
table of contents
전이학습
- 기존 머신러닝: task 맞춤 모델 제작, 어렵고 비싸다
- 전이학습: 남이 배워둔 거 재활용하기, 쉽고 빠름
- 남이 배워둔 거: 사전 학습, 근원 문제에 학습시킴
- 재활용: 미세 조정 fine tuning, 대상 문제에 학습시킴
- 이미지 처리는 일반적으로 비슷한 특징을 공유하기 때문에 전이학습이 잘 통함
- 보통 사전 학습보다 작은 학습률 사용
- 기초 모델: 넓은 종류의 분야에 적용할 수 있는 모델
- 비용도 줄고 모델 구축에 요구되는 전문성도 줄어서 진입장벽 낮아짐
- 튜닝 방식: 전체적으로 조정하기, 사전 학습 뒤에 분류기만 추가하기, 주는대로 쓰기
| 방법 | 데이터 | 과업의 종류 | 이미지 | 필요한 하드웨어 성능 |
|---|---|---|---|---|
| OpenCV 등으로 고정된 알고리즘 | 없음 | 단순 (직선, 원 찾기, 기하학적 변환) | 무관 | 낮음 |
| 직접 모델을 만들어 머신러닝/딥러닝 | 많음 | 중간 (이미지 분류) | 해상도 낮고 크기 작음 | 보통 |
| 기존의 모델을 전이 학습 | 적음 | 복잡 (탐지, 생성, 변환 등) | 해상도 높고 크기 큼 | 높음 |
허깅페이스 트랜스포머스
- 최신의 사전 학습된 트랜스포머 계통의 모형을 간편하게 사용할 수 있는 Python 라이브러리
- 모델 구축과 학습 과정을 건너 뛰고 바로 사용해볼 수 있음
- 자신의 데이터에 추가적으로 학습시켜 미세 조정하여 사용도 가능
- 설치:
pip install transformers[torch] datasets evaluate - 사용 시 액세스 토큰 필요
오토인코더
- 지도 학습: 레이블이 있는 학습
- 비지도 학습: 레이블이 없는 학습
- 이미지 압축: 이미지 파일의 크기를 줄이는 기술, 공간 절약 및 전송 속도 개선. GIF, JPG. 고정된 알고리즘으로 압축함.
- JPEG식 압축
- 색공간 변환(RGB → YCbCr): Y는 밝기, Cb, Cr은 색상.
- 크로마 서브샘플링(chroma subsampling): 사람은 밝기에 민감하므로 Y는 보존, Cb, Cr을 압축
- 인접한 픽셀에서 일부 색상만 남김
- 블록 분할(block splitting): 채널을 일정 크기(예: 8x8)의 블록으로 분할
- 이산 코사인 변환(discrete cosine transform): 각 블록의 이미지를 주파수로 변환
- 양자화(Quantization): 주파수 영역의 계수들을 상수로 나눈 후, 반올림
- 실수 → 정수로 바뀜
- 고주파 영역을 큰 상수로 나누어 압축율을 높임
- 일반적인 비손실 압축 알고리즘(Run-length encoding, Huffman coding 등)을 적용
- JPEG 압축 문제점: 이미지가 점점 풍화됨, 의미가 보존되지 않음
- 오토인코더
- 비지도 학습 기반 이미지 특성 압축
- 인코더(압축)와 디코더(압축해제)로 구성
- 원본과 압축 후 복원한 이미지의 차이를 줄이는 방향으로 학습, 레이블은 필요 없음
- 압축 이외의 활용도 가능: 노이즈 제거
이미지 임베딩
- 예를 들어 얼굴로 잠금 해제
- 화장 안했다고 잠금이 안풀리면 문제가 있다
- 그렇다고 사용자에게 사진 5천 장만 찍어달라고 할 수는 없다
- 그러므로 빠르게 특징을 추출하고 원본과 비교해서 판별할 수 있어야 한다
- 같은 사람을 찍은 사진에서는 유사한 특징, 다른 사람을 찍은 사진에서는 차이점을 학습하게 함.
- 임베딩
- 유사성을 보존하면서 원래보다 낮은 차원의 벡터로 표현하는 것또는 그렇게 표현된 벡터
- 개념적으로 일종의 디지털 지문. 임베딩을 비교하면 같은 대상에 대한 이미지인지 판별 가능. 딥러닝으로 생성됨.
- 임베딩의 필요성
- 고해상도 이미지는 데이터가 너무 많음. 의미를 잘 남기면서 줄여야 함.
