
table of contents
- 이미지 처리 기법 정리
- 머신 비전 이미지 처리 툴박스 상세 가이드
- 전처리 1: 화질 및 색상 개선
- 전처리 2: 기하학적 변환 및 보정
- 특징 추출 준비: 노이즈 제거 및 형태 단순화
- Rule-based Vision: 고전적 특징 및 도형 추출
- Deep Learning Vision: 의미 기반 객체 인식 및 생성
- 머신 비전 기법 선택 의사결정 트리
- Step 1. 궁극적인 ‘목적’과 ‘환경’에 따른 큰 방향 결정
- Step 2. 화질 및 색상 개선 (전처리 1단계)
- Step 3. 기하학적 변환 및 왜곡 보정 (전처리 2단계)
- Step 4. 객체 분리 및 형태 단순화 (특징 추출 전 필수 단계)
- 플로우차트
- 머신 비전 이미지 처리 툴박스 상세 가이드
- 딥러닝 배경지식
- 이항 분류
- 모형 훈련
- 테스트
- 혼동 행렬
이미지 처리 기법 정리
머신 비전 이미지 처리 툴박스 상세 가이드
1. 전처리 1: 화질 및 색상 개선
조명이 균일하지 않거나, 전체적으로 뿌옇거나, 색상 구분이 어려울 때 시각적 특징을 명확히 하기 위해 가장 먼저 수행하는 작업입니다.
- 히스토그램 균일화 (Histogram Equalization)
- 상황: 전반적으로 대비가 낮아 뿌옇게 보이는 이미지를 선명하게 만들고 싶을 때.
- 주의점: 흑백 이미지에 바로 적용하면 어두운 곳은 너무 어두워지고 밝은 곳은 너무 밝아져 디테일이 날아갈 수 있습니다. 컬러 이미지의 경우 BGR 상태에서 바로 적용하면 색상 비율이 왜곡되므로, HSV 컬러 스페이스로 변환한 뒤 명도(V) 채널에만 적용해야 원래 색상을 유지하며 선명해집니다.
- CLAHE (Contrast Limited Adaptive Histogram Equalization)
- 상황: 엑스레이(X-ray) 사진의 갈비뼈처럼 디테일한 윤곽을 살리면서 전체적인 명암 대비를 높이고 싶을 때.
- 효과: 이미지를 여러 타일로 나누어 국소적으로 균일화를 수행하므로 일반 히스토그램 균일화의 단점(디테일 뭉개짐)을 극복합니다.
- 감마 보정 (Gamma Correction) / LUT (Look-Up Table)
- 상황: 역광으로 찍힌 사진처럼 일괄적으로 밝기를 높이면 하얗게 날아가 버릴 때.
- 효과: 감마 함수를 이용해 비선형적으로 밝기를 보정합니다. (감마 < 1: 어두운 곳을 더 밝게, 감마 > 1: 밝은 곳을 더 어둡게).
- 특정 색상 추출 (크로마키)
- 상황: 녹색 배경(크로마키)이나 특정 색상의 물체(예: 파란색 풍선)만 누끼를 따고 싶을 때.
- 방법: BGR 이미지를 빛의 영향을 덜 받는 HSV로 변환한 뒤, 특정 색상(Hue) 범위만 남기는 마스크(Mask)를 생성하여 분리합니다.
2. 전처리 2: 기하학적 변환 및 보정
객체의 크기를 맞추거나 렌즈 및 각도로 인해 왜곡된 형태를 바르게 펴기 위해 사용합니다. (규칙 기반의 수학적 연산).
- 아핀 변환 (Affine Transform)
- 상황: 이미지를 평행 이동, 크기 조절, 회전, 기울이기(전단)를 해야 할 때.
- 효과/조건: 3개의 기준점만 있으면 변환이 가능하며, 변환 후에도 원래 직선이었던 곳은 직선으로, 평행했던 선은 평행하게 유지됩니다.
- 투시 변환 (Perspective Transform / Homography)
- 상황: 비스듬히 찍힌 신분증, 체스보드, 문서 등을 정면에서 수직으로 내려다본 것처럼 반듯하게 펴고 싶을 때.
- 효과/조건: 원근감을 조정하며, 아핀 변환보다 자유도가 높습니다. 4개의 기준점이 필요합니다.
- 카메라 렌즈 왜곡 교정
- 상황: 어안 렌즈나 광각 렌즈로 촬영하여 직선이 볼록하게 휘어져 보일 때.
- 방법: 체커보드 패턴을 여러 장 촬영하여 교차점을 찾은 뒤(findChessboardCorners), 교정치 행렬을 계산하여 이미지를 평평하게 복구합니다.
3. 특징 추출 준비: 노이즈 제거 및 형태 단순화
윤곽선이나 특징을 찾기 전, 자잘한 잡음을 없애고 물체의 형태를 하나로 깔끔하게 묶어주는 필수 과정입니다.
- 공간 필터링 (가우시안 블러 등)
- 상황: 이미지에 자잘한 잡음(고주파 영역)이 많아 경계선 검출이 방해받을 때.
- 효과: 가우시안 분포를 이용해 중심은 많이, 주변은 적게 반영하여 이미지를 자연스럽게 흐리게(Blur) 뭉개서 노이즈를 제거합니다.
- 이진화 (Binarization - Otsu, Adaptive)
- 상황: 물체와 배경을 흑백(0과 1)으로 명확히 나누고 싶을 때.
- 방법:
- Otsu 알고리즘: 이미지 전체의 명암 분포를 보고 가장 적절한 문턱값을 ‘자동’으로 찾아줍니다.
- Adaptive Thresholding: 조명이 한쪽에만 비춰 불균일한 문서(예: 그림자가 진 스도쿠 퍼즐)에서 이미지를 타일로 나누어 이진화합니다.
- 모폴로지 연산 (Morphology)
- 상황: 이진화된 흑백 이미지에서 끊어진 글씨를 잇거나, 구멍을 메우거나, 잔점들을 지우고 싶을 때.
- 종류:
- 침식(Erosion): 이미지를 깎아내어 자잘한 점 노이즈 제거.
- 팽창(Dilation): 이미지를 찌워서 끊어진 선이나 안쪽 구멍을 채움.
- 열림(침식→팽창): 밝은 노이즈 제거.
- 닫힘(팽창→침식): 어두운 노이즈 제거.
4. Rule-based Vision: 고전적 특징 및 도형 추출
명확한 수학적 규칙이 있는 기하학적 도형을 찾거나, 복잡한 딥러닝 없이 빠르고 가볍게 동일 물체를 추적하고 싶을 때 사용합니다.
- 에지 검출 (Sobel, Canny)
- 상황: 배경은 무시하고 물체의 테두리(윤곽선) 라인만 스케치하듯 따내고 싶을 때.
- 효과: 화소 밝기가 급변하는 고주파 영역을 추출합니다. 노이즈 제거(블러) -> 소벨 커널 엣지 검출을 합친 Canny 알고리즘을 주로 씁니다.
