
table of contents
문턱값
어제 하던 혼동행렬 코드에서 이어서 진행
아래 이미지는 문턱값의 변경에 따른 성능 지표 차이를 그림으로 나타낸 것
문턱값을 바꿔가면서 지표 계산 시각화
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
ths = np.arange(0.1, 0.9, 0.01)
accuracy, precision, recall, specificity, f1 = [], [], [], [], []
for threshold in ths:
y_pred = np.where(y_prob > threshold, 1, 0)
accuracy.append(accuracy_score(y_true, y_pred))
precision.append(precision_score(y_true, y_pred))
recall.append(recall_score(y_true, y_pred))
specificity.append(recall_score(y_true, y_pred, pos_label=0))
f1.append(f1_score(y_true, y_pred))
plt.plot(ths, accuracy, label='Accuracy')
plt.plot(ths, precision, label='Precision')
plt.plot(ths, recall, label='Recall')
plt.plot(ths, specificity, label='Specificity')
plt.plot(ths, f1, label='F1 Score')
plt.xlabel('Threshold')
plt.ylabel('Score')
plt.title('Metrics vs Threshold')
plt.legend()
plt.grid()
plt.show()
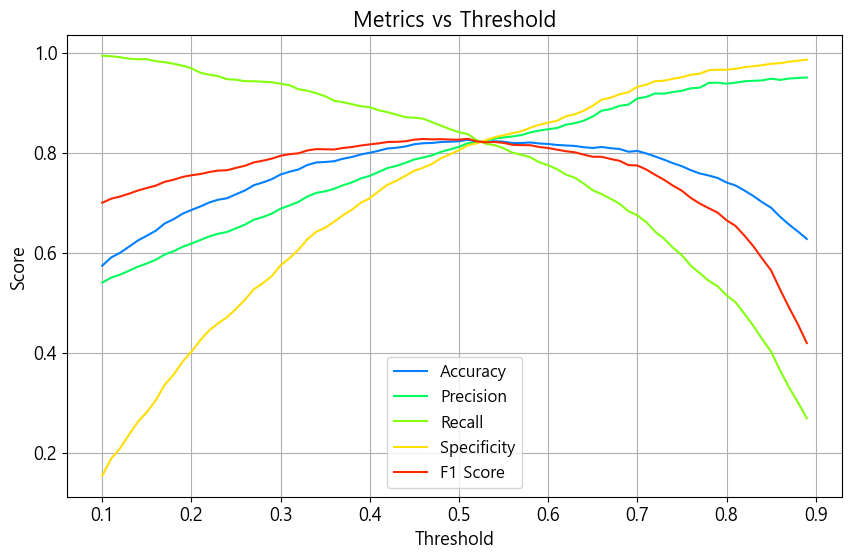
- 재현도는 문턱을 낮추면 높아짐
- 정밀도, 특이도는 문턱을 높이면 높아짐
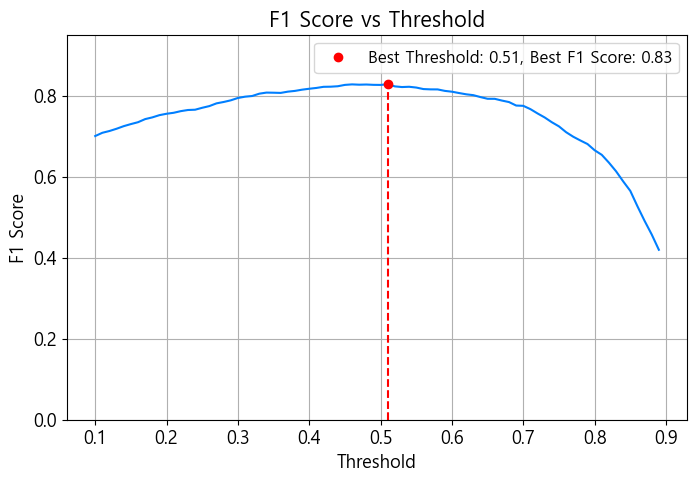
F1 점수가 가장 높은 문턱값 찾기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
i = np.argmax(f1) # 가장 큰 F1 점수의 인덱스
best_threshold = ths[i] # 가장 큰 F1 점수의 임계값
best_f1 = f1[i] # 가장 큰 F1 점수
print(f"Best Threshold: {best_threshold:.2f}, Best F1 Score: {best_f1:.2f}")
plt.figure(figsize=(8, 5))
plt.plot(ths, f1)
plt.plot((best_threshold, best_threshold), (0, best_f1), color='r', linestyle='--')
plt.plot(best_threshold, best_f1, 'ro', label=f'Best Threshold: {best_threshold:.2f}, Best F1 Score: {best_f1:.2f}') # 가장 큰 F1 점수 지점 표시
plt.ylim(0, 0.95)
plt.xlabel('Threshold')
plt.ylabel('F1 Score')
plt.title('F1 Score vs Threshold')
plt.legend(loc='upper right')
plt.grid()
plt.show()
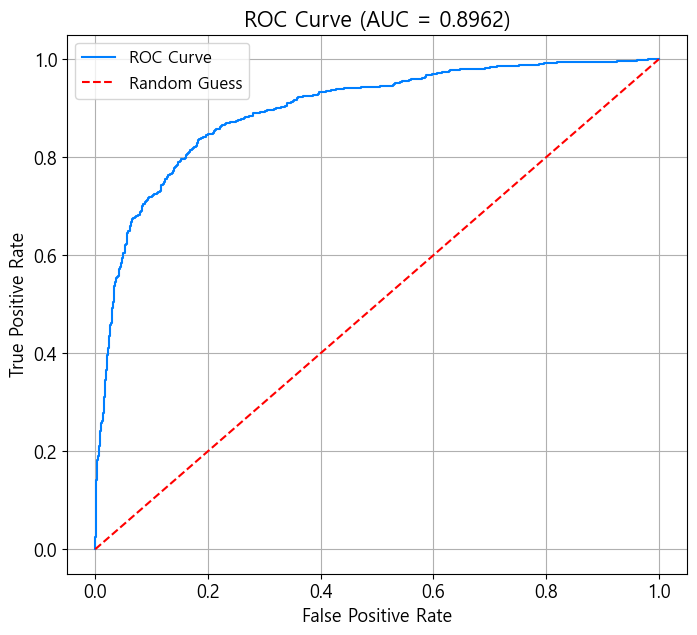
ROC 곡선 Receiver operating characteristic Curve
- 신호 이론에서 유래
- 가로축은 1-특이도(FPR), 세로축은 재현도(TPR)
- 문턱값을 변화시키면서 특이도와 재현도의 변화를 곡선으로 표시
- 무작위로 예측할 경우 TPR=FPR인 직선
- 곡선하 면적(Area Under the Curve; AUC)은 0~1 범위 → 클 수록 높은 성능
Python ROC 곡선
- ROC 곡선, AUC
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from sklearn.metrics import roc_auc_score, roc_curve
fpr, tpr, threshold = roc_curve(y_true, y_prob)
plt.figure(figsize=(8, 7))
plt.plot(fpr, tpr, label=f'ROC Curve')
plt.plot((0, 1), (0, 1), color='r', linestyle='--', label='Random Guess')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title(f'ROC Curve (AUC = {roc_auc_score(y_true, y_prob):.4f})')
plt.legend()
plt.grid()
plt.show()
다층 신경망
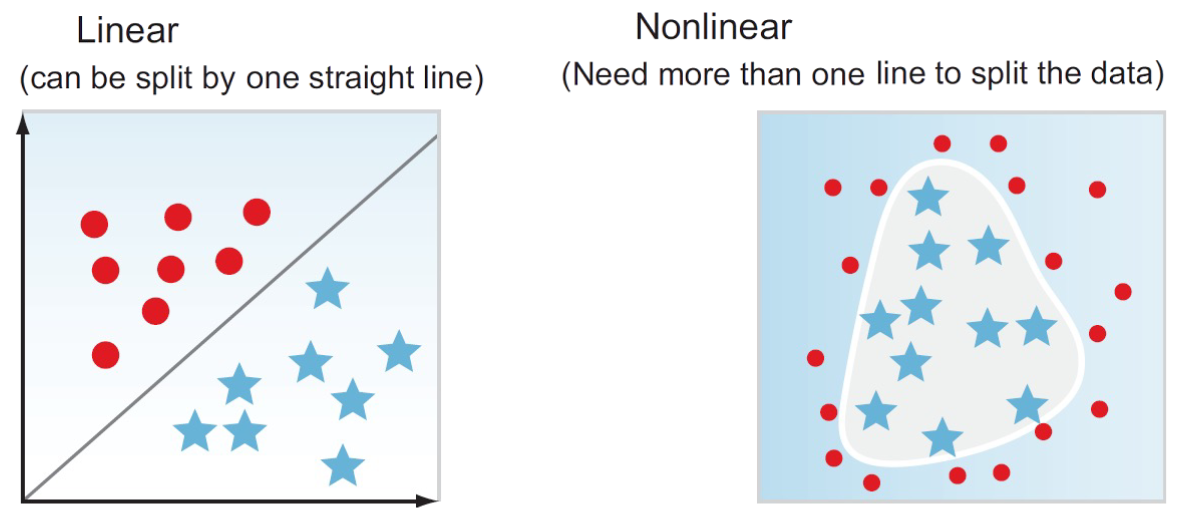
선형 분리 linearly separable
- 단층 신경망은 데이터 공간을 하나의 직선(또는 평면)으로 나누는 것
- 데이터가 복잡하면 하나 이상의 선으로 나눌 필요
선형 vs. 비선형
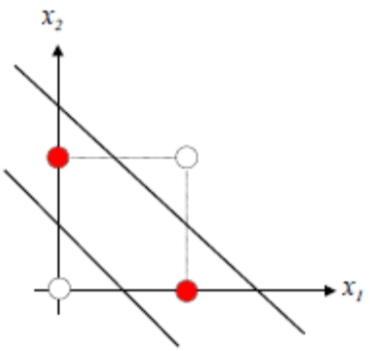
XOR 문제
- 수학에서 A OR B는 A와 B 둘 다 참인 경우에도 참
- 일상적인 의미에서 “또는”은 둘 중에 하나만 참인 경우에 사용
- XOR(Exclusive OR): A 또는 B 둘 중에 하나만 참인 경우에 참
- 선형 분리할 수 없음 → 다층 신경망으로 해결
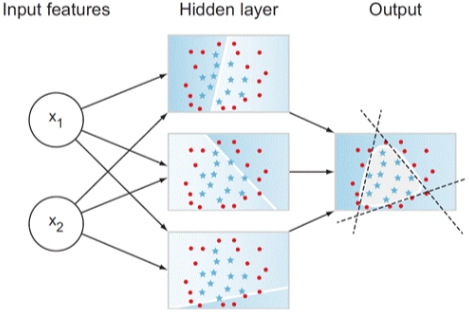
다층신경망 Multi-Layer Perceptron
- 여러 개의 층으로 이뤄진 신경망
- 선형 분리 불가능한 비선형 데이터를 다룰 수 있음
- 입력층 Input layer
- 은닉층 Hidden layers
- 신경망의 학습 과정에서 과제 수행에 필요한 특징을 학습
- 입력층에 가까운 은닉층은 단순한 특징을, 출력층에 가까운 은닉층은 복잡한 특징을 학습
- 은닉층의 형태에는 제약이 없음
- 은닉층의 적절한 수와 크기는 문제에 따라 달라짐