- 임베딩 활용: DB에 저장된 얼굴 중 찾기, 일치 확인, 이미지 검색, 영상 내 동일 객체 구분 및 추적
- 임베딩 구현 방법: 교차 엔트로피 손실, 대조 손실, 삼중항 손실
- 교차 엔트로피 손실
- 이미지 분류 모형을 학습시킴
- 학습 후 예측 레이어를 뺀다
- 특징 추출 레이어를 출력으로 사용
- 해당 출력이 임베딩으로 사용됨
- 대조 손실
- 이미지 텍스트 등 다양한 도메인에서 효과적
- 긍정적 쌍(같은 사람 다른 사진)과 부정적 쌍(다른 사람 다른 사진)을 데이터로 학습함
- 이미지를 입력하면 임베딩을 출력하는 딥러닝 모델에게, 긍정적 쌍을 입력할 경우 임베딩이 비슷해지도록 하고, 부정적 쌍을 입력하면 임베딩이 달라지는 게 적절한 방향
- 결론적으로 같은 사람의 다른 사진과 다른 사람의 비슷한 사진을 구분해내게 되는 것
- 삼중항 손실
- 대조 손실의 확장. 비슷한 이미지 2개(a, p)와 다른 이미지 1개(n)를 같이 사용
- a가 n보다 p에 가깝게 출력하도록 학습
- 비슷한 정도와 다른 정도를 적절히 조절해야 모델이 똑바로 학습한다. 너무 쉽지도 어렵지도 않게 만들기.
- 임베딩과 오토 인코더
- 오토 인코더로 압축된 값을 임베딩으로 활용해도 되지만, 애초에 오토 인코더는 원본 이미지 복원이 목적이기 때문에 비슷한 이미지가 비슷한 임베딩을 갖는다는 장담 X, 학습 과정에서 이미지를 복원까지 하기 때문에 불필요한 연산.
- 대조학습은 비슷한 이미지와 다른 이미지를 명시적으로 비교해 임베딩 공간에 의미론적으로 유사한 이미지가 가까워지도록 함
- 코사인 유사도
- 두 벡터 간 유사성을 측정
- -1은 완전 반대, 0은 무관, 1은 완전 비슷함. [-1, 1]의 범위.
- 널리 사용됨
임베딩 검색
- Approximate Nearest Neighbor Search
- 유사도 검색은 시간이 오래걸림. 선형 탐색을 해도 그렇고 정렬을 해도 그렇다
- 인덱싱을 하면 검색이 좀 빨라짐
- ANN은 정확도를 약간 손해보고 속도를 살리는 방법
- Product Quantization
- 큰 실수 벡터를 작은 정수 벡터로 표현하는 방법
- 하나의 큰 벡터를 여러 개의 서브 벡터로 잘라 클러스터링하고, 클러스터 번호로 대체함
- 트리 기반 문서 검색
- 공간을 무작위로 분할해 트리를 만들고, 같은 트리에 있는 문서를 비슷한 문서로 간주
- 트리를 여러 개 만들어 포레스트 구성, 여러 트리를 합쳐서 비슷한 문서 파악
- 해시 기반 문서 검색
- 해시 함수: 데이터를 고정된 크기의 값으로 매핑하는 함수
- 랜덤 투영: 랜덤하게 만든 행렬을 곱하여 작은 차원으로 투영한다 → 축이 +면 1, -면 0으로 변환해 이진수로 만듦
- Locally Sensitive Hashing: 비슷한 데이터를 쉽게 찾기 위한 해싱 방법
- 비슷한 데이터는 비슷한 해시값을 갖도록 하는 방법을 여러 번 적용
- 하나라도 일치하면 비슷한 데이터로 판정
- 위계적 탐색가능한 작은 세상 네트워크
- Hierarchical Navigable Small Worlds Network
- 1960년대 심리학자 스탠리 밀그램의 실험: 멀리 떨어진 지역의 모르는 사람에게 편지를 전달 → 5~6단계만에 가능
- 위계적: 연결된 거리에 따라 단계적으로 구성
- 탐색 가능한: 네트워크의 전체 구조를 모르더라도 최대한 가까운 방향으로 이동하면 짧은 경로로 도달 가능
- 작은 세상 네트워크: 주로 가까운 점과 연결되어 있지만, 멀리 떨어진 점들과도 일정 비율 연결된 형태
- 벡터 데이터베이스
- 벡터 검색에 전문화된 DB
- AI 때문에 임베딩 검색이 중요해지면서 같이 주가상승
- 종류는 다양함
- 기능
- 데이터 관리: 데이터 삽입, 삭제 및 업데이트 등 벡터 데이터를 쉽게 관리하고 유지
- 메타데이터: 각 벡터 항목과 관련된 메타데이터를 저장/검색
- 확장성: 데이터 볼륨과 사용자 요구에 따라 확장, 분산 및 병렬 처리
