덤
- 내가 한번 신경써서 스크롤 길이를 줄여봤습니다 양해하세요
- 정리가 많이 성의없는 거 저도 압니다 그렇기 때문에 공개하는 진짜 처음(사실 아님) 공부할 때 쓴 성의있는 정리들
- 넘파이 기초: https://www.kaggle.com/code/dapin1490/adpy-w10-note
- 넘파이 그래프: https://www.kaggle.com/code/dapin1490/adpy-w11-note
- 판다스 기초: https://www.kaggle.com/code/dapin1490/adpy-w12-note
- 판다스 기초+: https://www.kaggle.com/code/dapin1490/adpy-w13-note
- Scipy: https://www.kaggle.com/code/dapin1490/adpy-w14-note
- 위에 있는 걸 다 모아놓은 깃허브를 찾았어: dapin1490/study-note/3 - 1 note/advanced python/WEEK LIST.md at main
- 읽어
- 더북(TheBook) 모두의 데이터 분석 with 파이썬: UNIT 15 테이블 형태의 데이터를 쉽게 다루도록 도와주는 pandas 라이브러리
- 내가 판다스 처음 쓰기 시작할 때부터 AI 쓰기 전까지 매번 보던 거 있거든요 읽어: 한 권으로 끝내는 <판다스 노트>
요약
- 함수
- 기본형(인자→출력) : 인자 받아서 출력 (
def,print) - 반환 : 인자 받고
return· 인자 받고 분기 후return(예: Pass/Fail) - 여러 개 인자/반환 : 딕셔너리 패킹, 튜플 언패킹
- 가변 인자
*args: 갯수 제한 없이 - 가변 인자
**kwargs: 이름 있는 인자 - 람다·삼항 :
lambda a, b: a + b· 삼항 연산자(한 줄 if) 예:lambda x: x+1 if x%2==1 else x - numpy
- 배열 생성 :
np.array(), 정수/float 혼합, 다차원 배열 - 빈 배열(0 채움) 생성 :
np.zeros(),np.zeros((2,5)),dtype=int·np.empty(),np.zeros_like() - 구간·등간격 배열 :
np.arange(10),np.arange(10, 20, 2)·np.linspace(0, 10, 5),endpoint=False,retstep=True - 난수 생성 :
np.random.seed(),np.random.rand(),np.random.randint(),np.random.normal(평균, 표준편차) - 난수 순서·추출 :
np.random.shuffle(),np.random.choice() - 단위행렬·대각행렬 :
np.eye(),np.diag()· dtype 확인/지정,np.info() - 인덱싱·슬라이싱 :
temp[0],temp[0,0],temp[:,0],temp[0:1,0:1] - 논리(불리언) 인덱싱 :
temp[temp>=5],&|~ - 부분 대입·nan 처리 :
temp[1,0:2]=45.1, 조건부 대입 →np.nan·np.isnan(), nan 평균으로 채우기 - 모양 변경 :
reshape(4,6),order='F',reshape(2,2,-1) - 사칙·수학 함수 : 사칙연산
+ - * / // % **,np.sqrt,np.exp,np.log/log10/log2,np.sin/cos/tan - 기본 통계 :
np.min/max(axis=0/1),argmax/argmin,np.sum(조건),mean/median/std/var/prod - 누적·차분·정렬 :
np.cumsum/cumprod,np.diff,np.sort(axis=0/None) - 사분위수 :
np.quantile,np.percentile - 이상치(IQR) : Q1, Q3, lower_bound/upper_bound, 클리핑(경계값으로 대체)
- pandas
- Series 생성·인덱스 :
pd.Series(),.index,.values, 인덱스 지정index=['a','b',...], 인덱스로 접근·수정 - DataFrame 생성·속성 :
pd.DataFrame(),.index,.columns,.values - dict→DataFrame·전치 :
pd.DataFrame(data=...),.T(전치) - 요약·정보 :
describe(include='all'),info() - 컬럼·행 접근 :
temp["equipment_type"],temp.loc["INJ-001"] - 실습 데이터 참고 : smart-practice
test.py/ equipment_data
함수
함수는,, 희생과 봉사정신으로 만드는 거다,, (내 의견 아님 강사님 의견임)
-
기본형: 인자 받아서 뭔가 하기
1 2 3 4 5
def greet(name): print(f"Greetings, {name}.") greet("Dale Vandermeer") greet("Harvey")
-