- 다양한 시도를 통해 가장 성능이 좋은 것으로 결정
- 출력층 Output layer
다층신경망 multi-layer perceptron
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Flatten(),
keras.layers.Dense(32, activation='relu'),
keras.layers.Dense(16, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
model.compile(
optimizer=keras.optimizers.SGD(learning_rate=0.005),
loss='binary_crossentropy', metrics=['accuracy']
)
history = model.fit(x_train_binary, y_train_binary, epochs=50, batch_size=32)
model.summary() # 학습 후에 확인해야 파라미터가 똑바로 나옴
Model: "sequential_10"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ rescaling_10 (Rescaling) │ (32, 28, 28) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten_10 (Flatten) │ (32, 784) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_23 (Dense) │ (32, 32) │ 25,120 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_24 (Dense) │ (32, 16) │ 528 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_25 (Dense) │ (32, 1) │ 17 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 25,667 (100.26 KB)
Trainable params: 25,665 (100.25 KB)
Non-trainable params: 0 (0.00 B)
미분의 연쇄 규칙 chain rule
f와 g가 미분가능한 함수라고 할 때, y = f(u)이고 u = g(x)이면, 다음이 성립:
\[\frac{dy}{dx} = \frac{dy}{du} \times \frac{du}{dx}\]다층신경망의 구성 (x: 입력, L: 손실)
![image.png]()
손실 L의 i번째 레이어의 파라미터 θi에 대한 미분: 이후 레이어(K-1)의 미분을 이전 레이어(K-2)의 미분에 재사용할 수 있음
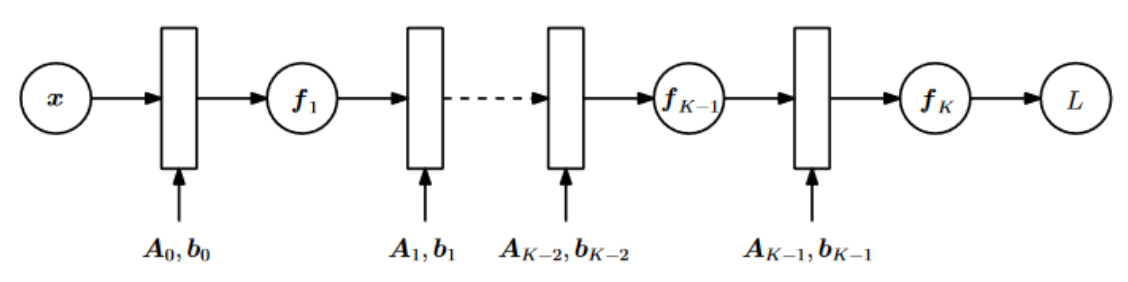
역전파 Backpropagation
- 다층신경망에서 예측을 할 때는 forward pass로 계산 input → hidden(1) → hidden(2) → … → hidden(K-1) → hidden(K)→ output
- 파라미터를 업데이트할 때는 역순인 backward pass로 계산 hidden(1) ← hidden(2) ← … ← hidden(K-1) ← hidden(K)
- 이를 “오차의 역전파”라 함
사라지는 경사 vanishing gradient
- 미분의 연쇄 규칙에 따르면 경사는 곱셈 형태
- 경사가 0~1 사이인 레이어가 많으면, 입력층과 가까운 초반 레이어는 손실의 경사가 0에 가까워짐
- 신경망 초반 레이어에서 변화가 손실에 영향을 주지 못함
- 초반 레이어로 오차 역전파가 X → 초반 레이어의 파라미터 업데이트 X
- 레이어가 늘어나도 학습이 되지 않으므로, 딥러닝의 의미 상실
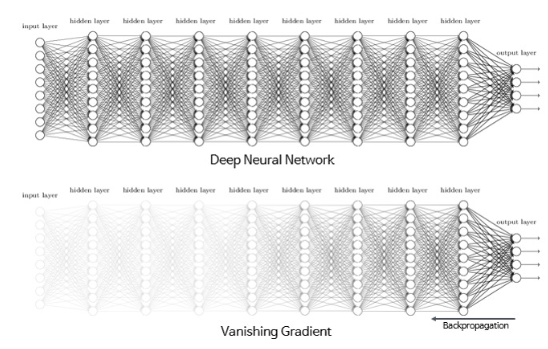
활성화 함수
활성화 함수 Activation functions
- 비선형성 도입: 신경망이 복잡한 패턴을 표현할 수 있게 함
- 출력 값 범위 조절: 활성화 함수는 뉴런의 출력 값을 특정 범위로 조절
- 예: 시그모이드 함수는 출력 값 ∈ [0, 1]
- 미분 가능한 함수여야, 경사하강법을 사용할 수 있음
- 종류: step function, sigmoid(logistic) function, softmax, tanh, ReLU
은닉층에서 sigmoid 함수의 문제점
- 포화 saturation
- 함수의 양쪽 끝에서 경사가 거의 0 → 사라지는 경사
- 입력값이 변하더라도 출력값에 거의 차이가 없음
- 중심이 0이 아님 not zero-centered
- 모든 파라미터에 대한 미분값의 부호가 같음 → 모든 파라미터가 한 방향으로만 바뀜 → 동시에 일부 가중치는 높이고, 다른 일부 가중치는 낮출 수 없음 → 학습 속도 느려짐

쌍곡탄젠트 Hyperbolic Tangent
- 로지스틱 함수와 비슷하게 생겼지만 출력 범위가 -1 ~ 1
- zero-centered
- 포화 문제는 동일
Rectified Linear Unit
\[\begin{cases} 0, & x < 0 \\ x, & x \ge 0 \end{cases}\]- not zero-centered
- 포화 문제 완화
- 계산이 간단
- 은닉층에 흔히 사용
- 0이하에서는 경사가 완전히 0
- 높은 학습률에서 dead ReLU 문제
- 최근에는 이를 보완한 ELU, GELU, Leaky ReLU 등이 널리 사용됨
이미지 다항 분류
다항 분류 모형
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(16, activation='relu'),
keras.layers.Dense(4, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer=keras.optimizers.SGD(learning_rate=0.05),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
history = model.fit(x_train, y_train, epochs=20, batch_size=32, verbose=0)