- 허프 변환 (Hough Transform)
- 상황: 도로의 차선(직선)을 검출하거나, 이미지 내의 동전이나 공(원)을 찾아야 할 때.
- 조건: 에지가 검출된 윤곽선 이미지 위에서 점들을 지나는 수학적 방정식(직선, 원)을 찾아냅니다.
- 이미지 매칭 (ORB 등)
- 상황: 완전히 똑같이 생긴 물체(예: 같은 장난감)가 다른 각도에서 찍힌 두 사진에서 서로 같은 객체임을 매칭하고 싶을 때.
- 효과: 각 이미지에서 특징점(Keypoint)과 그 주변의 지문 역할인 디스크립터(Descriptor)를 추출한 뒤, 유사도를 비교합니다.
5. Deep Learning Vision: 의미 기반 객체 인식 및 생성
CCTV, 자율주행, 얼굴 잠금 해제 등 형태가 다양하고 규칙으로 묶기 힘든 사물을 탐지하거나 의미를 분석해야 할 때 사용합니다. GPU 및 대량의 데이터(또는 사전 학습 모델)가 필요합니다.
- 물체 탐지 (Object Detection - YOLO 계열)
- 상황: 하나의 이미지 안에 여러 종류의 물체(사람, 차, 신호등 등)가 섞여 있고, 그 위치(박스)와 종류를 실시간으로 빠르게 알아내야 할 때.
- OBB(Oriented Bounding Box): 항공 사진의 선박이나 기울어진 바코드처럼 피사체가 대각선으로 누워있어 기존의 직사각형 박스(AABB)로 잡기 힘들고 서로 겹칠 때 각도까지 탐지합니다.
- 광학 문자 인식 (OCR)
- 상황: 영수증, 인보이스, 신분증 사진 등에서 텍스트 영역을 찾고 실제 글자(디지털 텍스트)로 변환할 때 (예: PaddleOCR 활용).
- 자세 추정 (Pose Estimation)
- 상황: 사람의 동작을 분석하여 운동 자세를 교정하거나, CCTV에서 폭력/이상 행동을 감지해야 할 때 사람의 관절 특징점 위치를 찾아냅니다.
- 이미지 임베딩 (얼굴 인식 등)
- 상황: 스마트폰 얼굴 잠금 해제처럼 매번 모습이 달라도 ‘같은 사람’인지 식별하거나, 비슷한 옷 디자인을 검색하고 싶을 때.
- 효과: 대조 손실(Contrastive loss) 등을 이용해 비슷한 이미지는 가까운 좌표 벡터(임베딩)로 변환한 뒤, 코사인 유사도로 빠르게 검색/비교합니다.
- 이미지 생성 및 변환 (GAN, Diffusion)
- 상황: 텍스트를 입력해 없는 이미지를 만들어내거나, 흐릿한 저화질 이미지를 고화질로 복원(Super Resolution)하고, 스케치를 실사 사진으로 바꾸고 싶을 때 사용합니다.
머신 비전 기법 선택 의사결정 트리
Step 1. 궁극적인 ‘목적’과 ‘환경’에 따른 큰 방향 결정
Q1. 찾고자 하는 대상이 무엇인가?
- 형태가 복잡하고 다양하거나 의미 기반의 인식(사람, 동물, 얼굴, 특정 종류의 차량 등)이 필요한가?
- 데이터와 연산 자원(GPU 등)이 충분한가?
- Yes: 딥러닝 기반 모델 직접 학습 (예: CNN 기반 이미지 분류).
- 데이터가 적거나 빠른 개발이 필요한가?
- Yes: 사전 학습된 모델을 활용하는 전이 학습(Transfer Learning) 사용 (예: YOLO).
- 물체가 비스듬하게 누워있거나 서로 겹쳐서 빽빽하게 있나?
- Yes: 일반적인 직사각형 박스(AABB) 대신, 회전된 각도까지 탐지하는 OBB(Oriented Bounding Box) 활용.
- 이미지 내의 ‘텍스트’를 추출해야 하나?
- Yes: OCR(광학 문자 인식) 적용.
- 데이터와 연산 자원(GPU 등)이 충분한가?
- 명확한 기하학적 규칙이 있거나 완전히 동일한 패턴/물체를 찾아야 하나? (고정된 알고리즘 사용 가능)
- 차선 등 명확한 직선이나 원을 찾아야 하나?
- Yes: 에지 검출 후 허프 변환(Hough Transform) 적용.
- 서로 다른 각도에서 찍힌 완전히 동일한 물체를 매칭해야 하나?
- Yes: ORB 등을 이용해 특징점(Keypoint)과 디스크립터(Descriptor)를 추출한 뒤 특징 매칭(Feature Matching) 수행.
- 차선 등 명확한 직선이나 원을 찾아야 하나?
Step 2. 화질 및 색상 개선 (전처리 1단계)
특징을 잘 추출하기 위해 시각적 정보를 뚜렷하게 만듭니다.
Q2. 이미지의 밝기나 명암에 문제가 있나?
- 이미지가 전체적으로 뿌옇고 명암 대비가 낮나?
- 컬러 이미지인가?
- Yes: 색상 왜곡을 막기 위해 HSV 컬러 스페이스로 변환한 후, 명도(V) 채널에만 히스토그램 균일화 적용 후 BGR로 원복.
- X-ray처럼 질감과 디테일 유지가 중요한가?
- Yes: 전체 균일화 대신 이미지를 타일로 나누어 처리하는 CLAHE 적용.
- 컬러 이미지인가?
- 역광이거나 이미지가 일괄적으로 너무 어둡거나 밝나?
- Yes: 감마 보정 적용 (어두운 곳을 밝히려면 감마 < 1, 밝은 곳을 억누르려면 감마 > 1).
- 특정 색상(예: 크로마키 배경, 특정 물체 색상)만 분리해야 하나?
- Yes: BGR을 HSV로 변환한 뒤, 특정 색상 범위를 지정해 마스크(Mask)를 만들고 비트와이즈(Bitwise) AND 연산 수행.
Step 3. 기하학적 변환 및 왜곡 보정 (전처리 2단계)
카메라의 렌즈 왜곡이나 촬영 각도 문제를 해결합니다.
Q3. 이미지의 형태나 구도가 틀어져 있나?
- 볼록하거나 오목한 렌즈 왜곡(어안 렌즈 등)이 있나?
- Yes: 체커보드 패턴을 이용해 교차점을 찾고 카메라 왜곡 교정(Calibration)을 수행하여 이미지를 평평하게 복구.
- 비스듬하게 찍힌 문서, 신분증, 체스보드 등을 정면에서 본 것처럼 반듯하게 펴야 하나?
- Yes: 4개의 기준점을 바탕으로 원근감을 조정하는 투시 변환(Perspective Transform / Homography) 적용.
- 단순히 평행 이동, 크기 조절, 회전, 기울이기만 필요한가?