인자 받고 돌려보내기
1 2 3 4
def add(a, b): return a + b print(add(345, 3458967))
-
인자 받고 뭔가 하고 돌려보내기
1 2 3 4 5 6 7 8
def get_status(score): if score >= 60: return "Pass" else: return "Fail" print(get_status(59)) print(get_status(60))
-
여러 개 받거나 여러 개 돌려주기
1 2 3 4 5 6 7 8 9 10 11 12 13 14
def packing(id, name, age): return {"id": id, "name": name, "age": age} def unpacking(person): return person['id'], person['name'], person['age'] dale = packing(1, "Dale Vandermeer", 42) print(dale) print(unpacking(dale)) ''' {'id': 1, 'name': 'Dale Vandermeer', 'age': 42} (1, 'Dale Vandermeer', 42) '''
-
가변 인자 1: 파라미터를 갯수 제한 없이 보낼 수 있음
1 2 3 4 5 6
# 가변 인자: 갯수 제한 없이 보낼 수 있음 def total(*args): return sum(args) print(total(1, 2, 3, 4, 5)) print(total(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
-
가변 인자 2: 함수에 정의되지 않은 파라미터는 직접 이름을 정해서 보낼 수 있음
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
# 가변 인자: 함수에 정의되지 않은 파라미터는 직접 이름을 정해서 보낼 수 있음 def many_params(first, second, third, **kwargs): print(f"First: {first}") print(f"Second: {second}") print(f"Third: {third}") print(f"Kwargs: {kwargs}") many_params(1, 2, 3, fourth=4, fifth=5) ''' First: 1 Second: 2 Third: 3 Kwargs: {'fourth': 4, 'fifth': 5} '''
-
람다: 함수를 간단하게 표현할 수 있음
1 2 3 4 5 6 7
add = lambda a, b: a + b print(add(345, 3458967)) # 3459312 # 덤: 한 줄 if 넣는 걸 삼항 연산자라고 함 make_even = lambda x : x + 1 if x % 2 == 1 else x print(make_even(3)) # 4 print(make_even(4)) # 4
numpy
이 항목에 있는 모든 함수를 다 설명했는가 하면 그건 아님 cursor가 추천해주는 함수도 다 썼을 뿐임
넘파이는 이게 근본이다
1
import numpy as np
-
넘파이 기본 배열은 정수도 먹고 float도 먹는다
1 2 3 4 5 6
np.array(range(10)), np.array(range(10)) / 2 ''' (array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]), array([0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5])) '''
-
다차원 넘파이
1 2 3 4 5 6 7 8 9 10
temp = [[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]] temp = np.array(temp) print(temp) ''' array([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]]) '''
-
모양 확인, 타입 지정
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
print(np.zeros(10)) print(np.zeros(10).shape, '\n') print(np.zeros((2, 5))) print(np.zeros((2, 5)).shape, '\n') print(np.zeros((2, 5), dtype=int)) print(np.zeros((2, 5), dtype=int).shape) ''' [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] (10,) [[0. 0. 0. 0. 0.] [0. 0. 0. 0. 0.]] (2, 5) [[0 0 0 0 0] [0 0 0 0 0]] (2, 5) '''
쓰레기 한 바가지만 주세요
1
np.empty((2, 6))
-
저거랑 똑같은 거 새로 주세요