Model: "sequential_2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ rescaling_2 (Rescaling) │ (32, 28, 28) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten_2 (Flatten) │ (32, 784) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_4 (Dense) │ (32, 64) │ 50,240 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_5 (Dense) │ (32, 16) │ 1,040 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_6 (Dense) │ (32, 4) │ 68 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_7 (Dense) │ (32, 10) │ 50 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 51,400 (200.78 KB)
Trainable params: 51,398 (200.77 KB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 2 (8.00 B)
예측
확률 계산
1
2
3
4
5
6
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
y_true = y_test
y_prob = model.predict(x_test)
y_pred = np.argmax(y_prob, axis=1)
confmat = confusion_matrix(y_true, y_pred)
Accuracy: 87.06%
Precision: 87.07%
Recall: 87.06%
Specificity: 87.06%
F1: 86.86%
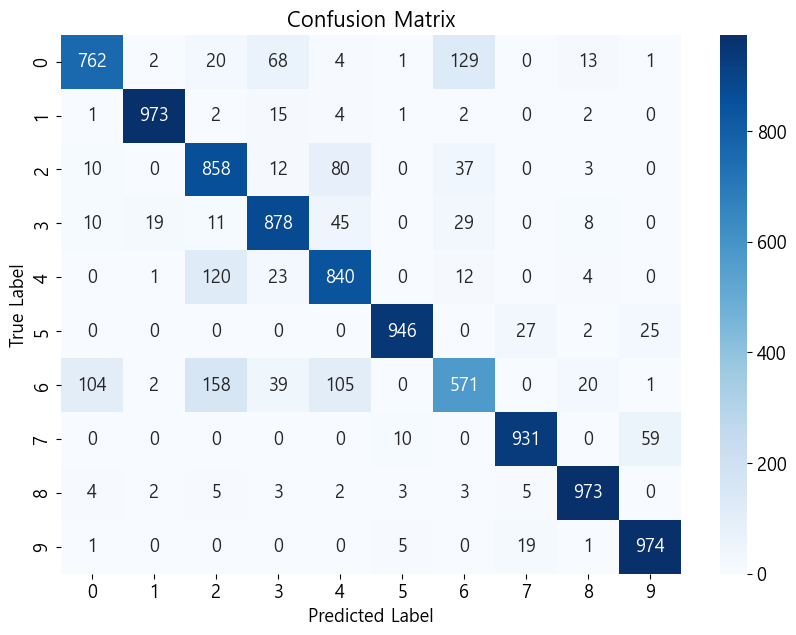
소프트맥스 함수 softmax
- 이항분류에서는 로지스틱 함수로 -∞ ~ +∞의 값을 0~1 범위로 변환
- 다항 분류에서는 소프트맥스 함수를 사용
- 여러 개의 입력을 받아, 같은 개수를 출력
- 모든 출력의 합은 1, 각 출력의 범위는 0~1
1
keras.activations.softmax(np.array([-1, 0.5, 2.0])) == [0.039, 0.175, 0.796]
- 시그모이드는 소프트맥스의 특수한 경우
- 둘 중에 하나로 예측할 때: sigmoid
- 셋 이상 중에 하나로 예측할 때: softmax
1
2
3
x = 1.0
keras.activations.sigmoid(x)
keras.activations.softmax(np.array([0.0, 1.0]))
소프트맥스 함수가 없는 모형
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dense(16, activation='relu'),
keras.layers.Dense(4, activation='relu'),
keras.layers.Dense(10)
])
model.compile(
optimizer=keras.optimizers.SGD(learning_rate=0.1),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
history = model.fit(x_train, y_train, epochs=5, batch_size=32, verbose=1)
로짓 계산
1
2
3
4
logits = model.predict(x_test)
logits.shape # 10000, 10
logits[0] # 0번째 샘플의 로짓
keras.activations.softmax(logits[0]) # 0번째 샘플의 확률
tensor([3.2136e-10, 8.2367e-04, 8.1894e-12, 6.3082e-07, 6.8053e-14, 3.4221e-04,
8.5204e-14, 3.7720e-03, 1.4845e-06, 9.9506e-01], device='cuda:0')
정칙화
딥러닝 정칙화
- 정칙화(regularization): 모델의 과대적합을 막기 위한 방법들
- Weight decay: 파라미터를 업데이트할 때마다 줄임
- Early stopping: 파라미터 업데이트를 일찍 멈춤
- Dropout: 일부 파라미터를 훈련에서 배제
- Batch/Layer Normalization: 레이어의 출력값을 정규화
- Label Smoothing: 모형 출력의 목표값을 줄임
weight decay
원래의 경사하강법:
\[w \leftarrow w - \eta \frac{\partial L}{\partial w}\]weight decay: 파라미터를 업데이트를 할 때 가중치를 줄이는 것
\[w \leftarrow w(1 - \eta \lambda) - \eta \frac{\partial L}{\partial w}\]- 손실 함수에 L2 노름을 추가하고, SGD로 파라미터를 업데이트 한 것과 동일
- 경사하강법 알고리즘에 weight_decay 인자
- 위 수식의 λ와 같음(클 수록 더 많이 줄임)
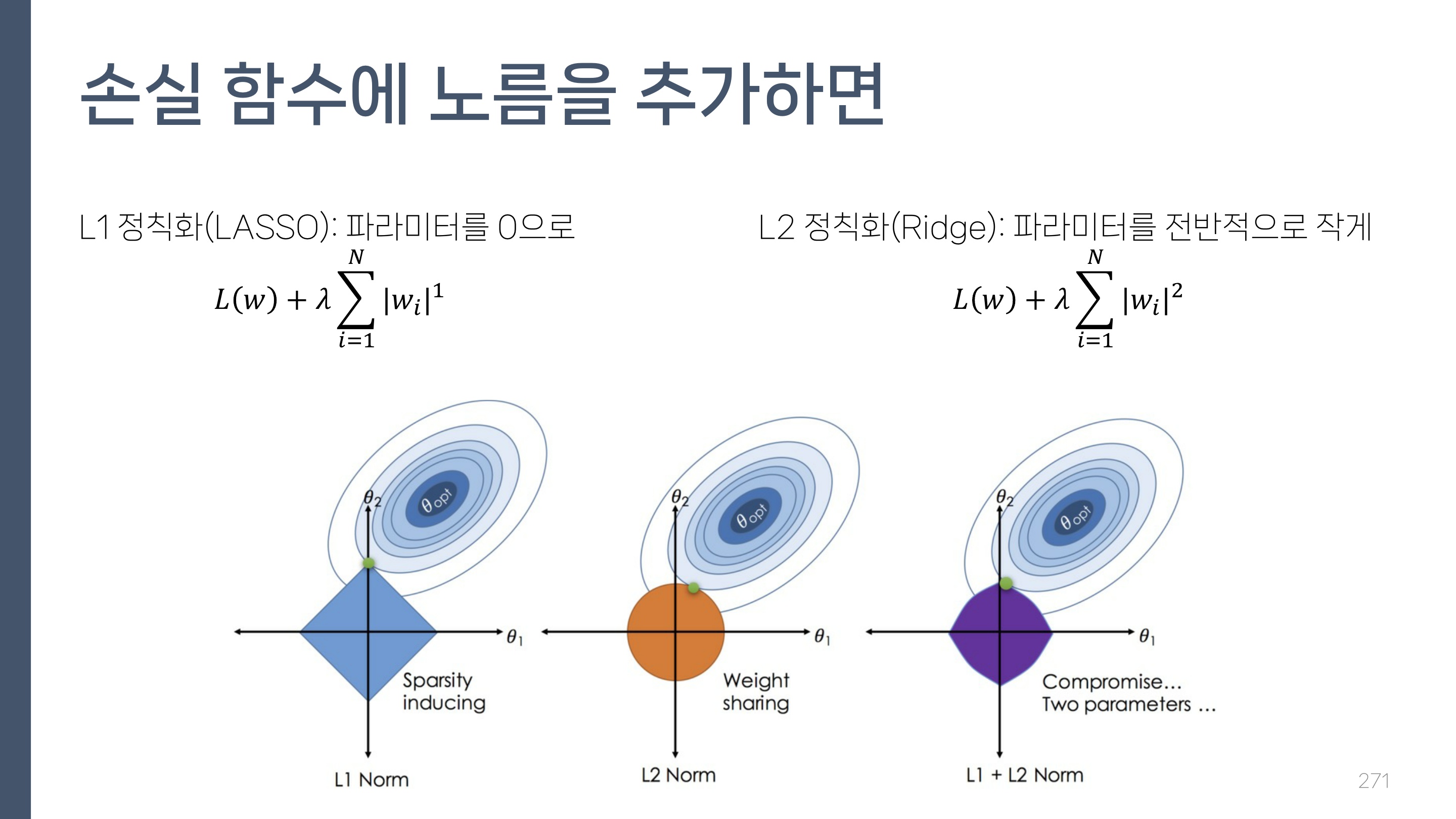
노름 Norm
- 노름(norm): 길이 또는 크기를 일반화한 개념
Lp 노름
\[\left( \sum_{i=1}^{N} |w_i|^p \right)^{1/p}\]
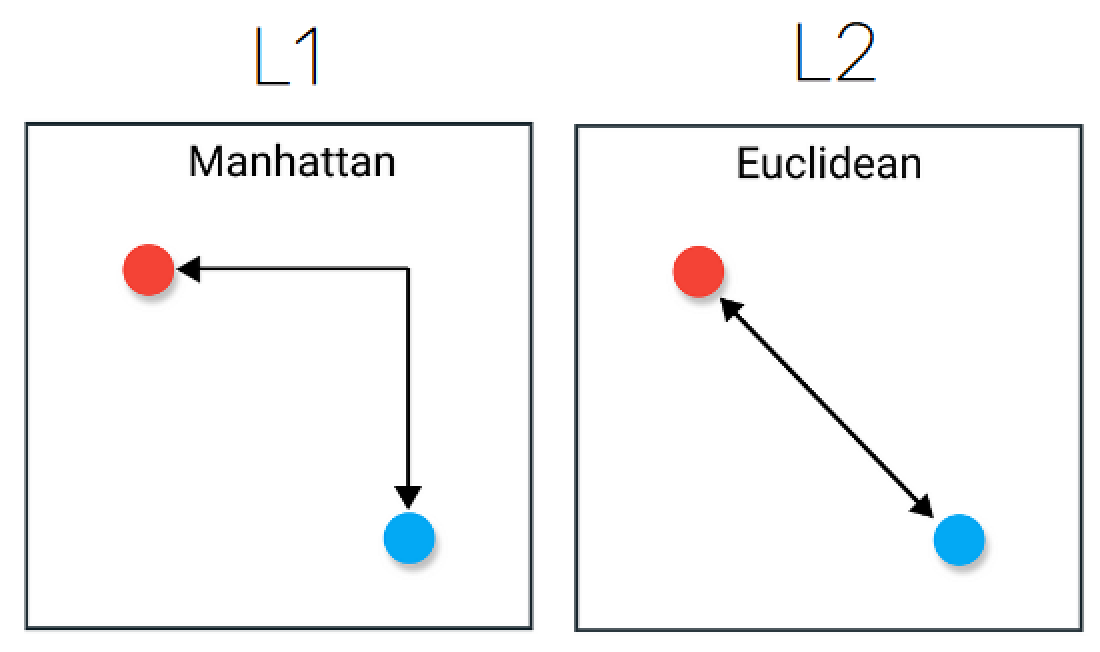
손실 함수에 노름을 추가하면
- L1 정칙화(LASSO): 파라미터를 0으로
- L2 정칙화(Ridge): 파라미터를 전반적으로 작게
얼리스톱핑 Early Stopping
- 적합 중에 검증 데이터로 검증하여 성능이 향상되지 않으면 진행을 중단
- 미리 정한 에포크보다 일찍(early) 멈춤(stop)
- 과대적합을 방지하기 위한 정칙화 방법
- 파라미터는 0 근처의 초기값에서 시작 → 에포크를 거듭하면서 수정
- 에포크를 줄여주면 파라미터를 작게(0에 가깝게) 만드는 효과가 있음
얼리스톱핑을 이용한 훈련
1
2
3
4
5
6
7
8
9
10
11
12
13
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Flatten(),