- Yes: 3개의 기준점만으로 평행성을 유지하며 변환하는 아핀 변환(Affine Transform) 적용.
Step 4. 객체 분리 및 형태 단순화 (특징 추출 전 필수 단계)
컴퓨터가 물체의 경계와 형태를 쉽게 연산할 수 있도록 불필요한 정보를 날립니다.
Q4. 본격적인 윤곽선이나 특징을 찾기 전, 잡음(노이즈)이 많나?
- 이미지에 자잘한 고주파 노이즈가 많나?
- Yes: 윤곽선을 추출하기 전 가우시안 블러(Gaussian Blur) 등의 공간 필터링을 적용해 노이즈를 먼저 뭉개줌.
Q5. 배경을 없애고 물체를 흑/백으로 명확히 나눠야 하나? (이진화)
- 이미지 전체의 조명이 고르고 균일한가?
- Yes: 명암 분포를 보고 자동으로 적절한 문턱값을 찾는 Otsu의 이진화 알고리즘 적용.
- 그림자가 지거나 조명이 한쪽에만 비춰 불균일한가? (예: 스캔된 문서)
- Yes: 이미지를 여러 타일로 나누어 국소적으로 이진화를 수행하는 Adaptive Thresholding 적용.
Q6. 이진화를 했는데 물체의 모양이 깔끔하지 않나? (모폴로지 연산)
- 이진화된 물체 내부에 구멍이 뚫려 있거나, 글씨의 획이 끊어져 있나?
- Yes: 이미지를 찌우는 팽창(Dilation) 연산이나 닫힘(Closing) 연산 적용.
- 물체 주변 배경에 자잘한 점 노이즈들이 떠다니나?
- Yes: 이미지를 깎아내는 침식(Erosion) 연산이나 열림(Opening) 연산 적용.
플로우차트
딥러닝 배경지식
- 넘파이, 판다스, 사이킷런: 파이썬 머신러닝 3신기.
GPU
- 보통 일반적인 계산은 CPU가 함. 이름도 중앙처리장치임.
- 근데 일반적이고 다양한 일을 하는 게 목적이니 단순반복계산 최적은 아님
- 병렬 처리도 안됨 1코어 1계산이라고 봐야 함
- 딥러닝은 GPU를 쓴다
- GPU(그래픽 처리 장치): 원래는 게임 등에서 컴퓨터 그래픽을 처리하는데 특화된 장치
- GPU는 대량의 단순 계산을 병렬로 실행
- 여러 가지 계산을 순서대로 하는 것이 아니라 따로 따로 계산한 다음에 합칠 수 있음
- 개인용 PC에서 CPU에 있는 코어 개수는 많아야 열 몇 개 vs. 최신 GPU에는 몇 만 개의 코어
- 그래픽(머신 비전, 그래픽 작업 등)도 딥러닝과 같이 단순 계산이 많음
- 동시에 여러 가지 계산을 할 수 있는 GPU를 활용하면 높은 성능을 낼 수 있음
기억 장치 memory
- 메모리도 종류가 있다
- 레지스터(register): CPU 내부의 기억장치. 작고 빠름. 사람 손가락 정도의 기억력임. 손가락 덧셈 다들 해봤잖아.
- 캐시 메모리(cache memory): CPU와 RAM 사이에 있음. 컨닝페이퍼임.
- RAM: 컴퓨터가 켜져 있는 동안만 내용이 유지되는 주 기억장치. 끄면 깔끔하게 지워짐. 임시 메모장.
- 스토리지: HDD 또는 SSD. 매우 크고 느리지만, 컴퓨터 꺼도 내용 유지. 보통 사용자가 뭐 다운받고 저장하고 하는 그 메모리임. 요즘은 테라 단위로 많이 쓰잖아.
- VRAM: GPU의 RAM
- Mac의 AppleSilicon은 RAM과 VRAM이 통합 ← 맥미니가 그래서 잘 팔렸잖아
- 딥러닝 모델 구동을 위해서는 VRAM 용량이 중요 ← 진짜,, ㄹㅇ 중요한데 이거 큰 거 사려면 돈이 많이 들어 파이토치가 특히 메모리를 의리없이 잡아먹음
- 용량 계산 방법: 파라미터 수 × 자료형 크기(예: LLaMA3 70B 모델 = 약 48GB 필요)
딥러닝 프레임워크
- GPU 지원 + 딥러닝 모델을 정의하고 학습시키는데 필요한 다양한 기능들을 제공
- 제공하면 뭐해 CUDA 버전 좀 통일해서 쓰라고 왜 다 다른 걸 쓰는건데
- 텐서플로 TensorFlow
- 구글이 개발, 가장 높은 점유율, 기업용 기능이 많음
- 입문할 때 쓰기에 적당하고, 개인적으로 모델을 커스텀하기 조금 더 편하다고 봄
- 파이토치 PyTorch
- 페이스북이 개발, 새로운 모형을 만들기 편리하여 학계에서 인기
- 라고는 하는데 이름난 모델 빠르게 갖다 쓰긴 좋지만 직접 빌드하기엔 영 그 맛이 아님
- 작스 jax
- 다양한 수학 계산을 최적화하여 빠르게 실행하는데 초점
- 딥러닝도 구현할 수 있음 ← ‘할 수 있다’라고 표현한다는 건 원래 이런 거 하라고 있는 게 아니라는 말이다 일단 난 jax라는 걸 지금 처음 봤음
- 케라스 Keras
- 여러 딥러닝 프레임워크를 같은 방법으로 편하게 사용할 수 있도록 하는 라이브러리
- 텐서플로, 파이토치, 작스 모두 지원
- 그러니까 인터페이스라는 말이죠
모델 가용성 Model Availability
- 더 크고 복잡한 최신 모델이 계속해서 발표, 모든 모델을 직접 구현하기는 어려움. 해당 프레임워크로 이미 구현된 모델을 쉽게 구할 수 있는 지가 중요
- 최신 모델 가용성에서는 파이토치가 압도적으로 우세
- 학술지 발표 논문 중 80%가 파이토치를 사용
- 코드 공개 사이트 Papers With Code에서 파이토치 코드가 60%
- 모델 공유 사이트 HuggingFace에서 파이토치만 지원하는 모형이 85%
- 구글, 딥마인드 등의 기업 및 강화학습 등의 분야에서는 텐서플로가 우위
- 사실 텐서플로나 파이토치나 직접 모델을 빌드하고자 한다면 코드만 다를 뿐 기능은 거의 똑같이 쓸 수 있긴 함 이것저것 써보고 목적이나 선호에 따라서 잘 골라서 쓰기
배포 인프라 deployment infrastructure
- 모델을 실제 비즈니스 환경에서 효율적으로 사용할 수 있는 것이 중요
- 모델 개발은 Python으로 하지만, 운용시에도 사용하기에는 느림
- 텐서플로는 서버, 모바일, 웹 등 다양한 환경에서 빠르게 실행 가능
- 파이토치도 관련 기능을 따라잡고 있으나, 텐서플로가 여전히 우위
- 오디오, 비디오 등의 기능도 텐서플로
- 기업 채용 공고는 텐서플로가 더 많음
GPU 클라우드
- 딥러닝 모형의 미세 조정을 위해서는 고성능 GPU가 필요
- 직접 딥러닝 워크스테이션을 구축 ← 보통 비싸지만 한번 사면 계속 내 거임.