1 2 3 4 5 6 7 8 9 10 11 12
temp = np.array([[1., 2., 3.], [4., 5., 6.]]) temp2 = np.zeros_like(temp) print(temp) print(temp2) ''' [[1. 2. 3.] [4. 5. 6.]] [[0. 0. 0.] [0. 0. 0.]] '''
-
여기부터 저기까지 다 주세요
1 2 3 4 5 6 7 8 9 10 11
print(np.arange(10)) print(np.arange(10, 20)) print(np.arange(10, 20, 2)) print(np.arange(10, 20, 2, dtype=float)) ''' [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [10 12 14 16 18] [10. 12. 14. 16. 18.] '''
-
여기부터 저기까지 이만큼만 주세요
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
print(np.linspace(0, 10, 5)) print(np.linspace(0, 10, 5, endpoint=False)) print(np.linspace(0, 10, 5, retstep=True)) print(np.linspace(0, 10, 5, dtype=int)) print(np.linspace(0, 10, 5, dtype=float)) print(np.linspace(0, 10, 5, dtype=complex)) ''' [ 0. 2.5 5. 7.5 10. ] [0. 2. 4. 6. 8.] (array([ 0. , 2.5, 5. , 7.5, 10. ]), np.float64(2.5)) [ 0 2 5 7 10] [ 0. 2.5 5. 7.5 10. ] [ 0. +0.j 2.5+0.j 5. +0.j 7.5+0.j 10. +0.j] '''
-
가챠는 이것만 돌려라
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
np.random.seed(42) # 모든 랜덤 배열이 똑같이 나온다 X, 난수의 순서가 매번 똑같다 O print(np.round(np.random.rand(2, 2), 2)) print(np.round(np.random.rand(2, 2), 2)) print(np.random.randint(1, 10, size=(2, 3))) print(np.random.randint(3, 100, (2, 5))) ''' [[0.37 0.95] [0.73 0.6 ]] [[0.16 0.16] [0.06 0.87]] [[4 8 8] [3 6 5]] [[ 4 90 32 40 4] [66 62 23 35 78]] '''
-
올바른 가챠
1 2 3 4 5 6 7 8 9
print(np.random.normal(0, 1, (2, 3))) # 표준정규분포 print(np.random.normal(170, 10, (2, 3))) # 평균 170, 표준편차 10 ''' [[ 0.1424646 -0.03465218 1.13433927] [-0.10474555 -0.52512285 1.91277127]] [[149.73280384 181.19423612 177.79192635] [158.98902244 181.30228194 173.73118915]] '''
-
섞어
1 2 3 4 5
temp = np.arange(10) np.random.shuffle(temp) print(temp) # >>> [2 8 4 1 0 9 6 5 7 3]
-
바꾸지 말고 뽑아줘(중복 있음)
1 2 3 4 5 6 7 8
temp = np.arange(10) print(np.random.choice(temp, temp.size)) print(temp) ''' [7 0 7 7 2 0 7 2 2 0] [0 1 2 3 4 5 6 7 8 9] '''
-
단위행렬
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
print(np.eye(2)) print(np.eye(2, 3)) print(np.eye(2, 3, k=1)) print(np.eye(2, 3, k=-1)) print(np.eye(2, 3, k=1, dtype=int)) print(np.eye(2, 3, k=1, dtype=float)) ''' [[1. 0.] [0. 1.]] [[1. 0. 0.] [0. 1. 0.]] [[0. 1. 0.] [0. 0. 1.]] [[0. 0. 0.] [1. 0. 0.]] [[0 1 0] [0 0 1]] [[0. 1. 0.] [0. 0. 1.]] '''
-
대각선으로 펴주세요
1 2 3 4 5 6 7
print(np.diag([1, 2, 3])) ''' [[1 0 0] [0 2 0] [0 0 3]] '''
-
데이터 타입 확인
1 2 3 4 5 6 7 8 9 10 11 12 13