keras.layers.Dense(10)])
model.compile(optimizer=keras.optimizers.SGD(learning_rate=0.001),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(x_train, y_train, batch_size=32,
epochs=50, # 최대 에포크
validation_split=0.2, # 에포크마다 20%의 데이터로 검증
callbacks=[keras.callbacks.EarlyStopping(monitor='val_loss', patience=1)])
# monitor: 검증 데이터의 손실을 기준으로 멈춤 여부를 결정
# patience: 몇 에포크 동안 개선이 없으면 멈출지 지정
자동 저장
- 얼리스톱핑은 성능이 일시적으로 하락해도 정지
- patience라는 인자로 몇 번은 넘어가게 할 수 있으나 적절한 설정 값을 알기 어려움
- ModelCheckpoint 콜백을 이용해서 검증 성능이 가장 좋은 모델의 파라미터를 자동 저장할 수 있음
- 정해진 에포크의 훈련이 모두 끝난 후 가장 성능이 좋았던 에포크의 파라미터를 다시 불러올 수 있음
1
2
3
4
5
6
7
model.fit(x_train, y_train, epochs=50, batch_size=32, validation_split=0.2, callbacks=[
keras.callbacks.EarlyStopping(monitor='val_loss', patience=3),
keras.callbacks.ModelCheckpoint('best_model.h5', monitor='val_loss', save_best_only=True)
])
# 저장된 파라미터 불러오기
best_model = keras.models.load_model('best_model.h5')
드롭아웃 dropout
- 학습 과정에서 배치마다 입력층과 은닉층의 출력값을 무작위로 0으로 대체
- 특정한 특징에 과적합되는 것을 방지하기 위한 정칙화 방법
- 드롭아웃의 비율은 0-1 사이에서 조정
- 예측시에는 드롭아웃 대신, 출력이 비율로 조정(훈련시에 출력 중 50%를 드롭아웃 했으면, 예측시에는 모든 출력의 크기를 50%로 줄임)
1
2
3
4
5
6
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dropout(0.5), # 드롭아웃 비율 50%
keras.layers.Dense(10)])
Normalization
- 넓은 의미로 통계학에서 변수값의 크기를 일정하게 만들어 주는 것
대표적인 예로 표준화(standardization)
\[\frac{X - \mu}{\sigma}\]- X: 값, μ: 평균, σ: 표준편차
- 평균 = 0, 표준편차 = 1이 됨
- 서로 다른 평균과 표준편차를 가진 변수를 비교하기 쉽게 해줌
- Normalization은 “정규화”로 많이 번역하나, regularization과 혼동
- 좁은 의미로 0-1 범위로 변환하는 min-max scaling만을 normalization이라고 쓰는 사람들도 있음
- 이 경우에는 표준화 ≠ normalization
입력 Normalization
- 이미지 입력도 Normalization을 해주면 성능에 도움
- 보통 0-255 범위의 픽셀 값을 -1 - +1 또는 0-1 범위로 normalize
- 특징(feature, 이미지의 경우 픽셀값)에 따라 값의 크기가 매우 다른 경우, 특징들의 값의 범위를 비슷하도록 normalize하면 경사하강법에서 진동이 줄어들어 수렴이 더 빨라짐
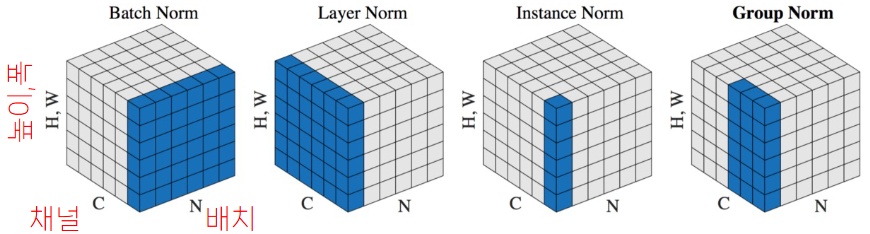
Batch Normalization
- 각 레이어의 입력도 normalize하면 성능이 향상될 수 있음
- 모형의 입력과 달리 각 레이어의 입력은 학습 과정에서 매번 해줘야 하므로 계산 비용이 높음
- batch 단위로 normalize 하여 효율을 향상
- 종류:
- Batch Norm: 미니배치 전체에 걸쳐 채널별로 normalize
- Layer Norm : 각 사례의 모든 채널을 normalize
- Instance Norm : 각 사례를 채널별로 normalize
- Group Norm : 각 사례의 채널들을 그룹으로 묶어 normalize
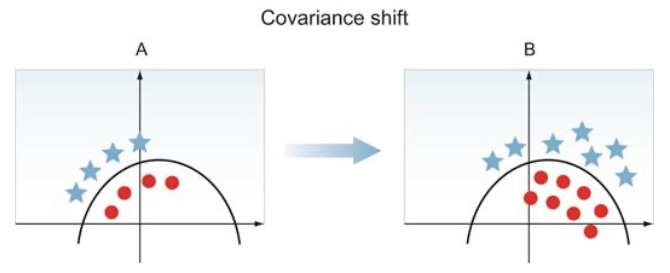
Covariance Shift
- 다층신경망에서는 한 은닉층의 출력이 다른 은닉층의 입력이 됨
- 학습 과정에서 각 층의 출력이 변화 → 다음 층의 입력이 변화
- 각 층이 받는 입력이 지속적으로 변화하므로 문제가 됨(covariance shift)
- BN은 이를 방지하여 학습 효율을 높인다는 지적(아니라는 의견도 있음)
BN의 효과
- 포화를 억제
- 신경망의 활성화 함수는 기울기가 0에 가까운 영역이 존재
- 신경망의 출력을 일정 범위로 제한하여 포화를 억제
- 학습 속도 향상
- 높은 학습률에도 학습이 안정적으로 이뤄짐
- 활성화 함수에서 포화되는 영역에 빠지는 문제를 피할 수 있음
- 경사가 사라지거나 폭발하는 문제를 완화
- 정칙화 효과
- 배치에 따라 평균과 표준편차가 달라지므로 출력값에 일정한 오차가 생김
- Dropout과 비슷한 효과 → Dropout을 안 써도 된다 → 학습 속도도 빨라짐
1
2
3
4
5
6
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.BatchNormalization(), # 배치 정규화
keras.layers.Dense(10)])
Early Stopping부터 BatchNormalization까지 모두 적용해보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='relu'),
keras.layers.Dropout(0.2), # 드롭아웃 비율 20%
keras.layers.Dense(16, activation='relu'),
keras.layers.BatchNormalization(), # 배치 정규화
keras.layers.Dense(4, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