- GPU 클라우드 사용 ← 원하는 사양 정도에 따라 쌀수도 있고 비쌀수도 있음. 지속적인 지출 발생.
- GPU 클라우드: runpod.io, lambdalabs.com, vast.ai, fluidstack.io, coreweave.com
- 구글 colab: 구글에서 제공하는 Python 서비스
- 무료로 고성능의 서버에서 머신러닝 모형을 돌릴 수 있음 ← 당연히 사용량 제한 있는데 학습 프로젝트 수준에서는 부족함이 없을 것
이항 분류
MNIST
- 딥러닝 처음 시작하면 다들 한번씩 거쳐가는 그 유명한 손글씨
데이터 가져오기
1
2
3
4
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
print("Training data shape:", x_train.shape)
print("Training labels shape:", y_train.shape)
이항 분류와 다항 분류
- 다항 분류: 셋 이상 중에 하나로 분류하는 것(MNIST는 10가지로 분류하는 다항 분류 데이터셋)
- 이항 분류: 둘 중에 하나로 분류하는 것
- 이항 분류를 위해 0과 1만 뽑음
- 이항 분류를 할 때는 항상 레이블이 0과 1이어야 함
- 3과 4를 뽑으면 3 → 0, 4 → 1로 레이블을 바꿔야 함
이항 분류 데이터 준비
1
2
3
4
5
6
7
import numpy as np
def filter_binary(x, y, neg_cls, pos_cls):
cond = (y == neg_cls) | (y == pos_cls)
x_bin = x[cond]
y_bin = np.where(y[cond] == neg_cls, 0, 1)
return x_bin, y_bin
x_train_binary, y_train_binary = filter_binary(x_train, y_train, 0, 1)
- Binary Training Data Sample
- Shape of x_train_binary: (12665, 28, 28)
- Shape of y_train_binary: (12665,)
모형 정의
1
2
3
4
5
6
7
model = keras.models.Sequential([ # 딥러닝 모형의 구성 요소를 순서대로 정의
keras.layers.Rescaling(1/255), # 입력 값의 범위를 0~255에서 0.0 ~ 1.0으로
keras.layers.Flatten(), # 이미지 평탄화
keras.layers.Dense(1, activation='sigmoid') # 이미지마다 1개의 출력
])
model.summary()
Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ rescaling_1 (Rescaling) │ ? │ 0 (unbuilt) │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten_1 (Flatten) │ ? │ 0 (unbuilt) │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_1 (Dense) │ ? │ 0 (unbuilt) │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 0 (0.00 B)