- 실시간 업데이트: 실시간 데이터 업데이트, 데이터 동적 변경
- 백업
- 에코시스템: ETL, 분석도구, 시각화 플랫폼, 다른 AI 도구등과 쉽게 통합
- 데이터 보안 및 접근 제어
OCR
- 과정
- 이미지 전처리
- 텍스트 위치 추정 → 문자 분리, 텍스트 추출 → 문자 인식
- 후처리
- 색, 크기, 방향 다양성으로 텍스트 추출 어려움
- 다만 문자의 종류는 제한되기 때문에 데이터 공간은 유한함
- 오픈소스로 해결 가능
PaddleOCR
- 중국산 딥러닝 OCR
- 한국어 포함 80개 언어 가능
- 성능 굿
!pip install paddlepaddle paddleocr
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from paddleocr import PaddleOCR
import paddlex.utils.fonts
ocr = PaddleOCR(
use_doc_orientation_classify=False, # 문서 방향 분류 사용 안 함
use_doc_unwarping=False, # 문서 왜곡 보정 사용 안 함
use_textline_orientation=False, # 텍스트 라인 방향 분류 사용 안 함
lang='korean', # 언어: 한국어 (영어는 'en')
# ocr_version="PP-OCRv4",
enable_mkldnn=False, # prevents MKLDNN/PIR crash
)
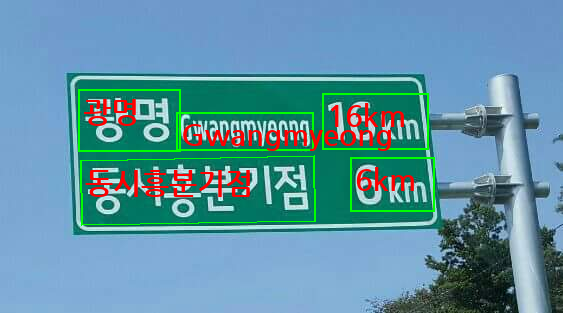
result = ocr.predict(input="data/sign.jpg")
res = result[0] # 첫 번째 이미지 결과
print(res['rec_texts']) # 인식된 텍스트
print(res['rec_polys']) # 텍스트별 폴리곤(다각형)의 꼭지점 좌표
print(res['rec_boxes']) # 텍스트별 박스의 왼쪽 위, 오른쪽 아래 꼭지점 좌표
temp = paddlex.utils.fonts.Font(font_name="NanumGothic.ttf", local_path=r'c:\USERS\RAPA\APPDATA\LOCAL\MICROSOFT\WINDOWS\FONTS\NanumGothicBold.TTF')
res['vis_fonts'] = [temp] * len(res['vis_fonts']) # 시각화에 사용할 글꼴 리스트
print(res['vis_fonts'][0].path)
res.save_to_img("res")

수제 출력
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from PIL import Image, ImageDraw, ImageFont
try:
# 한글 출력을 위해 나눔고딕과 같은 한글 폰트가 필요합니다.
font = ImageFont.truetype(r'C:\Users\RAPA\AppData\Local\Microsoft\Windows\Fonts\NanumGothicBold.ttf', 30)
except IOError:
print("NanumGothic.ttf 폰트를 찾을 수 없습니다. 기본 폰트를 사용합니다.")
font = ImageFont.load_default()
img = Image.open('data/sign.jpg').convert("RGB")
draw = ImageDraw.Draw(img)
for text, poly in zip(res['rec_texts'], res['rec_polys']):
# 텍스트를 감싸는 다각형(폴리곤)을 파란색으로 그립니다.
# PIL의 polygon은 (x1,y1), (x2,y2)... 형태의 튜플 리스트를 인자로 받습니다.
draw.polygon([tuple(p) for p in poly], outline="#00FF00", width=2)