print(np.array([1, 2, 3]).dtype) print(np.array([1, 2, 3], dtype=float).dtype) print(np.array([1, 2, 3], dtype=complex).dtype) print(np.array([1, 2, 3], dtype=str).dtype) print(np.array([1, 2, 3], dtype=bool).dtype) ''' int64 float64 complex128 <U1 bool '''
-
데이터 타입 변경
1 2 3 4 5 6 7 8 9 10 11
print(np.array([1, 2, 3], dtype=float)) print(np.array([1, 2, 3], dtype=complex)) print(np.array([1, 2, 3], dtype=str)) print(np.array([1, 2, 3], dtype=bool)) ''' [1. 2. 3.] [1.+0.j 2.+0.j 3.+0.j] ['1' '2' '3'] [ True True True] '''
-
--help1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# np.info(np.array) # 출력 생략 print(np.info(np.array([1, 2, 3, 4, 5]))) ''' class: ndarray shape: (5,) strides: (8,) itemsize: 8 aligned: True contiguous: True fortran: True data pointer: 0x1729a908010 byteorder: little byteswap: False type: int64 None '''
-
리스트 인덱싱 슬라이싱은 똑같이 적용 가능하나 전용 표현도 있긴 하다
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
temp = np.array([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]]) print(temp[0]) print(temp[0, 0]) print(temp[0, :]) print(temp[:, 0]) print(temp[0:1, 0:1]) print(temp[1, 0:2]) print(temp[0:2, 1]) ''' [1. 2. 3.] 1.0 [1. 2. 3.] [1. 4. 7.] [[1.]] [4. 5.] [2. 5.] '''
-
논리 연산 연좌제와 범인 색출
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
temp = np.array([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]]) print(temp >= 5) print() print(temp[temp >= 5]) print() print(temp[temp % 2 == 0]) print() print(temp[~(temp % 2 == 0)]) print() print(temp[(temp % 2 == 0) & (temp > 5)]) print() print(temp[(temp % 2 == 0) | (temp > 5)]) ''' [[False False False] [False True True] [ True True True]] [5. 6. 7. 8. 9.] [2. 4. 6. 8.] [1. 3. 5. 7. 9.] [6. 8.] [2. 4. 6. 7. 8. 9.] '''
-
이만큼 바꿔
1 2 3 4 5 6 7 8 9 10 11 12 13 14
temp = np.array([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]]) print(temp) temp[1, 0:2] = 45.1 print(temp) ''' [[1. 2. 3.] [4. 5. 6.] [7. 8. 9.]] [[ 1. 2. 3. ] [45.1 45.1 6. ] [ 7. 8. 9. ]] '''
-
이런 것들만 바꿔
1 2 3 4 5 6 7 8 9 10 11 12 13 14
temp = np.array([[1., 2., 3.], [4., 5., 6.], [7., 8., 9.]]) print(temp) temp[(temp >= 7) | (temp <= 3)] = None print(temp) ''' [[1. 2. 3.] [4. 5. 6.] [7. 8. 9.]] [[nan nan nan] [ 4. 5. 6.] [nan nan nan]] '''
1 2 3 4 5 6 7 8 9 10
temp = np.random.randint(1, 100, (20)) print(temp) temp[(temp > 85) | (temp < 25)] = 0 print(temp) ''' [79 15 90 42 77 51 63 96 52 96 4 94 23 15 43 29 36 13 32 71] [79 0 0 42 77 51 63 0 52 0 0 0 0 0 43 29 36 0 32 71] '''