Trainable params: 0 (0.00 B)
Non-trainable params: 0 (0.00 B)
모델 구성
- 입력값 스케일링: 0~255 색깔을 0~1 색깔로
- 평탄화: 2D → 1D
- dense: 실질적인 계산 층. 활성함수는 시그모이드 사용함.
Dense
- 선형 모형
y = wx + b형태의 레이어 - 모든 입력에 대해 가중치 w를 곱하고, 편향 b를 더함
- Fully Connected라고도 함
- $[-\infty, +\infty]$ 를 출력
- 이항 분류 문제이므로 0 또는 1로 출력을 해야 함 → 활성화 함수(activation function)
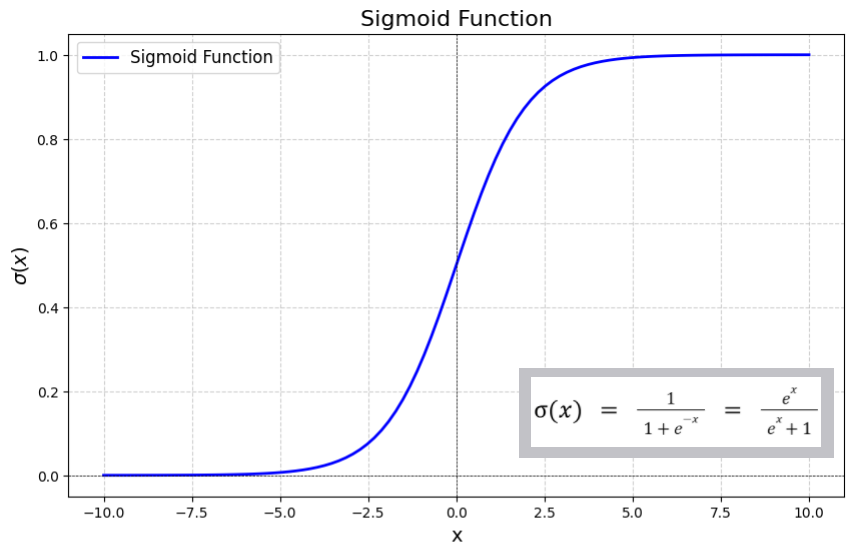
시그모이드 함수 sigmoid function
- 출력층에서 0~1 사이의 출력을 표현하기 위해 사용
- S자(sigma)를 닮은(oid)이라는 뜻
- 계단 함수는 미분불가능하므로 점진적 학습이 어려움
- 0~1 사이에서 매끄럽게 변하는 함수
- 출력은 확률로 해석 (예: 0.8 → 1일 확률이 80%)
- 통계에서는 로지스틱(logistic) 함수라고 부름
모형 훈련
훈련
1
2
3
4
5
6
7
8
# 훈련 설정
model.compile(
optimizer=keras.optimizers.SGD(learning_rate=0.0001),
loss='binary_crossentropy', metrics=['accuracy']
)
# 훈련
history = model.fit(x_train_binary, y_train_binary, epochs=5, batch_size=32)
손실 함수 loss function
- 비용 함수 cost function 또는 오차 함수 error function라고도 함
- 예측과 실제의 차이를 계산
- 손실 ≥ 0
- 손실을 최소화할 수록 성능이 개선
MSE mean squared error
- 오차 제곱의 평균(오차 = 실제 - 예측)
- 연속변수의 예측에 사용
- 이상치(outlier)에 민감
교차 엔트로피 cross entropy
- 두 확률 분포의 차이를 계산: 분포를 똑바로 예측했을 때 페널티가 적음
- 범주형 변수의 예측에 사용
- p와 q 두 확률 분포가 비슷할 수록 작아짐
- 높은 확률로 예측했을 때 맞고, 낮은 확률로 예측했을 때 틀려야 감소
경사하강법 gradient descent
- 기존의 파라미터를 바탕으로 예측 $\hat{y}$을 출력
- $L(y, \hat{y})$: 실제 y와 비교하여 손실을 계산
- 손실을 줄이는 방향으로 파라미터를 수정
- 위의 과정을 반복
경사하강법의 문제점
- 한 단계의 가중치 수정을 위해 전체 데이터셋에 대해 계산
- 국소최소점(local minima: 근방에서만 최소인 점)에 수렴
- 안장점(saddle point: 경사가 0이지만 최소나 최대가 아닌 점)에서 업데이트 불가