# 인식된 텍스트를 폴리곤의 첫 번째 꼭짓점 위치에 빨간색으로 씁니다.
# 텍스트가 박스 안쪽에 그려지도록 위치를 약간 조정할 수 있습니다.
text_position = tuple(poly[0])
draw.text((text_position[0] + 5, text_position[1] + 5), text, fill="#FF0000", font=font)
display(img)
물체 탐지
- 하나의 이미지 안에 다수의 클래스
- 위치도 잘 찾고 클래스도 잘 구분해야 해서 어려움
- 자율주행, 보안, 안전, 의료 등 쓸 데는 많음
- 예전엔 피처와 그래디언트 등을 이용해서 탐지했지만 요즘엔 그냥 딥러닝 먹인다
Two-stage Detector (2단계 탐지기)
- 후보 영역을 고르고 나서 영역 분류 및 바운딩 박스 회귀를 하는 모델
- R-CNN이 대표적
- Selective Search Algorithm을 이용해 ROI를 추출
- 후보 영역을 추출 → 영역끼리 유사도를 계산 → 비슷한 후보 영역을 합침
- 유사도를 재계산, 이하 반복
- 추출된 이미지를 CNN에 입력하여 분류
- R-CNN은 문제가 많음
- 느림
- 느리고 불필요한 영역까지 추출함
- 처리 과정이 다단계임
- 계산도 많이 함
- 발전해봤자 거기서 거기임
One-stage Detector (1단계 탐지기)
- 단일 네트워크에서 한번에 위치와 클래스를 예측하자
- YOLO와 SSD가 대표적
- 빠르고 실시간 응용에 적합
YOLO
- 입력 이미지가 CNN 통과 후 특징 맵 생성
- 특징 맵을 그리드 셀로 분할
- 각 그리드 셀에서 바운딩 박스 예측
- 각 박스에 대해 좌표와 객체 신뢰도, 클래스 확률 예측
SSD
- 영역 제안과 물체 분류를 동시에 하자
- 전이학습 후 피처 맵에서 아주 많은 경계 상자 예측, 큰 물체일수록 후반부에서 예측
DETR
- CNN 백본 + 트랜스포머 + 앞먹임 신경망 구성
- CNN → 피처 맵 → 트랜스포머 인코더
- N개의 물체가 있다고 치고 인코더에 질의, 각 물체에 대한 클래스와 박스 출력
Non-Maximum Suppression (NMS)
- 동일 물체가 여러 번 탐지되기도 하잖아 → 가장 확률이 높은 박스 선택
- 선택된 박스와 일정 이상 겹치는 박스는 지워
YOLO
install and import
pip install ultralytics
1
2
3
import ultralytics
ultralytics.checks()
COCO dataset and YOLO
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
from ultralytics import YOLO # 임포트
from PIL import Image, ImageDraw, ImageFont
import cv2 as cv
model = YOLO("res/yolo26m.pt") # size: n, s, m, l, x
# 이미지 파일에 적용
results = model('data/bus_stop.jpg')
# OpenCV에서 파일을 불러들여서 모델에 적용하는 방법
img = cv.imread("data/bus_stop.jpg") # OpenCV로 파일 열기
results = model(img) # 이미지에 모델 적용
# 일정 수준 이상의 확률을 가진 물체만 탐지하는 방법
results = model(img, conf=0.8) # 확률 80% 이상인 물체만 탐지
# 결과 출력 (바운딩 박스, 클래스, 신뢰도)
for r in results:
print(r.boxes.xyxy) # 바운딩 박스 좌표
print(r.boxes.cls) # 클래스 ID
print(r.boxes.conf) # 신뢰도 = 물체의 확률 × 상자의 정확도
# 글꼴 설정: 같은 폴더에 ttf 글꼴 파일이 있어야 함. 없으면 기본 글꼴 사용
try:
font = ImageFont.truetype("NanumGothic.ttf", 20)
except IOError:
font = ImageFont.load_default()
# 결과를 그릴 새 이미지 만듦
img_bbox = Image.fromarray(cv.cvtColor(img, cv.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_bbox)
# 결과
result = results[0] # 이미지가 하나이므로 결과도 하나
boxes = result.boxes # 모든 경계상자의 정보
for i, box in enumerate(boxes): # 모든 경계 상자에 다음의 작업을 수행
xyxy = box.xyxy[0].cpu().numpy() # 좌표값 (x1, y1, x2, y2)
cls_id = int(box.cls[0].cpu().numpy()) # 클래스 ID
confidence = float(box.conf[0].cpu().numpy()) # 확률
x1, y1, x2, y2 = xyxy.astype(int) # 좌표값 언패킹
draw.rectangle([x1, y1, x2, y2], outline="#00FF00", width=3) # 초록색 경계 상자
label = f"{result.names[cls_id]}({confidence:.2f})" # 클래스 이름 및 신뢰도
