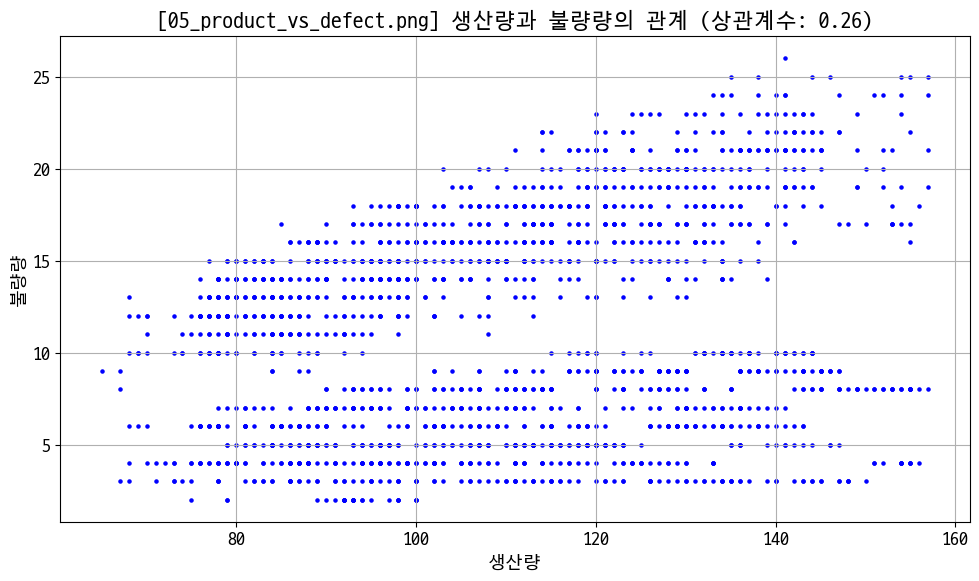
# 생산량 vs 불량 갯수
eq_prd = data_prd.groupby('equipment_id')['actual_quantity'].sum().sort_values(ascending=False)
corr = data_prd[['actual_quantity', 'defect_quantity']].corr().iloc[0, 1]
figname = '05_product_vs_defect.png'
plt.figure(figsize=(10, 6))
plt.scatter(data_prd['actual_quantity'], data_prd['defect_quantity'], color='blue', s=5)
plt.title(f'[{figname}] 생산량과 불량량의 관계 (상관계수: {corr:.2f})')
plt.xlabel('생산량')
plt.ylabel('불량량')
plt.grid()
plt.tight_layout()
plt.savefig(img_save + figname)
plt.show()
히스토그램
1
2
3
4
5
6
7
8
9
10
11
12
13
14
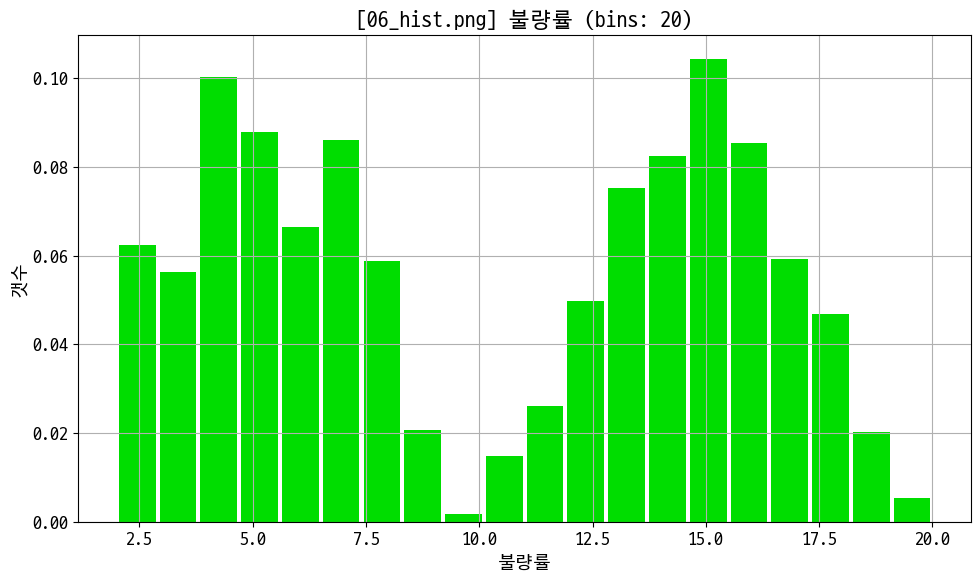
figname = '06_hist.png'
bins = 20
plt.figure(figsize=(10, 6))
plt.hist(data_prd['defect_rate'], bins=bins, color='#00DD00', rwidth=0.9, density=True)
# plt.hist(data_prd['defect_rate'], bins=np.arange(2, 20.5, 1), color='grey', alpha=0.4, rwidth=0.9, density=True) # bins 수동 지정 가능
plt.title(f'[{figname}] 불량률 (bins: {bins})')
plt.xlabel('불량률')
plt.ylabel('갯수')
