
이미지 변형
크기 변경
자세히 보기
이미지 크기를 절반으로 줄임 (넓이는 1/4)
1
2
3
4
5
6
7
8
9
10
11
image = cv.imread('../data/balls.png')
# 원하는 크기로 변경
height, width, channel = image.shape # 원래의 크기
new_size = (width // 2, height // 2) # 새로운 크기(원래 크기의 절반)
image = cv.resize(image, new_size) # 크기 변경
display(show(image))
# 비율로 변경
image = cv.resize(image, (0, 0), fx=0.5, fy=0.5) # 가로, 세로 각각 50% 크기로 축소
display(show(image))

보간
자세히 보기
- 이미지를 확대, 축소할 때 새로운 픽셀들은 기존의 픽셀을 보간하여 사용
- 확대:
- INTER_NEAREST: 주변 픽셀을 이용. 가장 빠르지만 화질이 낮음
- INTER_LINEAR: 주변 2x2 이웃 픽셀을 사용
- INTER_CUBIC: 주변 4x4 이웃 픽셀을 사용
- INTER_LANCZOS4: 주변 8x8 이웃 픽셀을 사용. 가장 느리지만 화질이 높음
- 축소:
- INTER_AREA: 이미지를 축소할 때 사용. 확대할 때는 사용하지 않음
1
2
3
4
big1 = cv.resize(image, None, fx=2.0, fy=2.0, interpolation=cv.INTER_NEAREST) # 가장 가까운 이웃 보간법
big2 = cv.resize(image, None, fx=2.0, fy=2.0, interpolation=cv.INTER_LINEAR) # 양선형 보간법
big3 = cv.resize(image, None, fx=2.0, fy=2.0, interpolation=cv.INTER_CUBIC) # 3차 보간법
big4 = cv.resize(image, None, fx=2.0, fy=2.0, interpolation=cv.INTER_LANCZOS4) # Lanczos 보간법

미묘,, 하게 Lanczos 보간법으로 갈수록 화질이 더 나아보임
Super Resolution
자세히 보기
- 최근에는 딥러닝을 이용하여 이미지를 확대하는 방법도 있음(Super Resolution)
- 원본(4번째, original)을 축소한 다음 2x2로 보간하여 확대(1번째, bicubic)하면 흐림
- 딥러닝을 이용하여 확대(3번째, SRGAN)하면 선명하게 확대됨
- 단, 학습된 패턴을 이용하여 디테일을 채워넣기 때문에 원본과 다른 디테일이 추가될 수 있음
뒤집기
자세히 보기
상하로 뒤집기
1
cv.flip(image, 0)
좌우로 뒤집기(플래그가 0보다 큰 경우)
1
cv.flip(image, 1)
좌우상하로 뒤집기(플래그가 0보다 작은 경우)
1
cv.flip(image, -1)
회전
자세히 보기
시계 방향으로 90도
1
cv.rotate(image, cv.ROTATE_90_CLOCKWISE)
180도
1
cv.rotate(image, cv.ROTATE_180)
반시계 방향으로 90도
1
cv.rotate(image, cv.ROTATE_90_COUNTERCLOCKWISE)
이미지에서 특정 부분 자르기
자세히 보기
1
2
3
4
5
height, width, channel = image.shape # 이미지의 높이, 너비, 채널 수
x, y = width // 2, height // 3 # 자를 위치(가로 1/2 위치, 세로 1/3 위치)
w, h = width // 4, height // 5 # 자를 크기(가로 1/4 크기, 세로 1/5 크기)
cropped = image[y:y+h, x:x+w] # 이미지 자르기
show(cropped)