draw.text((x1, y1), label, fill="#00FF00", font=font) # 볼드체로 레이블 쓰기
# display(img_bbox) # 결과 보기
array = results[0].plot()
Image.fromarray(array[:, :, ::-1]) # 이게 더 잘보임

물체 탐지의 평가
- 경계 상자의 정확도 IOU: 교집합 / 합집합
- 두 경계 상자가 이루는 합집합 면적 중 교집합 면적의 비율
- 자카드 유사도라고도 함
- 클래스의 정확도
- PR커브: 가로축이 재현율, 세로축이 정밀도
- AP: PR커브 아래의 면적. 모든 재현율에서 정밀도의 평균과 같음
- mAP: 모든 종류의 물체의 AP 평균, 가장 많이 쓰는 지표임
- mAP 50: IOU 임계값 0.5 이상일 때 mAP
- mAP 50-95: IOU 임계값을 0.5부터 0.95까지 0.05씩 높이면서 mAP를 구하고 평균
각 지표별 그래프는 다 합쳐서 그리면 이렇게 생김
![image.png]()
물체 탐지 데이터셋 만들기
수제 데이터로 튜닝하기
LabelStudio에서 수제 데이터 빚으면 되는데 그 과정은 생략
아래 코드는 그 데이터로 미세 조정(튜닝)한 거임
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
from ultralytics import YOLO
model = YOLO("res/yolo26m.pt")
model.train(
data="data/clip/clip_labeled/data.yaml",
epochs=100, # 데이터가 적으므로 충분한 학습 횟수 필요
# imgsz=640,
# 기하학적 증강: 클립은 어느 방향에서든 놓일 수 있으므로 회전과 반전 강화
degrees=180.0, # 모든 각도 회전 허용
flipud=0.5, # 상하 반전 활성화
fliplr=0.5, # 좌우 반전 활성화
# 색상 증강: 바닥의 밝기나 클립의 색상 변이에 대응
hsv_h=0.015,
hsv_s=0.7,
hsv_v=0.4,
# 복합 증강: 데이터 부족 문제 해결을 위해 필수
mosaic=1.0, # 기본 활성화 유지
copy_paste=0.3, # 객체 인스턴스를 무작위로 복사하여 데이터 밀도 증가
mixup=0.1 # 과적합 방지를 위해 약간 가미
)
튜닝 모델 예측시키기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from torchvision import transforms
best_model_path = "runs/detect/train/weights/best.pt"
text_image_route = r'data\clip\clip04.jpg'
model = YOLO(best_model_path)
# 테스트용 이미지 변형: flip or rotate
img = cv.imread(text_image_route)
img = cv.flip(img, 1) # 좌우 반전
img = cv.bitwise_not(img) # 색 반전
transform = transforms.ColorJitter(brightness=.5, hue=.5, contrast=.5, saturation=.5) # 밝기, 색조, 명암, 채도 조절
img = transform(Image.fromarray(cv.cvtColor(img, cv.COLOR_BGR2RGB)))
results = model(img) # 모델 적용
array = results[0].plot()
Image.fromarray(array[:, :, ::-1])

OBB
- 위의 물체 탐지는 무조건 정방향 사각형으로만 탐지함. 근데 물체가 사선으로 있으면 낭비되는 공간이 너무 많잖아. 그래서 나타났다 기울어진 박스 예측
- 덤으로 물체의 방향 정보도 보존됨
- 겹치는 객체의 분리가 좀 더 잘됨
1
2
3
4
5
6
7
8
from ultralytics import YOLO
import cv2 as cv
model = YOLO('res/yolo26m-obb.pt')
img = cv.imread('data/boats.jpg')
results = model(img)
array = results[0].plot()
Image.fromarray(array[:, :, ::-1])

자세 추정
1
2
3
4
5
6
7
8
from ultralytics import YOLO
import cv2 as cv
model = YOLO('res/yolo26m-pose.pt')
img = cv.imread('data/bus_stop.jpg')
results = model(img)
array = results[0].plot()
Image.fromarray(array[:, :, ::-1])

수제 출력
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
keypoint_names = [
"Nose", "Left Eye", "Right Eye", "Left Ear", "Right Ear",
"Left Shoulder", "Right Shoulder", "Left Elbow", "Right Elbow",
"Left Wrist", "Right Wrist", "Left Hip", "Right Hip",
"Left Knee", "Right Knee", "Left Ankle", "Right Ankle"
]