-
np.nan은 float다 + nan은 확인 가능하다
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
temp = np.random.randint(1, 100, (20)) temp = temp.astype(float) print(temp) temp[(temp > 85) | (temp < 25)] = np.nan print(temp) print(np.isnan(temp)) ''' [99. 50. 25. 24. 13. 60. 7. 57. 36. 45. 20. 65. 8. 16. 14. 76. 87. 15. 1. 98.] [nan 50. 25. nan nan 60. nan 57. 36. 45. nan 65. nan nan nan 76. nan nan nan nan] [ True False False True True False True False False False True False True True True False True True True True] '''
-
nan 기피 현상
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
temp = np.array([66., 32., np.nan, 63., np.nan, 51., 25., 58., 63., 62., np.nan, 58., 58., np.nan, 49., 52., 42., 70., np.nan, 54.]) print(f'before\n{temp}\n') mean = np.round(np.mean(temp[~np.isnan(temp)]), 2) print(f'mean\n{mean}\n') temp[np.isnan(temp)] = mean print(f'after\n{temp}\n') ''' before [66. 32. nan 63. nan 51. 25. 58. 63. 62. nan 58. 58. nan 49. 52. 42. 70. nan 54.] mean 53.53 after [66. 32. 53.53 63. 53.53 51. 25. 58. 63. 62. 53.53 58. 58. 53.53 49. 52. 42. 70. 53.53 54. ] '''
-
모양 바꿔
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43
temp = np.random.randint(1, 100, (2 ** 3 * 3)) print(f'original\n{temp}\n') temp = temp.reshape(4, 6) # 가로로 분배하기 print(f'reshape (4, 6)\n{temp}\n') temp = temp.reshape(3, 8, order='F') # 세로로 분배하기 print(f'reshape (3, 8)\n{temp}\n') temp = temp.reshape(2, 3, 4) print(f'reshape (2, 3, 4)\n{temp}\n') temp = temp.reshape(2, 2, -1) print(f'reshape (2, 2, -1)\n{temp}\n') ''' original [46 88 11 62 77 98 25 71 52 4 59 72 20 93 63 54 74 98 57 90 41 3 6 5] reshape (4, 6) [[46 88 11 62 77 98] [25 71 52 4 59 72] [20 93 63 54 74 98] [57 90 41 3 6 5]] reshape (3, 8) [[46 57 93 52 62 3 74 72] [25 88 90 63 4 77 6 98] [20 71 11 41 54 59 98 5]] reshape (2, 3, 4) [[[46 57 93 52] [62 3 74 72] [25 88 90 63]] [[ 4 77 6 98] [20 71 11 41] [54 59 98 5]]] reshape (2, 2, -1) [[[46 57 93 52 62 3] [74 72 25 88 90 63]] [[ 4 77 6 98 20 71] [11 41 54 59 98 5]]] '''
-
사칙연산 연좌제
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
temp = np.arange(1, 6+1).reshape(2, 3) print(f'original\n{temp}\n') print(f'add 5\n{temp + 5}\n') print(f'sub 5\n{temp - 5}\n') print(f'multi 3\n{temp * 3}\n') print(f'div 3\n{temp / 3}\n') print(f'floor_div 2\n{temp // 2}\n') print(f'mod 2\n{temp % 2}\n') print(f'pow 2\n{temp ** 2}\n') print(f'sqrt\n{np.sqrt(temp)}\n') print(f'exp\n{np.exp(temp)}\n') print(f'log\n{np.log(temp)}\n') print(f'log10\n{np.log10(temp)}\n') print(f'log2\n{np.log2(temp)}\n') print(f'sin\n{np.sin(temp)}\n') print(f'cos\n{np.cos(temp)}\n') print(f'tan\n{np.tan(temp)}\n') # 출력 생략 # 직접 실행하세요