plt.grid()
plt.tight_layout()
plt.savefig(img_save + figname)
plt.show()
파이차트
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
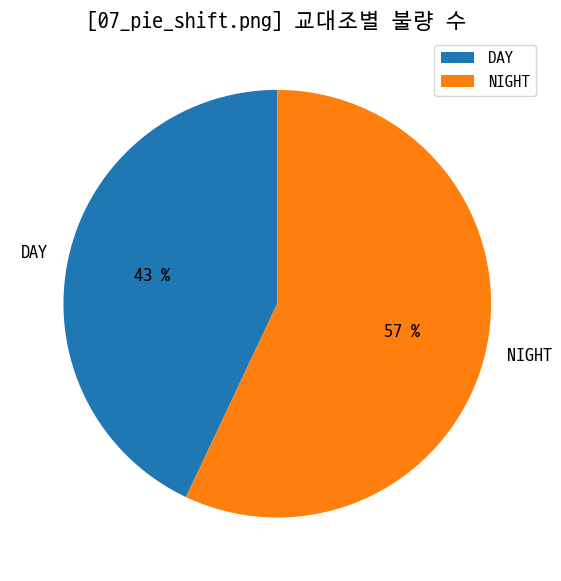
pie = data_prd.groupby('shift')['defect_quantity'].sum()
figname = '07_pie_shift.png'
plt.figure(figsize=(10, 6))
plt.pie(pie, startangle=90, labels=pie.index, autopct='%.0f %%')
plt.title(f'[{figname}] 교대조별 불량 수')
plt.xlabel('')
plt.ylabel('')
plt.grid()
plt.tight_layout()
plt.legend()
plt.savefig(img_save + figname)
plt.show()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
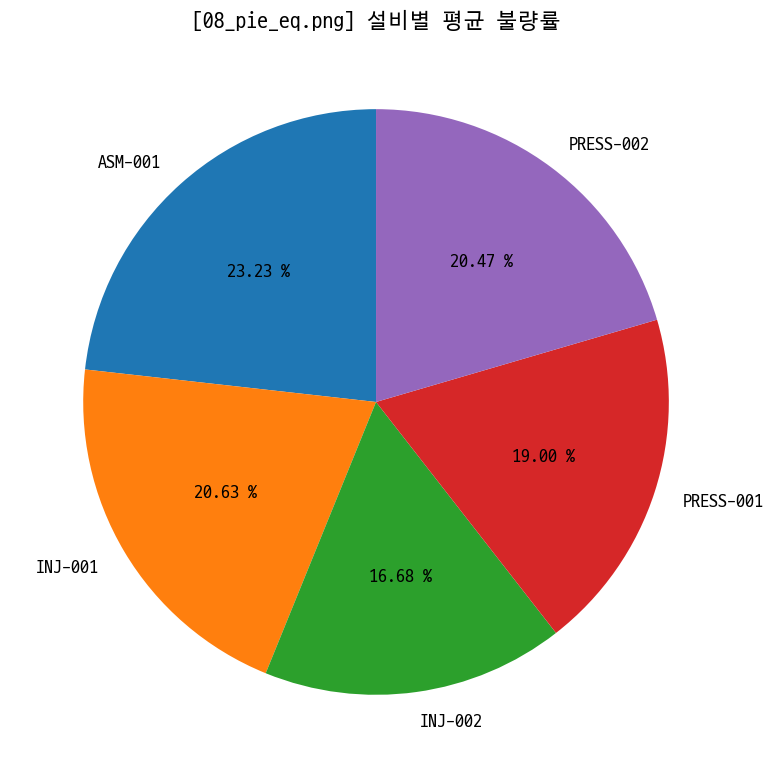
pie = data_prd.groupby('equipment_id')['defect_rate'].mean()
figname = '08_pie_eq.png'
plt.figure(figsize=(8, 8))
plt.pie(pie, startangle=90, labels=pie.index, autopct='%.2f %%')
plt.title(f'[{figname}] 설비별 평균 불량률')
plt.xlabel('')
plt.ylabel('')
plt.grid()
plt.tight_layout()
plt.savefig(img_save + figname)
plt.show()
실습 문제 풀이함
직접 풀고 cursor랑 리팩토링했음: 260211_06_matplotlib_basic_practice.html