학습률 learning rate
- 파라미터는 한 번에 $\text{경사} \times \text{학습률}$만큼 수정
- 경사가 0에 가까울 수록 오차는 최소에 가까워짐
- 경사에 비례하여 수정할 크기를 조정
- 학습률이 크면 학습이 빠르지만 최소점 근처에서 수렴하지 않을 수 있음
확률적 경사하강법 Stochastic GD
- 하나의 사례를 바탕으로 경사를 계산
- 극소점을 향해 바로 가지 않고 지그재그로 이동하게 됨
- 한 번의 업데이트를 위한 계산량이 적음
- 국소최적화를 피할 가능성이 있음
- 업데이트 방향이 불안정하므로 더 많은 업데이트가 필요할 수 있음
모멘텀
- 파라미터에 경사를 직접 더하는 대신, “속도”에 경사를 반영
- 파라미터는 속도에 따라 변화
- 장점
- 국소 최적에서 벗어나는데 도움이 됨
- 진동을 억제하는 효과
미니배치(Mini-batch) 경사하강법
- 전체 데이터의 일부(=미니배치)만을 사용하여 경사하강법
- 경사하강법과 확률적 경사하강법의 장점을 융합
- 일반적으로 확률적 경사하강법이라고 하면 실제로는 미니배치 경사하강법을 가리킴
테스트
과소/과대 적합
- 과소적합(underfitting): 실제 패턴보다 모형이 단순
- 과대적합(overfitting): 실제 패턴보다 모형이 복잡
데이터 분할
- 데이터를 Training과 Testing으로 분할 (보통 8:2 또는 9:1)
- 파라미터를 추정하는데는 많은 데이터가 필요하므로 Training을 크게
- Testing은 모형들의 성능을 구별할 정도만 되면 충분하므로 작게
- Training에 과적합되면 Testing에서 성능이 낮아짐
- Training과 Testing의 데이터가 섞이지 않도록 유의
과적합의 진단
- training set에서는 성능이 높지만 testing set에서는 성능이 낮을 경우
- overfitting 되었을 가능성이 높음
- 모형의 복잡도를 낮추는 방향으로 구조/하이퍼파라미터를 조정
- training set에서도 성능이 낮을 경우
- underfitting이 되었을 가능성이 높음
- 모형의 복잡도를 높이는 방향으로 구조/하이퍼파라미터를 조정
테스트
테스트 데이터 뽑아서 평가시키기 (이항 분류 하고 있으니 0, 1만 뽑는다는 점 참고)
1
2
3
x_test_binary, y_test_binary = filter_binary(x_test, y_test, 0, 1)
model.evaluate(x_test_binary, y_test_binary)
직접 손글씨 입력해보기
- 그림판에서 직접 손글씨 입력
- 크기 조정(픽셀, 28, 28, 가로세로 비율 X)
- 오른쪽 하단 확대/축소로 확대
- 색 채우기 (검은색)
- 브러시(색 1 → 흰 색)
- 검은 바탕에 흰 글씨로 0 또는 1
- hand.png로 저장
손글씨 이미지 예측시키기
1
2
3
4
5
6
import cv2 as cv
x = cv.imread('../data/hand.png', cv.IMREAD_GRAYSCALE) # 이미지 불러오기