-
기본 통계
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
temp = np.random.randint(0, 100+1, (4, 5)) print(f'original\n{temp}\n') # 원본 print(f'min: {np.min(temp)}') # 최소값 print(f'max: {np.max(temp)}') # 최대값 print(f'min (axis=1): {np.min(temp, axis=1)}') # 행 별 최소값 print(f'min (axis=0): {np.min(temp, axis=0)}') # 열 별 최소값 print(f'max (axis=1): {np.max(temp, axis=1)}') # 행 별 최대값 print(f'argmax: {np.argmax(temp)}') # 최대값 인덱스 print(f'argmin: {np.argmin(temp)}') # 최소값 인덱스 ''' original [[46 67 75 44 1] [26 94 35 35 25] [42 26 68 19 10] [73 37 5 71 22]] min: 1 max: 94 min (axis=1): [ 1 25 10 5] min (axis=0): [26 26 5 19 1] max (axis=1): [75 94 68 73] argmax: 6 argmin: 4 '''
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
temp = np.random.randint(0, 100+1, (4, 5)) print(f'original\n{temp}\n') # 원본 print(f'num of >50: {np.sum(temp > 50)}') # 50 이상 개수 print(f'mean: {np.mean(temp)}') # 평균 print(f'median: {np.median(temp)}') # 중간값 print(f'std: {np.std(temp)}') # 표준편차 print(f'var: {np.var(temp)}') # 분산 print(f'sum: {np.sum(temp)}') # 합계 print(f'prod: {np.prod(temp)}') # 곱계 ''' original [[93 86 50 55 82] [61 31 29 28 48] [44 92 29 15 39] [18 17 0 77 46]] num of >50: 7 mean: 47.0 median: 45.0 std: 26.80485030736042 var: 718.5 sum: 940 prod: 0 '''
1 2 3 4 5 6 7 8 9 10 11 12
temp = np.random.randint(0, 100+1, (4, 5)) print(f'original\n{temp}\n') # 원본 print(f'cumsum\n{np.cumsum(temp)}\n') # 누적합 print(f'cumprod\n{np.cumprod(temp)}\n') # 누적곱 print(f'diff\n{np.diff(temp)}\n') # 차분 print(f'sort (default)\n{np.sort(temp)}\n') # 행마다 정렬 print(f'sort (axis=0)\n{np.sort(temp, axis=0)}\n') # 열마다 정렬 print(f'sort (axis=None)\n{np.sort(temp, axis=None)}\n') # 전체 정렬 # 출력 생략 # 직접 보세요
-
사분위수
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
temp = np.random.randint(0, 100+1, (4, 5)) print(f'original\n{temp}\n') # 원본 print(f'quantile 0: {np.quantile(temp, 0)}') # 0% print(f'quantile 25: {np.quantile(temp, 0.25)}') # 25% print(f'quantile 50: {np.quantile(temp, 0.5)}') # 50% print(f'quantile 75: {np.quantile(temp, 0.75)}') # 75% print(f'quantile 100: {np.quantile(temp, 1)}') # 100% ''' original [[ 25 65 72 72 39] [ 16 0 88 60 42] [ 41 24 38 34 2] [100 43 50 93 97]] quantile 0: 0 quantile 25: 31.75 quantile 50: 42.5 quantile 75: 72.0 quantile 100: 100 '''