크로마키 합성
특정 색상만 추출
자세히 보기
1
2
3
4
5
6
7
8
9
10
import numpy as np
image = cv.imread('../data/balloon.webp')
lower = np.array([40, 50, 50])
upper = np.array([80, 255, 255])
hsv = cv.cvtColor(image, cv.COLOR_BGR2HSV)
mask = cv.inRange(hsv, lower, upper)
Image.fromarray(mask)
colored_mask = cv.bitwise_and(image, image, mask=mask)
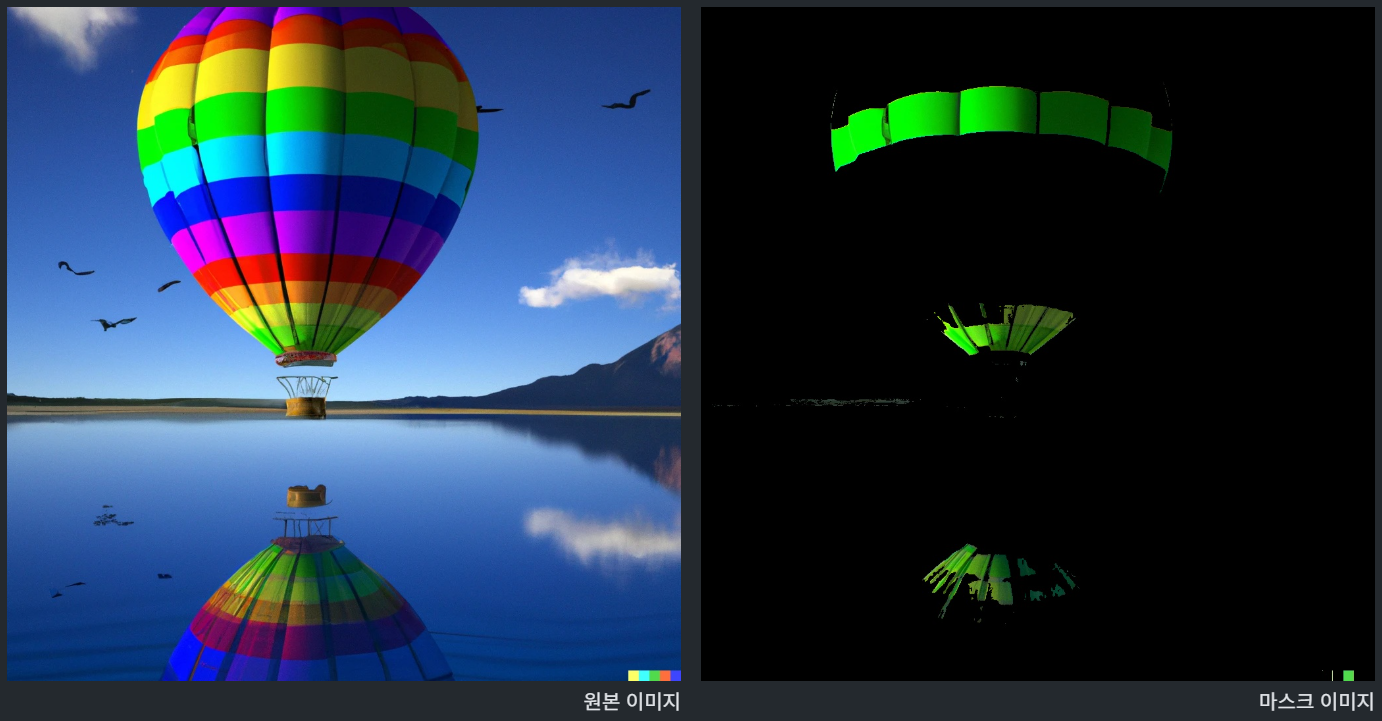
크로마키를 이용한 합성
자세히 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
foreground = cv.imread('../data/chroma-key.jpg')
background = cv.imread('../data/desert.jpg')
# 배경 크기 리사이즈
height, width = foreground.shape[:2]
background = cv.resize(background, (width, height))
# 인물 이미지를 HSV로 변환
hsv = cv.cvtColor(foreground, cv.COLOR_BGR2HSV)
lower_green = np.array([40, 100, 100])
upper_green = np.array([60, 255, 255])
mask = cv.inRange(hsv, lower_green, upper_green)
mask_inv = cv.bitwise_not(mask)
fg_isolated = cv.bitwise_and(foreground, foreground, mask=mask_inv)
bg_isolated = cv.bitwise_and(background, background, mask=mask)
final_output = cv.add(fg_isolated, bg_isolated)