model.compile(
optimizer=keras.optimizers.SGD(learning_rate=0.1),
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
history = model.fit(
x_train, y_train, batch_size=32,
epochs=100, # 최대 에포크
validation_split=0.2, # 에포크마다 20%의 데이터로 검증
callbacks=[
keras.callbacks.EarlyStopping(monitor='val_loss', patience=3, verbose=1),
# monitor: 검증 데이터의 손실을 기준으로 멈춤 여부를 결정
# patience: 몇 에포크 동안 개선이 없으면 멈출지 지정
keras.callbacks.ModelCheckpoint('../res/best_model.keras', monitor='val_loss', save_best_only=True, verbose=1)
]
)
one-hot encoding
- 머신러닝에서 범주형 변수를 표현하는 방법
- 사례마다 변수의 값을 범주의 개수와 같은 길이의 벡터로 표현
- 벡터의 다른 모든 원소는 0(cold)
- 사례의 범주에 해당하는 원소 하나만 1(hot)
- 예: 신문 기사를 정치, 사회, 경제, 문화 네 가지 범주로 분류하는 경우
- 정치 → (1, 0, 0, 0)
- 사회 → (0, 1, 0, 0)
- 경제 → (0, 0, 1, 0)
- 문화 → (0, 0, 0, 1)
- 범주 하나를 제외해서 벡터의 길이를 -1 한 것은 더미 코딩(dummy coding)이라고 함
- 예) 사회 → (1, 0, 0) # 정치는 표시 제외
- 머신러닝에서는 잘 사용하지 않고, 주로 통계에서 사용
패션MNIST 데이터에 적용
1
2
3
4
5
6
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
y_train.shape, y_test.shape # ((60000, 10), (10000, 10))
똑같은 짓을 여러 번 하면 그때마다 차원이 더해지니까 데이터를 새로 불러와서 시키거나 딱 한 번만 실행하도록 주의하기
label smoothing
- 레이블은 부정확하게 붙어있을 수 있거나 예외적인 사례일 수 있음
- 이러한 데이터에 과적합될 경우 모형의 예측력이 떨어짐
- 원 핫 인코딩에서 1을 조금 줄이고 그만큼 0을 키워줌
- 데이터에 있는 레이블에 100%보다 낮은 확률을 부여(없는 레이블도 0%보다 높은 확률을 부여)
- 예) (1, 0, 0, 0) → (0.85, 0.05, 0.05, 0.05)
이항 분류:
1
keras.losses.BinaryCrossentropy(label_smoothing=0.15)
다항 분류:
1
keras.losses.CategoricalCrossentropy(label_smoothing=0.15)
keras.losses.SparseCategoricalCrossentropy는 지원X
다층 신경망의 문제점
- 이미지는 2차원이지만 다층 신경망의 입력은 1차원
- 이미지를 2차원 → 1차원으로 flatten하여 입력
- 2차원 이미지를 1차원으로 flatten하면서 공간적 정보가 사라짐
- Dense 레이어는 입력의 크기 × 출력의 크기만큼 파라미터가 필요
- 이미지의 크기가 커지면 파라미터가 폭증
합성곱 신경망 Convolutional Neural Network
- 합성곱 신경망은 입력 이미지를 작은 단위로 나누어 각각을 처리
- 이 작은 단위를 필터(filter) 또는 커널(kernel)이라고 부름
- 필터는 이미지의 특징을 추출하는 역할
- 컴퓨터 비전에서 가장 널리 사용되어 온 방식
- 최근에는 비전 트랜스포머라는 모델도 널리 사용
- 작은 크기의 필터를 반복 적용하여 부분적인 패턴을 인식
- 필터의 값은 데이터로부터 학습
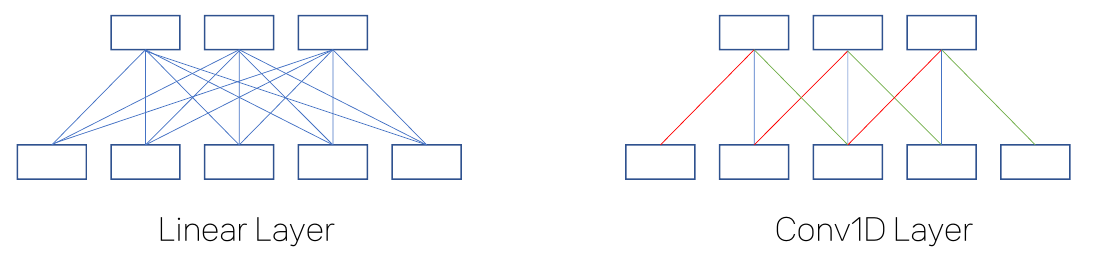
합성곱 레이어
- Receptive Field: 이미지에서 필터가 적용되는 영역
- Feature Map: 합성곱 레이어의 출력 결과
- 이미지에서 발견된 특징을 사상(map)한 것이므로 feature map이라고 함
부분에서 전체로
- 합성곱 신경망은 여러 가지 필터들을 이용해 이미지의 한 작은 부분에서 특징들을 그리고 여러 개의 필터를 사용하여 입력 이미지에서 다양한 특징을 추출
- 사람의 얼굴을 인식한다면, 처음에는 수직선, 수평선, 대각선 등의 특징을 추출
- 이렇게 추출한 특징들에 다시 필터를 적용하면 좀 더 큰 특징을 추출할 수 있음
- 선들이 모여 이루는 눈, 코, 입 같은 부분들이 됨
- 여기에 다시 필터를 또 적용하면 부분이 모여서 이루는 얼굴 전체를 추출할 수 있음
합성곱 적용의 효과
- 커널 또는 필터의 수만큼 채널이 바뀌는 효과가 있음
- 피처 맵의 크기는 감소
- 다양한 필터를 적용하여 하나의 이미지로부터 여러 가지 특징들을 추출
CNN의 기본 구조
- 특징 추출 부분과 분류 부분으로 구성
- 합성곱 신경망의 전반부에는 부분적 특징들을 추출하기 위해 합성곱 레이어를 사용
- 합성곱 신경망의 후반부에는 추출된 특징을 바탕으로 최종 예측을 하기 위해 Dense 레이어를 사용
- 두 부분 사이에 Flatten
CNN
1
2
3
4
5
6
7
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)),
keras.layers.MaxPooling2D((2,2)),
keras.layers.Flatten(),
keras.layers.Dense(10),
])
사실 요점은 (컨볼루션 → 풀링) 반복 후 flatten → dense 구조임 저것만 유지하면 됨
풀링 pooling
- 서브샘플링(subsampling) 또는 다운샘플링(downsampling)이라고도 함
- 이미지 또는 특징 맵의 크기를 축소
- 이미지의 세부적인 특징이 전체 이미지를 분류하는데 크게 중요하지 않은 경우가 많으므로 성능에는 영향이 적음
- 적용할 합성곱 레이어의 수가 줄어듦 → 학습할 파라미터가 줄어듦
- 최대 풀링(Max Pooling):