# 임포트
from PIL import Image, ImageDraw, ImageFont
# 글꼴 설정: 같은 폴더에 ttf 글꼴 파일이 있어야 함. 없으면 기본 글꼴 사용.
try:
font = ImageFont.truetype("NanumGothic.ttf", 23)
except IOError:
font = ImageFont.load_default()
result = results[0]
kpts = result.keypoints.data.cpu().numpy() # 사람별, 키포인트별, 좌표
img_bbox = Image.fromarray(cv.cvtColor(img, cv.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img_bbox)
for kpt in kpts:
for j in range(len(kpt)): # 17개 키포인트에 대해
x, y, conf = kpt[j]
if conf > 0.5:
draw.circle((x, y), radius=3, fill="#00FF00") # 원
draw.text((x, y), f'{keypoint_names[j]}', font=font, fill="#0DD80D") # 키포인트 이름
display(img_bbox)

적대적 사례
- 머신러닝 모델을 일부러 헷갈리게 하기 위한 조작 데이터
- 사람 눈에는 문제가 안되는데 모델에는 문제가 됨
- 이걸로 공격하면 적대적 공격이 되는 거임
- 일부러 모델이 못하게 만듦
- 이미지의 경우 특정 노이즈를 섞으면 클래스 구분을 못하게 할 수 있고, 자연어 처리의 경우 특정 표현이 들어가면 모델이 전혀 다른 해석을 하게 만들 수 있음
- 점 하나만 찍어도 인식을 못하게 하는 공격도 가능함
- 그림에 붙여넣기 하면 다른 그림으로 인식되게 할 수도
이미지 생성 - GAN
- 이미지 생성자와 구분자가 경쟁하며 학습함
- 생성자
- 무작위 잡음이나 낮은 차원의 벡터를 입력받아 합성 이미지를 생성
- 구분자를 속일 정도로 진짜같은 이미지를 만드는 게 목표
- 구분자
- 생성자가 준 이미지가 진짜인지 가짜인지 구분
- 거짓말 탐지기를 똑바로 하는 게 목표
- 생성자와 구분자 모두 학습한다. 구분자의 최대 성능이 최소화되도록 생성자를 학습시키면 됨
- 구분자의 정확도가 50%가 되면 다 한 거임 → 근데 보통 여기까지는 못하지만 그래도 쓸만함
- 없는 이미지를 생성하거나 있는 이미지를 다른 것으로 바꾸는 데 쓸 수 있음
- 데이터 증강에도 쓴다
- 평가
- 사람이 하기: 주관적
- Inception score: 사전 학습된 이미지 분류 모델한테 물어봄
- 각 이미지는 해당 클래스와 비슷하게 생겨야 하고, 생성된 이미지는 골고루 있어야 함
- Fréchet Inception Distance
- 사전 학습된 모델에 실제 이미지를 입력했을 때의 활성화 분포와 가짜 이미지를 입력했을 때의 분포를 프레셰 거리로 비교
- 등등 있다더라
- 단점
- 생성자가 딱 하나만 잘해도 구분자는 무의미해지고, 생성자는 그것만 하게 됨
- 진짜같은 이미지를 만들기 위해 창의력 손해. 얼마나 다양한 사진을 만들었는지는 평가 지표에 포함되지 않음
- 생성자가 구분자보다 빠르게 성장하면 구분자의 의미가 없음, 반대의 경우 생성자의 의미가 없어서 두 경우 다 학습이 안됨
- 위와 같이 학습에 따라 결과물 편차가 큼
확산 모형
- 이미지 생성과 같은 생성 모델링에 대한 접근 방식 중 하나
- 데이터의 노이즈 확산 과정을 역추적해 원본 데이터를 복원
- 장점: 고품질 이미지, 안정적인 학습
- 단점: 느리고 데이터를 많이 먹음
- 확산
- 원본에 노이즈를 겹겹이 추가해 완전 노이즈로 만듦 → 원본의 정보가 점점 사라짐
- 확산 방식은 보통 확률론적인 방식으로 함
- 원본과 노이즈가 혼합된 상태를 획득
- 역확산
- 생성 모형을 학습시켜 노이즈로부터 원본을 복원시킴
- 단계적으로 노이즈를 제거하게 함
Stable Diffusion
- 오토 인코더의 일종인 VAE를 이용해 이미지를 압축함, 생성할 때는 랜덤 값 사용
- 다른 오토 인코더인 U-Net으로 역확산
- CLIP을 이용해 역확산 과정에 방향성 부여
- 마지막으로 VAE로 이미지 형태로 복원