기하학적 변환
아핀 변환 Affine transform
자세히 보기
\[\begin{bmatrix} x' \\ y' \end{bmatrix} = \begin{bmatrix} a_{00} & a_{01} & b_0 \\ a_{10} & a_{11} & b_1 \end{bmatrix} \begin{bmatrix} x \\ y \\ 1 \end{bmatrix}\]- 선형 변환(a)과 평행 이동(b)을 합친 것
- 변환 후에서 평행과 비율은 보존. 길이와 각도는 X
- 영상의 이동, 전단, 확대, 회전을 조합
- 3개의 점이 주어지면 아핀 변환을 결정할 수 있음
- 아핀 변환(Affine Transformation)은 기하학에서 도형의 평행성(Parallelism)을 유지하면서 모양을 바꾸는 선형 변환과 평행 이동의 결합입니다. [1]
핵심 개념
아핀 변환은 크게 두 가지 요소로 구성됩니다. [2]
- 선형 변환 (Linear Transformation): 원점을 기준으로 물체를 회전시키거나, 크기를 늘리거나 줄이고, 옆으로 미는(전단) 동작입니다.
- 평행 이동 (Translation): 물체를 일정한 거리만큼 그대로 옆이나 위아래로 옮기는 동작입니다.
시각적 특징
아핀 변환을 거친 도형은 다음과 같은 성질을 갖습니다. [3]
- 직선의 유지: 변환 전의 직선은 변환 후에도 반드시 직선입니다.
- 평행선의 유지: 서로 평행했던 두 선은 변환 후에도 여전히 평행합니다.
- 비율의 보존: 선분 위의 점들 사이의 거리 비율이 일정하게 유지됩니다.
수식의 직관적 해석
앞서 제시된 행렬 수식 $\begin{bmatrix} a_{00} & a_{01} & b_0 \ a_{10} & a_{11} & b_1 \end{bmatrix}$에서 각 부분의 역할은 다음과 같습니다.
- $a_{00}, \ a_{01}, \ a_{10}, \ a_{11}$: 이미지의 모양을 결정합니다. (회전, 크기 조절, 기울이기)
- $b_0, \ b_1$: 이미지가 이동할 위치를 결정합니다. (가로 이동 $b_0$, 세로 이동 $b_1$)
이러한 특성 때문에 컴퓨터 그래픽스나 이미지 처리(사진의 수평 맞추기, 확대/축소 등)에서 가장 기본적으로 사용되는 기술입니다.
참고문헌
[1] Glassner, A. S. (1989). An Introduction to Ray Tracing. Academic Press. https://shop.elsevier.com/books/an-introduction-to-ray-tracing/glassner/978-0-08-049905-5
[2] Schneider, P. J., & Eberly, D. H. (2002). Geometric Tools for Computer Graphics. Morgan Kaufmann. https://www.elsevier.com/books/geometric-tools-for-computer-graphics/schneider/978-1-55860-594-7
[3] Nomizu, K., & Sasaki, T. (1994). Affine Differential Geometry. Cambridge University Press.
평행 이동
자세히 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
image = cv.imread('../data/balls.png') # 예제 이미지
image = cv.resize(image, (0, 0), fx=0.25, fy=0.25, interpolation=cv.INTER_AREA)
height, width, channel = image.shape # 이미지의 높이, 너비, 채널 수
# 수평 이동
matrix = np.array([[1, 0, 50], [0, 1, 0]], dtype=np.float32) # x축으로 50픽셀 이동
translated = cv.warpAffine(image, matrix, (width, height)) # 이미지 이동
display(show(translated)) # 이미지 출력
# 수직 이동
matrix = np.array([[1, 0, 0], [0, 1, 50]], dtype=np.float32) # y축으로 50픽셀 이동
translated = cv.warpAffine(image, matrix, (width, height)) # 이미지 이동
display(show(translated)) # 이미지 출력

확대
자세히 보기
1
2
3
4
5
6
7
8
9
10
wr = 2 # 가로는 2배
hr = 3 # 세로는 3배
matrix = np.array([[wr, 0, 0], [0, hr, 0]], dtype=np.float32)
resized = cv.warpAffine(
image,
matrix,
(width * wr, height * hr), # 새로운 크기
flags=cv.INTER_LANCZOS4) # 보간
display(show(resized))