- 이미지에서 작은 부분(예: 2x2)들에서 최댓값(가장 강한 특징)을 추출
- CNN에 주로 사용
- 평균 풀링(Average Pooling):
- 이미지에서 평균값을 추출
패딩 padding
- 이미지의 테두리에 빈 픽셀을 추가
- 제로(zero) 패딩:
- 패딩 없음
- 입력보다 출력 이미지가 작음
- 하프(half) 패딩 / 세임(same) 패딩:
- 필터 크기의 절반만큼 패딩
- 입력과 출력의 이미지가 같음
- 풀(full) 패딩
- 필터 크기 - 1만큼 패딩
- 모든 픽셀에 필터의 모든 부분이 적용됨
- 출력이 입력보다 큼
패딩
1
2
3
4
5
6
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Conv2D(32, (3,3), activation='relu', padding='same'),
keras.layers.Flatten(),
keras.layers.Dense(10),
])
스트라이드 stride
- 필터를 적용하는 간격
- 풀링을 사용하는 대신 필터를 일정 간격으로 띄워서 사용하기도 함
스트라이드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Conv2D(32, (3,3), strides=(2,2), activation='relu'),
keras.layers.Flatten(),
keras.layers.Dense(10),
])
model.compile(optimizer=keras.optimizers.SGD(learning_rate=0.001),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(np.expand_dims(x_train, -1),
# (N, 28, 28) → (N, 28, 28, 1) 색상 채널 추가
y_train, epochs=5, batch_size=32)
종합 CNN
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
model = keras.models.Sequential([
keras.layers.Input(shape=(28, 28, 1)),
keras.layers.Rescaling(1/255),
keras.layers.Conv2D(
64, (3, 3), activation='relu',
# strides=(2, 2), # strides. 지금 데이터에서는 이미지가 너무 작아서 적용 불가
padding='same', # padding
),
keras.layers.MaxPooling2D((2, 2)), # pooling
keras.layers.Conv2D(20, (3, 3), activation='relu', padding='same'),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Conv2D(20, (3, 3), activation='relu', padding='same'),
keras.layers.Dropout(0.25),
keras.layers.Flatten(),
keras.layers.Dropout(0.25),
keras.layers.Dense(100, activation='relu'),
keras.layers.Dense(10, activation="softmax"),
])
model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.CategoricalCrossentropy(),
metrics=['accuracy']
)
history = model.fit(
np.expand_dims(x_train, -1), # (N, 28, 28) → (N, 28, 28, 1) 색상 채널 추가
y_train,
batch_size=500, epochs=150,
validation_data=(np.expand_dims(x_test, -1), y_test),
callbacks=[
keras.callbacks.EarlyStopping(monitor='val_loss', patience=3, verbose=1),
keras.callbacks.ModelCheckpoint('../res/best_model.keras', monitor='val_loss', save_best_only=True, verbose=1)
],
)
CNN의 다양한 구조
- LeNet-5
- AlexNet
- VGGNet
- GoogLeNet
- ResNet
LeNet-5
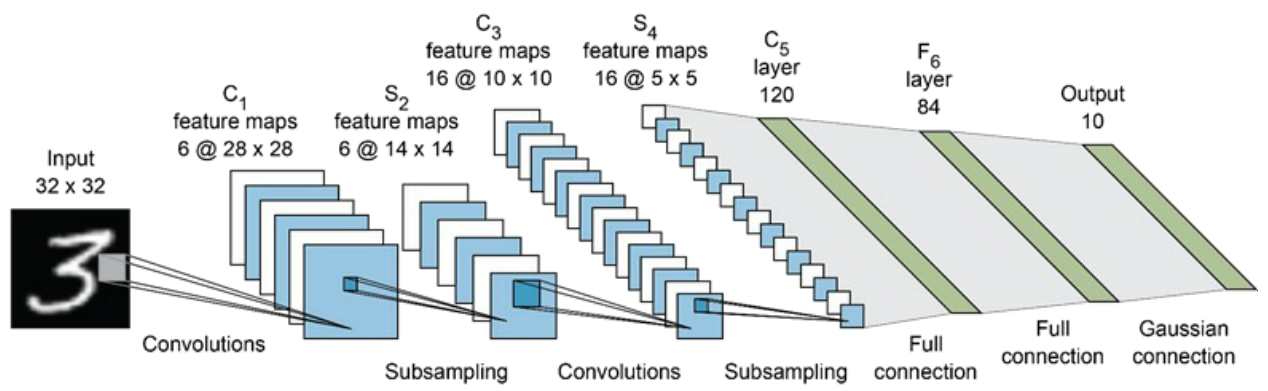
AlexNet
- 2012년 ImageNet Large Scale Visual Recognition Challenge (ILSVRC)에서 1위를 하여 딥러닝 유행을 선도
- 특징: ReLU, Dropout, Batch Normalization, Weight regularization
VGGNet
- 합성곱 레이어는 모두 3x3 크기
- 풀링 레이어는 모두 2x2 크기
- 3x3 합성곱 2개는 5x5 합성곱와 receptive field 크기가 같으나 파라미터의 수가 더 적고, 1개의 레이어 대신 2개의 레이어를 사용하므로 비선형성을 추가할 수 있음
GoogLeNet
- Inception 모듈이라는 구조를 포함
- 합성곱 레이어를 직렬이 아닌 병렬로 연결
1x1 Conv. Layer
- 피처맵의 크기는 같음
- 채널의 수를 줄이는 효과
- 1x1 합성곱 레이어를 통해 채널의 크기를 줄여 계산량을 감소시킴
- 인셉션 모듈의 다른 경로에도 1x1 합성곱을 추가하여 출력 채널을 줄임
ResNet Residual Network
- skip connection: 레이어를 건너 뛰는 경로를 만듦
- 최소한 이전 레이어에서 학습된 만큼의 성능은 보장
- 사라지는 경사 문제를 완화하고, 깊은 네트워크에서도 안정적인 학습이 가능
- 신경망의 깊이를 늘려도 학습이 잘 되므로 성능이 향상
이미지 로딩
Dog vs Cat 데이터셋
- 캐글(데이터 사이언스 경진대회 플랫폼) 데이터
- 고양이와 강아지를 사진으로 구분하는 문제
- 대회 1등 정확도가 98.9%
- https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip
- cats_and_dogs_filtered
- train
- cats
- dogs
- validation
- cats
- dogs
- train
- 부품 불량을 분류하는 프로젝트를 하고 싶다면 cats, dogs 대신에 정상, 불량 폴더를 만들어 분류
전처리
1
2
3
4
5
6
7
8
from torchvision import transforms
IMAGE_SIZE = 224
transform = transforms.Compose([
transforms.Resize((256, 256)), # 이미지마다 크기가 다르므로 통일
transforms.CenterCrop((IMAGE_SIZE, IMAGE_SIZE)), # 가운데만 잘라냄
transforms.ToTensor(),
transforms.Lambda(lambda x: (x / 127.5) - 1)
])
- 이미지 데이터는 0~255로 밝기를 표현
- 신경망에서 사용하는 시그모이드 등의 함수는 지나치게 큰 값이 들어오면 경사가 0에 가까워져서 학습이 잘 되지 않음
- 1~+1 범위로 재조정
데이터 로딩
1
2
3
4
5
6
7
8
9
10
11
12
# 데이터셋
from torchvision.datasets import ImageFolder
train_dataset = ImageFolder(root='../data/cats_and_dogs_filtered/train', transform=transform)
val_dataset = ImageFolder(root='../data/cats_and_dogs_filtered/validation', transform=transform)
# 로딩
from torch.utils.data import DataLoader
BATCH_SIZE = 64
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False)
데이터가 폴더 단위로 나눠져있어서 그냥 ImageFolder 쓰면 일일이 가져와서 합치고 나누고 할 거 없이 딱 로드해준다
모델 정의 학습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
model = keras.Sequential([
keras.Input(shape=(3, IMAGE_SIZE, IMAGE_SIZE)), # (Channels, Height, Width)
keras.layers.Conv2D(32, (3, 3), activation='relu', data_format='channels_first'),
keras.layers.MaxPooling2D((2, 2), data_format='channels_first'),
keras.layers.Conv2D(32, (3, 3), activation='relu', data_format='channels_first'),
keras.layers.Dropout(0.25),
keras.layers.Flatten(),
keras.layers.Dense(512, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
model.compile(
optimizer=keras.optimizers.SGD(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy']
)
history = model.fit(
train_loader,
epochs=3,
validation_data=val_loader
)
Keras는 기본적으로 Height, Width, Channels 순으로 입력 PyTorch는 Channels가 먼저 나오므로 데이터 포맷을 그에 맞춰줌
이미지 한 장 테스트
이미지 한 장 불러오기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from PIL import Image
val_route = '../data/cats_and_dogs_filtered/validation/'
# 고양이, 개 랜덤 선택 후 폴더 안에서 랜덤으로 하나 선택하기
cat_or_dog = np.random.choice(['cats', 'dogs'])
folder = os.path.join(val_route, cat_or_dog)
file = np.random.choice(os.listdir(folder))
image = Image.open(os.path.join(folder, file))
display(image)
x = transform(image)
print(f"x.shape: {x.shape}") # 채널, 높이, 폭
batch = x.unsqueeze(0) # 차원을 추가 (expand_dims와 같음)
pred_result = model.predict(batch)
# 모델이 예측한 게 어떤 클래스인지 출력하기
res_txt = f"예측 확률: {pred_result[0][0]:.4f}"
if pred_result[0][0] < 0.5:
res_txt += f" → {pred_result[0][0]*100:.2f}% 확률로 고양이"
else:
res_txt += f" → {100-(pred_result[0][0]*100):.2f}% 확률로 강아지"
print(res_txt)

결과 빨리 보려고 학습을 조금만 시켜서 성능은 랜덤 찍기 수준임. 여러 번 시켜봤는데 뭘 넣어도 49~49% 확률로 고양이를 찍었음.
데이터 증강
데이터 증강 data augmentation
- 데이터 생성의 어려움: 모델은 복사가 가능하지만, 데이터는 직접 만들어야 하므로 비용이 발생함.
- 해결책으로서의 데이터 증강: 기존 데이터를 변형하여 데이터 양을 늘리는 기법.
- 증강 방법 예시: 이미지 회전, 좌우 반전, 색상 변경 등을 통해 하나의 데이터를 여러 개로 불림.
- 장점: 데이터 수집의 수고 없이 무료로 데이터 양을 늘릴 수 있음.
데이터 증강의 한계
- 한계와 주의점: 데이터의 본질적인 의미를 변화시키지 않는 범위에서만 제한적으로 사용해야 함.
- 부적절한 증강 예시:
- 나비 종류 분류: 색상이 중요한 특징이므로 임의로 색을 바꾸면 안 됨.
- 자율 주행: 주행 차선의 좌우 정보가 중요하므로 이미지를 좌우로 뒤집으면 안 됨. 신호등 색상 변경 또한 불가.