x = np.expand_dims(x, axis=0) # 배치 차원 추가
model.predict(x) # 예측
0에 대각선으로 표시된 모노스페이스 글꼴(0)로 써서 예측시켰더니 1이라더라. 데이터셋에 0에다가 대각선 긋는 사람은 없었나보죠?
차원 추가 방법
expand_dims
1
np.expand_dims(x, 0) # 0번 차원 확장
new_axis
1 2 3
x[np.newaxis, 0:28, 0:28] # 0번 차원에 새 축, 1, 2차원은 0~28번값 x[np.newaxis, :, :] # 0번 차원에 새 축, 1, 2차원은 모든 값 x[np.newaxis, ...] # 0번 차원에 새 축, 다른 차원은 모든 값
reshape
1
x.reshape(1, 28, 28) # 모양을 1, 28, 28로 변경
혼동 행렬
Fashion MNIST
이번엔 글씨 말고 옷임. 일부러 좀 어렵게 스웨터와 셔츠를 이항 분류하게 시켜보겠다.

데이터 가져오기
1
2
3
4
5
import os
os.environ["KERAS_BACKEND"] = "torch"
import keras
(x_train, y_train), (x_test, y_test) = keras.datasets.fashion_mnist.load_data()
학습
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 스웨터(2)와 셔츠(6)
x_train_binary, y_train_binary = filter_binary(x_train, y_train, 2, 6)
x_test_binary, y_test_binary = filter_binary(x_test, y_test, 2, 6)
model = keras.models.Sequential([
keras.layers.Rescaling(1/255),
keras.layers.Flatten(),
keras.layers.Dense(1, activation='sigmoid')
])
model.compile(
optimizer=keras.optimizers.SGD(learning_rate=0.01),
loss='binary_crossentropy', metrics=['accuracy']
)
history = model.fit(x_train_binary, y_train_binary, epochs=5, batch_size=32)
평가
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import numpy as np
from sklearn.metrics import * # sklearn.metrics 모듈에서 모든 함수 불러오기
threshold = 0.5 # 문턱값
y_prob = model.predict(x_test_binary) # 예측 확률
y_pred = np.where(y_prob >= threshold, 1, 0) # 문턱값보다 크면 1 아니면 0
y_true = y_test_binary # 실제 정답
confusion_matrix(y_true, y_pred) # 혼동행렬(정답, 예측 순)