-
IQR 이상치 처리
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
temp = np.random.randint(0, 100+1, (4, 5)) temp2 = np.random.randint(150, 300+1, (1, 5)) temp3 = np.random.randint(-200, -50, (1, 5)) temp = np.concatenate([temp2, temp, temp3]) before = temp.copy() print(f'original\n{temp}\n') # 원본 # 이상치 탐지 IQR Q1 = np.percentile(temp, 25) Q3 = np.percentile(temp, 75) IQR = Q3 - Q1 lower_bound = Q1 - 1.5 * IQR upper_bound = Q3 + 1.5 * IQR print(f'Q1: {Q1}') print(f'Q3: {Q3}') print(f'IQR: {IQR}') print(f'lower_bound: {lower_bound}') print(f'upper_bound: {upper_bound}') # 이상치 처리 temp[temp < lower_bound] = lower_bound temp[temp > upper_bound] = upper_bound print(f'\nafter\n{temp}\n') # 이상치 처리 후 print(f'before == after\n{before == temp}\n') # 출력 생략
pandas
근본
1
import pandas as pd
-
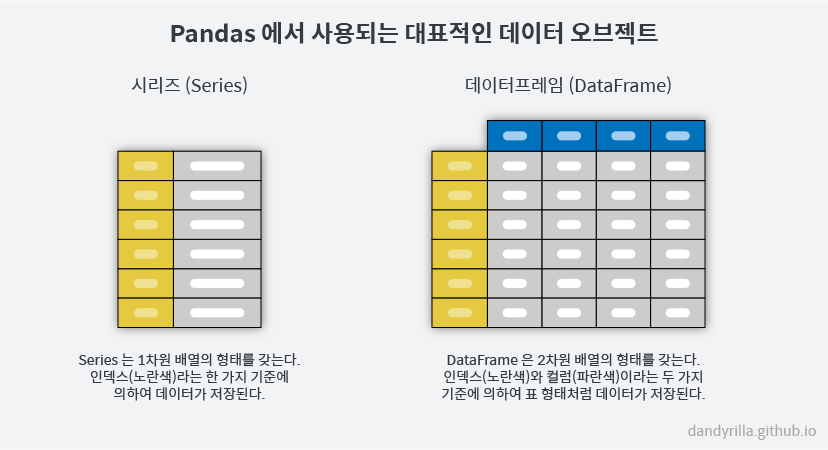
시리즈
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
temp = pd.Series(np.random.randint(0, 100+1, (5))) print(temp, "\n") print(temp.index, "\n") print(temp.values, "\n") ''' 0 97 1 69 2 85 3 10 4 15 dtype: int32 RangeIndex(start=0, stop=5, step=1) [97 69 85 10 15] '''
-
예쁜 인덱스 붙이기
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
temp = pd.Series(np.random.randint(0, 100+1, (5)), index=['a', 'b', 'c', 'd', 'e']) print(temp, "\n") print(temp.index) print(temp.index.to_list(), "\n") print(temp.values, "\n") ''' a 96 b 72 c 58 d 69 e 79 dtype: int32 Index(['a', 'b', 'c', 'd', 'e'], dtype='str') ['a', 'b', 'c', 'd', 'e'] [96 72 58 69 79] '''
- 넘파이에서 쓰던 기능은 다 쓸 수 있다~ (판다스가 넘파이를 wrapping했기 때문)
- 넘파이 파트 참고하세요
-
예쁜 인덱스 활용하기
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
temp = pd.Series(np.random.randint(1, 100+1, (5)), index=['a', 'b', 'c', 'd', 'e']) print(f'before\n{temp}\n') temp['a'] = temp['a'] ** 2 temp[['b', 'c']] = np.round(np.log(temp[['b', 'c']])) print(f'after\n{temp}\n') ''' before a 99 b 89 c 99 d 25 e 93 dtype: int32 after a 9801 b 4 c 5 d 25 e 93 dtype: int32 '''
-
시리즈 했으면 데이터프레임도 해야지
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
temp = pd.DataFrame(np.random.randint(0, 100+1, (4, 5))) print(temp, "\n") print(temp.index) print(temp.columns, "\n") print(temp.values, "\n") ''' 0 1 2 3 4 0 42 47 38 92 41 1 25 98 49 24 23 2 12 59 6 56 35 3 44 19 64 7 15 RangeIndex(start=0, stop=4, step=1) RangeIndex(start=0, stop=5, step=1) [[42 47 38 92 41] [25 98 49 24 23] [12 59 6 56 35] [44 19 64 7 15]] '''