실습 준비
예제 파일 열기
1 2
from PIL import Image img = Image.open('pump_horse.jpg')
여러 이미지 보기 (4개 붙여서 한번에 보기)
1 2 3 4 5 6 7 8
def concat_images(images): n = len(images) width, height = 128, 128 total_width = n * width new_im = Image.new('RGB', (total_width, height), color='white') for i, im in enumerate(images): new_im.paste(im.resize((width, height)), (width * i, 0)) return new_im
RandomPerspective
무작위로 perspective를 바꿈
1
2
transform = transforms.RandomPerspective(distortion_scale=0.6, p=1.0)
concat_images([transform(img) for _ in range(4)])

RandomRotation
무작위로 회전
1
2
transform = transforms.RandomRotation(degrees=(0, 180))
concat_images([transform(img) for _ in range(4)])

RandomAffine
무작위 아핀 변환
1
2
3
transform = transforms.RandomAffine(
degrees=(30, 70), translate=(0.1, 0.3), scale=(0.5, 0.75), shear=(10, 30))
concat_images([transform(img) for _ in range(4)])

RandomCrop
무작위로 주어진 크기의 일부 영역을 잘라냄
1
2
transform = transforms.RandomCrop(size=(128, 128))
concat_images([transform(img) for _ in range(4)])

RandomResizedCrop
무작위로 잘라낸 후, 정해진 크기로 변경
1
2
transform = transforms.RandomResizedCrop(size=(512, 512))
concat_images([transform(img) for _ in range(4)])

ColorJitter
무작위로 색을 변경: brightness(밝기), contrast(대조), 채도(saturation), hue(색상)
1
2
transform = transforms.ColorJitter(brightness=.5, hue=.3)
concat_images([transform(img) for _ in range(4)])

RandomInvert
무작위로 색 반전
1
2
transform = transforms.RandomInvert()
concat_images([transform(img) for _ in range(4)])

RandomPosterize
무작위로 포스터화(색의 비트 수를 낮춤)
1
2
transform = transforms.RandomPosterize(bits=2)
concat_images([transform(img) for _ in range(4)])

RandomChoice
무작위로 고르기
1
2
3
4
5
6
transform = transforms.RandomChoice([
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(180),
])
concat_images([transform(img) for _ in range(4)])

RandomApply
각각의 변환을 확률 p에 따라 무작위로 적용
1
2
3
4
5
6
transform = transforms.RandomApply([
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(180),
], p=0.9)
concat_images([transform(img) for _ in range(4)])

RandomOrder
무작위 순서로 적용
1
2
3
4
5
transform = transforms.RandomOrder([
transforms.RandomRotation(180),
transforms.RandomCrop((256, 256)),
])
concat_images([transform(img) for _ in range(4)])

증강의 경우 transform 예시
1
2
3
4
5
6
7
8
9
10
11
12
transform = transforms.Compose([
transforms.RandomChoice([ # 증강
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
]),
transforms.Resize((256, 256)), # 이미지마다 크기가 다르므로 통일
transforms.CenterCrop((IMAGE_SIZE, IMAGE_SIZE)), # 가운데만 잘라냄
transforms.ToTensor(),
transforms.Lambda(lambda x: (x / 127.5) - 1)
])
transform
Compose(
RandomChoice(
RandomHorizontalFlip(p=0.5)
RandomVerticalFlip(p=0.5)
)(p=None)
Resize(size=(256, 256), interpolation=bilinear, max_size=None, antialias=True)
CenterCrop(size=(224, 224))
ToTensor()
Lambda()
)
Vision Transformer
CNN의 한계
- 합성곱 신경망은 이미지의 작은 부분을 처리하고 그 결과를 모아 좀 더 큰 부분을 처리 해나감
- 서로 멀리 떨어진 부분들 사이의 관계를 잘 처리하지 못함
- 서로 멀리 떨어진 feature들을 고려하기 위해서는 큰 필터가 필요 → 계산의 효율성 감소
순환신경망 recurrent neural network
- 자연어 처리에서 흔히 사용하는 구조
- 이전의 입력이 이후의 입력에 처리에 영향
- 먼 거리에 떨어진 입력 간에 정보를 전달하려면 여러 단계를 거쳐야 함
- 사라지는 경사(vanishing gradient) 문제
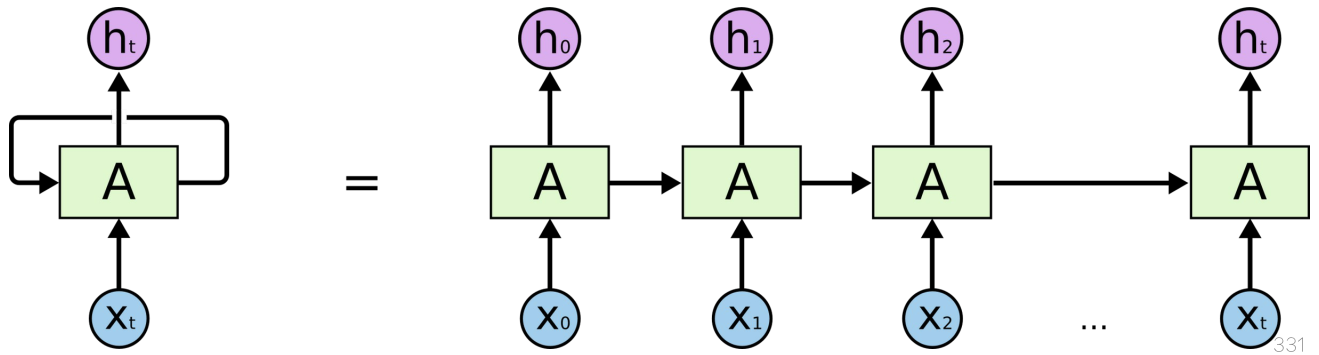
주의 메커니즘 attention mechanism
- 이전의 입력 중 현재 입력을 처리하는데 필요한 정보를 바로 가져오는 방법
- 현재 단계의 값과 이전 단계의 값을 비교하여 주의 가중치(attention weight)를 계산
- 이전 단계의 값들에 주의 가중치를 적용하여 가중합
- 현재 단계와 유사한 특성을 가지는 이전 단계의 값들을 더 큰 비중으로 반영
트랜스포머 Transformer
- 주의 메커니즘만을 사용한 자연어 처리 모형
- 문장 내에 주의 메커니즘 적용
- 문장 간에도 주의 메커니즘 적용
- Multi-Head Attention
- 모든 단어는 Q, K, V 세 가지 임베딩을 가짐
- Q와 K로 주의 가중치를 계산하여 V에 적용
- 주의 가중치를 다양한 방식으로 계산하여 결합
- 위치 인코딩
- 순환신경망은 처리 과정 자체가 순서대로 이뤄지므로 단어의 순서를 반영
- 트랜스포머 모형은 순서를 다루는 구조가 없음
- 문장에서 단어의 위치를 인코딩하여 단어 임베딩에 더해줌
- 정현파를 이용하여 만들기도 하고, 단어 임베딩과 마찬가지로학습 시킬 수도 있음
비전 트랜스포머 Vision Transformer
- 트랜스포머를 컴퓨터 비전에 적용한 것
- 이미지를 패치(patch)로 쪼개어, 패치의 시퀀스로 다룸
- 자기 주의(self attention)는 순열 불변(permutation invariant)
- 입력 순서가 달라져도 출력이 같음
- 위치 인코딩을 함께 입력하여 순서 정보를 추가
귀납 편향 inductive bias
- 모형의 귀납 편향: 데이터의 구조에 대해 모형의 가정
- 예: CNN의 위치 등변성 translational equivariance: 입력의 위치가 바뀌면 출력의 위치도 똑같이 바뀜
- 머신러닝 모형은 이러한 가정 아래 훈련 데이터의 패턴을 일반화
- 편향-분산 교환(bias-variance trade-off)
- 편향이 강하면 분산이 작아짐
- 학습 데이터셋에 따라 결과가 크게 달라지지 않음
- 작은 데이터셋에서 성능이 좋음
- 편향이 약하면 분산이 커짐
- 학습 데이터셋에 따라 결과가 크게 달라짐
- 큰 데이터셋에서 성능이 좋음
CNN의 귀납 편향
- 국소성(locality): 필터는 국소적으로만 적용 → 전체 구조보다 무늬나 질감에 영향을 받음
- 변환불변성(transformation invariance): 필터는 모든 위치에 동일하게 적용되므로 물체의 위치가 변해도 영향을 받지 않음
- 계층적 구조(hierarchical structure): 국소적 특징을 점진적으로 결합하여 전역적 특징을 만듦
트랜스포머가 잘 작동하는 이유
- 딥러닝의 트랜스포머 모형이 최근 각광(예: ChatGPT 등)
- 기존의 딥러닝에서 널리 사용되던 CNN, RNN 등은 강한 편향
- CNN은 국소적 관계에 대해, RNN은 순차적 관계에 대해 강한 가정을 가짐
- RNN은 데이터를 순서대로 처리하므로 순서상 가까운 단어가 더 강한 영향
- 그러나 자연어는 반드시 순서대로 처리되는 것은 아님(예: 주술호응)
- 트랜스포머는 순서나 위치에 대한 가정이 없음 → 편향이 적음
- 데이터가 적은 분야(예: 희귀 질환 진단)에서는 트랜스포머 활용이 어려움
- 트랜스포머는 CNN에 비해 계산량이 많으나 GPU 구조상 병렬처리는 용이
- 트랜스포머의 계산 효율성을 높이거나 CNN과 결합하는 다양한 연구가 진행 중