'''
array([[814, 186],
[169, 831]])
'''
혼동 행렬 confusion matrix
| 예측 음성 (0) | 예측 양성 (1) | |
|---|---|---|
| 실제 음성 (0) | TN | FP |
| 실제 양성 (1) | FN | TP |
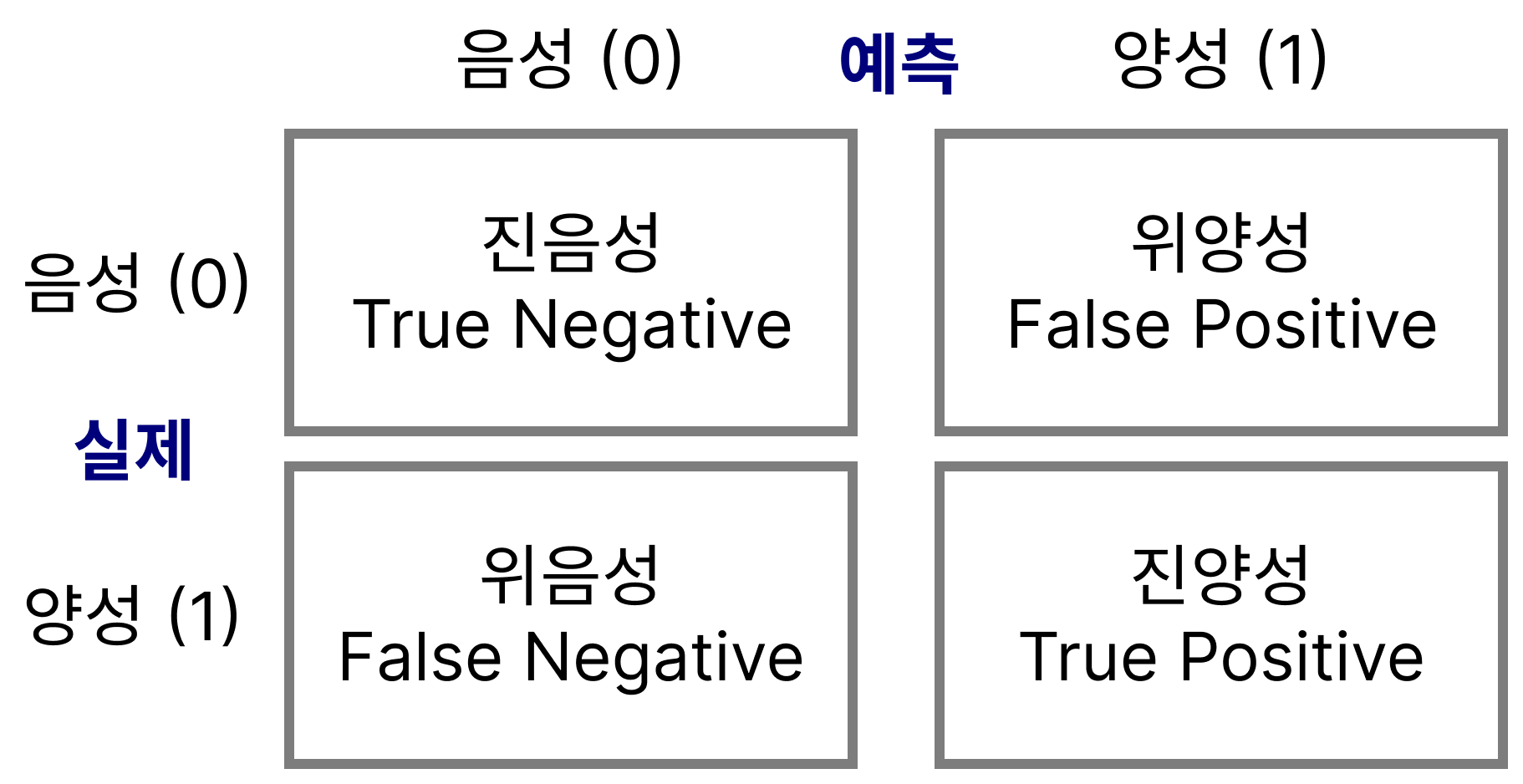
진/위 양성/음성
- 혼동행렬에서 양성/음성은 예측을 기준으로 말함
- 현실에서는 실제로 어떤지 알 수 없는 경우가 많음
- 진(True) → 예측이 맞음
- 위(False) → 예측이 틀림
정확도 accuracy
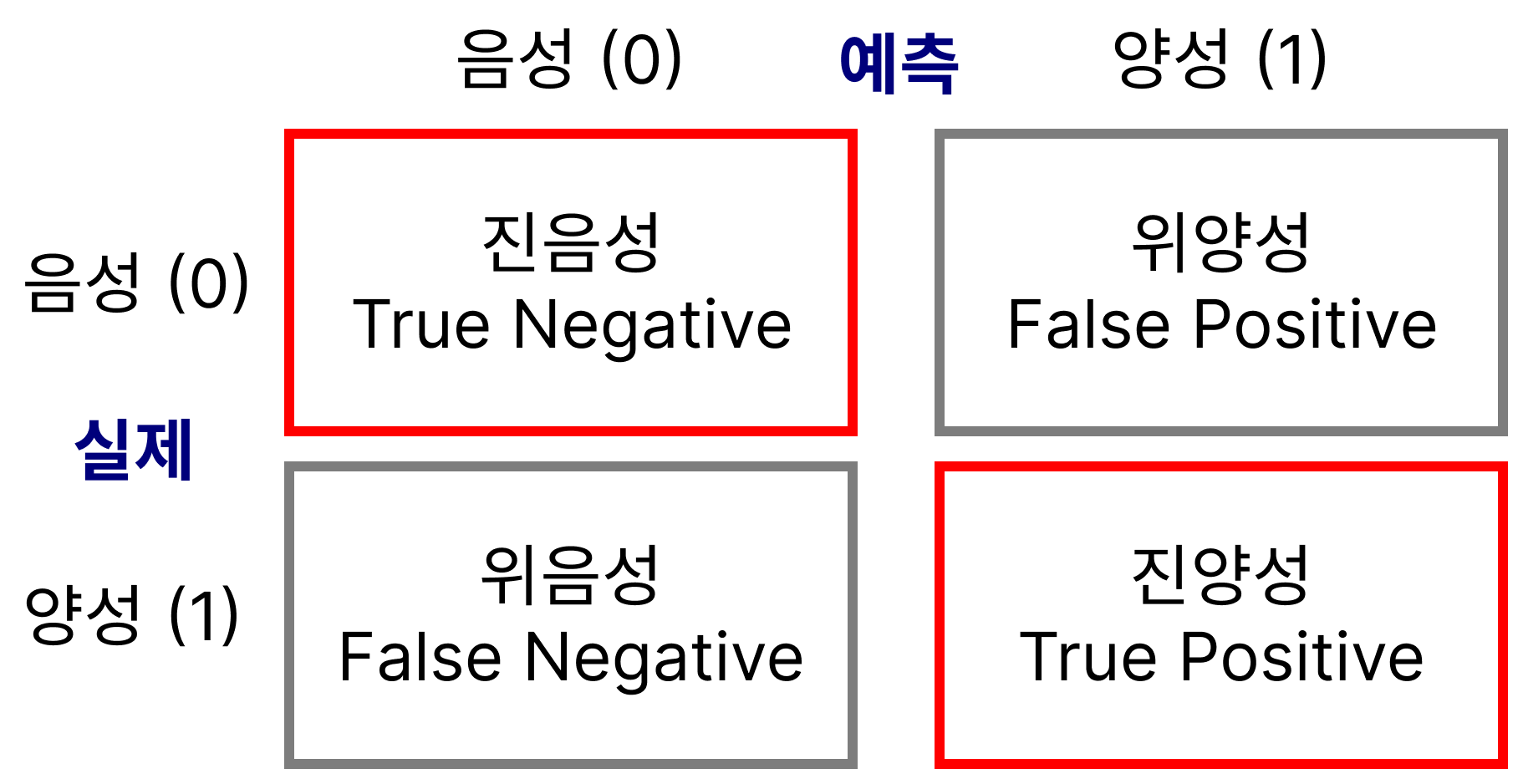
- 전체 중에 예측이 맞은 비율
(TP + TN) / 전체 - 특별히 음성/양성 구분에 관심이 없는 경우 사용
- 그러나 대부분은 양성에 더 관심이 있음
1
accuracy_score(y_true, y_pred)
정밀도 precision
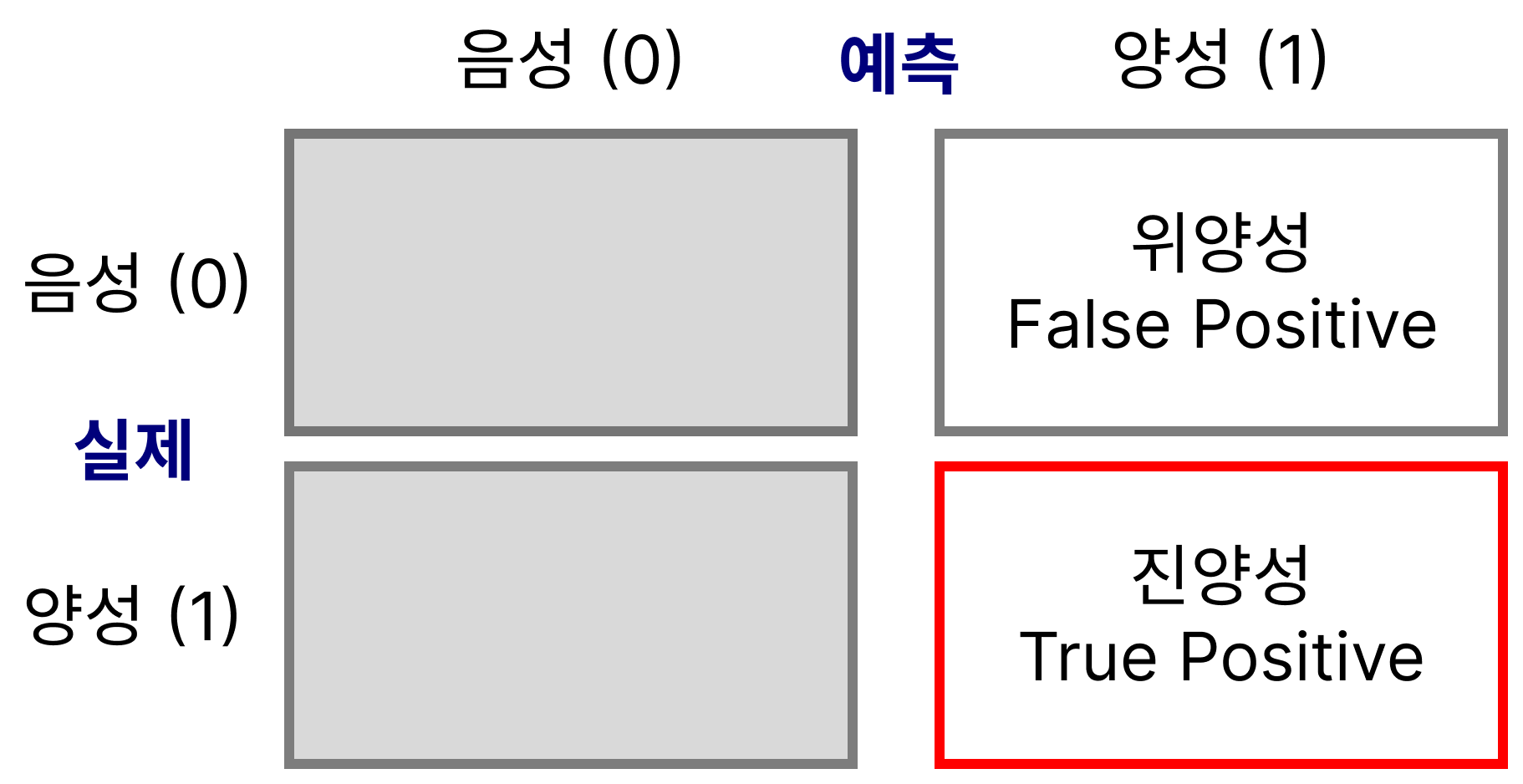
- 양성 예측 중에 맞은 비율
TP / (TP + FP) - 양성 예측이 중요한 경우 (예: 채용, 투자, 추천, 결혼 등)
1
precision_score(y_true, y_pred)
재현도 recall
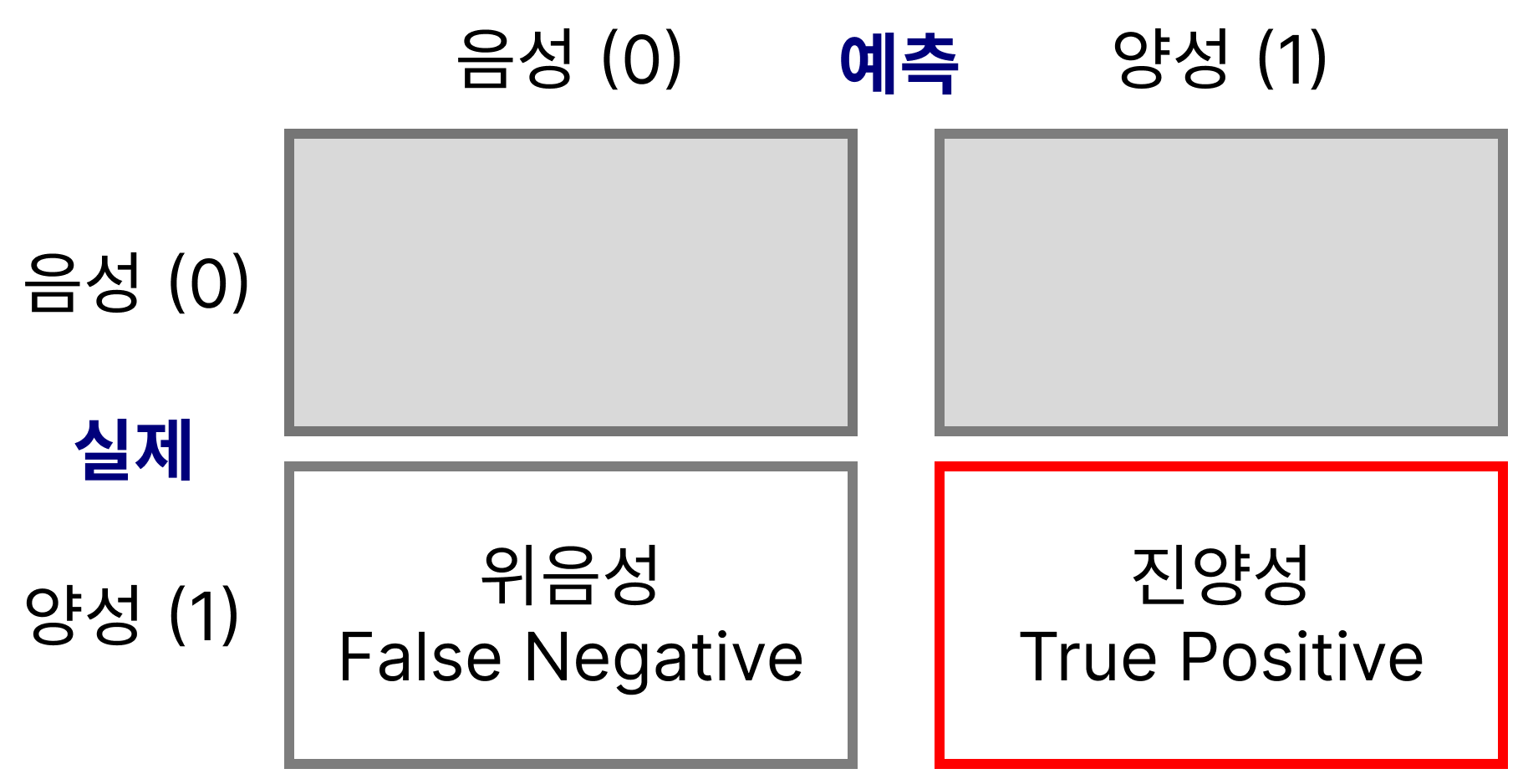
- 실제 양성 중 찾아낸 비율
TP / (TP + FN) - 양성을 찾아 내는 것이 중요한 경우 (예: 방역)
- 의학 등에서는 민감도(specificity)라고도 함
- 또는 TPR(True Positive Rate)
1
recall_score(y_true, y_pred)
특이도 specificity
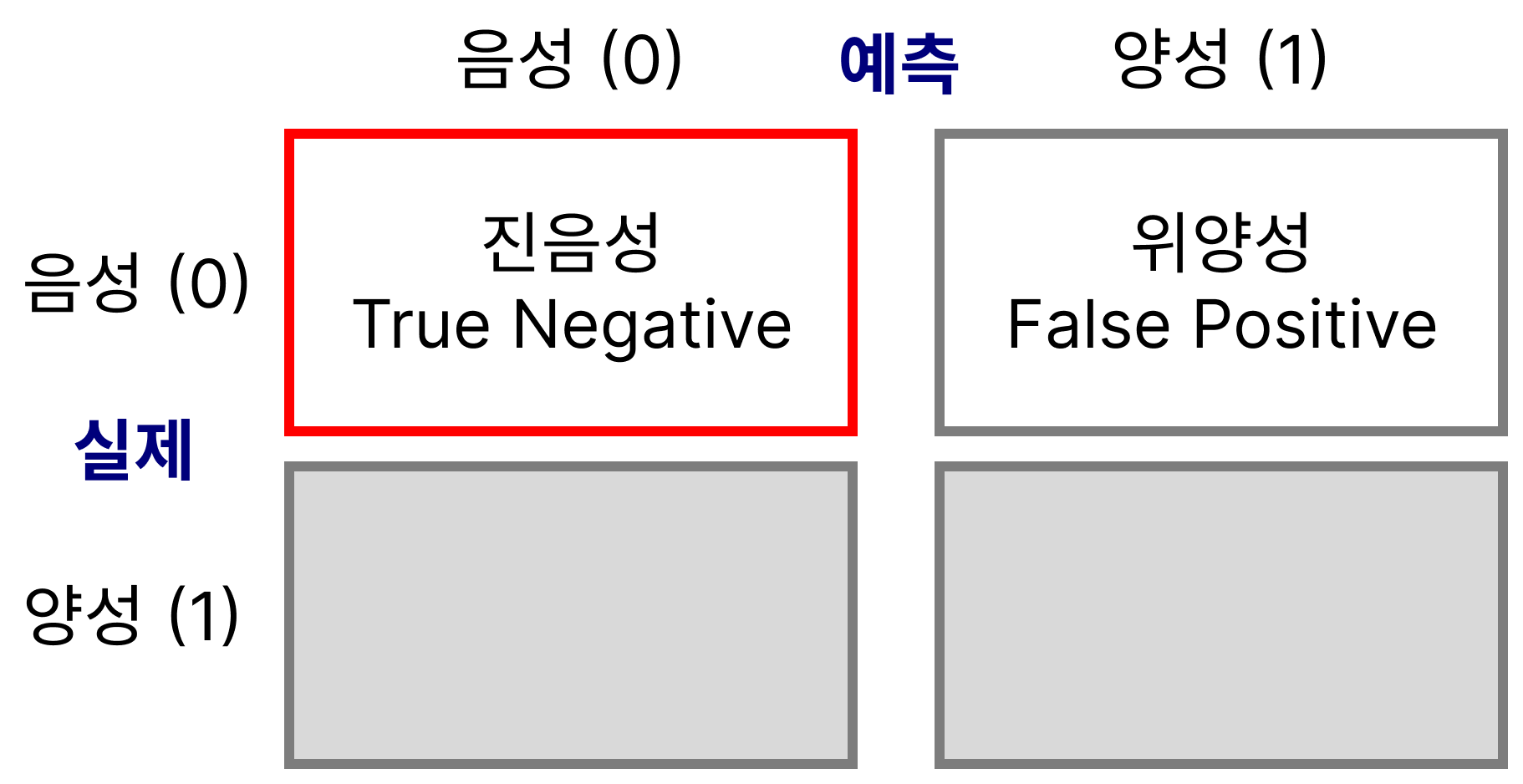
- 실제 음성 중 찾아낸 비율
TN / (TN + FP) - 음성을 찾아 내는 것이 중요한 경우 (예: 방역)
- 대체로 양성 예측을 보수적으로 하면 특이도가 높아진다
- FPR(False Positive Rate):
FP / (TN + FP) = 1 - specificity
1
recall_score(y_true, y_pred, pos_label=0)
특이도가 낮을 경우 문제점
- 질병 검사에서는 음성이 양성보다 훨씬 많음
- 특이도가 낮으면 정밀도가 떨어짐
예) 실제 양성이 1%인 경우
예측 음성 예측 양성 실제 음성 9900 0 실제 양성 2 98 특이도 100% 민감도 98% 정밀도 100%
예측 음성 예측 양성 실제 음성 9504 396 실제 양성 10 90 특이도 96% 민감도 90% 정밀도 18.5%
F1
\[\frac{1}{\frac{\frac{1}{p} + \frac{1}{r}}{2}} = \frac{2pr}{p + r}\]- 정밀도(p)와 재현도(r)의 조화 평균
(2pr) / (p + r) - 조화평균: 역수의 평균의 역수
- 비율, 속도 등을 평균낼 때는 산술평균 대신 조화평균을 사용
1
f1_score(y_true, y_pred)