데이터 이거 쓰세요
https://github.com/macro0630/smart-practice/blob/main/test.py
-
dict to DF
1 2 3
temp = pd.DataFrame(data = equipment_data) temp.T # 뒤집어도 됨
0 1 2 3 4 equipment_id INJ-001 INJ-002 PRESS-001 PRESS-002 ASM-001 equipment_name 사출기 1호기 사출기 2호기 프레스 1호기 프레스 2호기 조립라인 1호기 equipment_type 사출기 사출기 프레스 프레스 조립라인 location A동 1라인 A동 1라인 A동 2라인 A동 2라인 B동 1라인 rated_capacity 150 150 200 200 100 status ACTIVE ACTIVE ACTIVE ACTIVE ACTIVE -
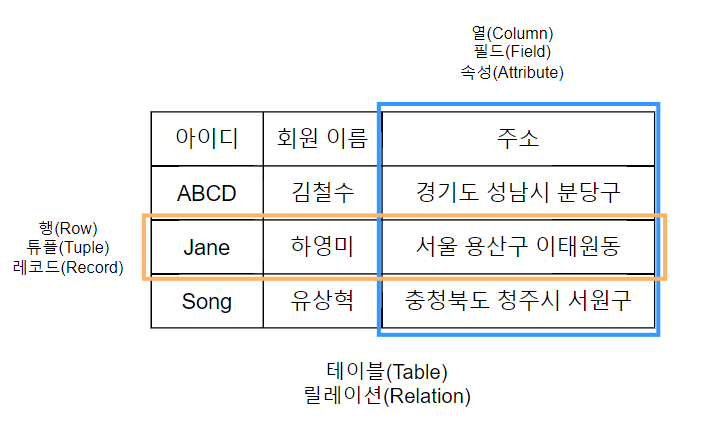
단어 외우세요
![]()
![]()
![]()
- 이해 안되면 보세요
-
헤이 판다스 데이터 요약해줘
1 2 3 4
temp = pd.DataFrame(data = equipment_data) # temp.describe(include='all').T # 뒤집어도 되는데 못생겨서 안뒤집겠음 temp.describe(include='all')
equipment_id equipment_name equipment_type location rated_capacity status count 5 5 5 5 5.000000 unique 5 5 3 3 NaN top INJ-001 사출기 1호기 사출기 A동 1라인 NaN freq 1 1 2 2 NaN mean NaN NaN NaN NaN 160.000000 std NaN NaN NaN NaN 41.833001 min NaN NaN NaN NaN 100.000000 25% NaN NaN NaN NaN 150.000000 50% NaN NaN NaN NaN 150.000000 75% NaN NaN NaN NaN 200.000000 max NaN NaN NaN NaN 200.000000 -
헤이 판다스 데이터 더 간단하게 요약해줘
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
temp = pd.DataFrame(data = equipment_data) temp.info() # 이건 뒤집는 거 아님 ''' <class 'pandas.DataFrame'> RangeIndex: 5 entries, 0 to 4 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 equipment_id 5 non-null str 1 equipment_name 5 non-null str 2 equipment_type 5 non-null str 3 location 5 non-null str 4 rated_capacity 5 non-null int64 5 status 5 non-null str dtypes: int64(1), str(5) memory usage: 372.0 bytes '''
-
데이터프레임은 인덱싱을 좀 다르게 해
- 그냥 인덱스 이름 쓰든가 → 보통 권장하지 않음
- loc으로 인덱스 이름 쓰든가
- iloc으로 숫자만 쓰든가
1 2 3 4 5 6 7 8 9 10 11 12
temp = pd.DataFrame(data = equipment_data, index=equipment_data['equipment_id']).drop(columns=['equipment_id']) print(f'temp["equipment_type"]\n{temp["equipment_type"]}\n') # 컬럼 직접 호출 print(f'temp.loc["INJ-001"]\n{temp.loc["INJ-001"]}\n') # 행 인덱스 이름으로 호출 print(f'temp.iloc[0]\n{temp.iloc[0]}\n') # 행 숫자 호출 print(f'temp.loc["INJ-001", "equipment_type"]\n{temp.loc["INJ-001", "equipment_type"]}\n') # 행, 열 지정 print(f'temp.iloc[0, 0]\n{temp.iloc[0, 0]}\n') # 행, 열 지정 print(f'temp.loc["INJ-001", :]\n{temp.loc["INJ-001", :]}\n') # 행, 열 범위 지정 print(f'temp.iloc[:, 0]\n{temp.iloc[:, 0]}\n') # 행, 열 범위 지정 # 출력 길어서 생략 # 그냥 뭐 필요해서 쓰다 보면 어떻게든 쓰게 됨 대충 보세요