회전
자세히 보기
1
2
3
4
5
6
7
matrix = np.array([[0, -1, height], [1, 0, 0]], dtype=np.float32) # 90도 회전 행렬
resized = cv.warpAffine(
image,
matrix,
(height, width)) # 가로, 세로의 크기가 바뀜
display(show(resized))

회전 행렬 계산
자세히 보기
1
2
3
4
5
6
center = width // 2, height // 2 # 이미지의 중심 좌표
angle = 45 # 회전 각도
ratio = 1 # 확대 비율
matrix = cv.getRotationMatrix2D(center, angle, ratio) # 회전 행렬 계산
rotated = cv.warpAffine(image, matrix, (width, height)) # 이미지 회전
show(rotated) # 이미지 출력

크기 맞추기 및 배경 채우기
자세히 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
cos = abs(matrix [0, 0])
sin = abs(matrix [0, 1])
new_width = int((height * sin) + (width * cos)) # 새로운 너비
new_height = int((height * cos) + (width * sin)) # 새로운 높이
image_center = (width // 2, height // 2) # 원본 이미지의 중심 좌표
matrix [0, 2] += (new_width / 2) - image_center [0] # 새로운 x좌표로 이동
matrix [1, 2] += (new_height / 2) - image_center [1] # 새로운 y좌표로 이동
rotated = cv.warpAffine(
image, matrix,
(new_width, new_height), # 새로운 크기
borderMode=cv.BORDER_CONSTANT, # 배경 색은 한 가지로
borderValue=image[0, 0].tolist()) # 왼쪽 위 (0, 0)의 픽셀 값으로 배경을 채움
show(rotated) # 이미지 출력

투시 변환 Perspective transform
자세히 보기
\[\begin{bmatrix} w_i x' \\ w_i y' \\ w_i \end{bmatrix} = \begin{bmatrix} a_{00} & a_{01} & b_0 \\ a_{10} & a_{11} & b_1 \\ c_0 & c_1 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \\ 1 \end{bmatrix}\]- 아핀 변환에 투시(c)를 추가(반대로 말하면 c0 = c1 = 0이면 아핀변환)
- 아핀변환보다 자유도가 높음
- 4개의 점이 주어지면 투시 변환 행렬을 결정할 수 있음
- 아핀 변환과의 차이점
- 가변적인 스케일($w_i$): 아핀 변환과 달리 결과 벡터의 세 번째 성분이 1이 아닌 $w_i$로 표현됩니다. 이는 투영 결과에 따라 각 점마다 깊이(Scale)가 달라질 수 있음을 의미합니다.
- 원근감 구현($c_0, c_1$): 행렬의 마지막 행에 추가된 $c_0, c_1$ 요소는 직선의 평행성을 유지하지 않고, 멀리 있는 물체가 작게 보이는 원근 효과를 만듭니다.
- 자유도: 아핀 변환보다 자유도가 높으며, 사각형을 임의의 사다리꼴이나 사각형으로 변환할 수 있습니다.
체스보드 투시 변환
자세히 보기
체스보드 이미지에 기준점 찍기
1 2 3 4 5 6 7 8 9 10
src = cv.imread('../data/chessboard.jpg') pts1 = np.array([[60, 500],[900, 100], [900,1100],[1700, 500]], dtype=int) pts2 = np.float32([[0,0],[1000,0],[0,1000], [1000, 1000]]) cv.circle(src, tuple(pts1[0]), 20, (255,0,0),-1) cv.circle(src, tuple(pts1[1]), 20, (0,255,0),-1) cv.circle(src, tuple(pts1[2]), 20, (0,0,255),-1) cv.circle(src, tuple(pts1[3]), 20, (255,255,0),-1) show(src)
![]()
점 3개만 있어도 아핀 변환 가능
1 2 3 4 5
src_pts = pts1[:3].astype(np.float32) # 원본의 점 3개 dst_pts = pts2[:3] # 에 해당하는 변환된 점 3개 matrix = cv.getAffineTransform(src_pts, dst_pts) dst = cv.warpAffine(src, matrix, (1000,1000)) show(dst)
![]()
점 4개로 투시 변환
1 2 3
matrix = cv.getPerspectiveTransform(pts1.astype(np.float32), pts2) dst = cv.warpPerspective(src, matrix, (1000,1000)) show(dst)
![]()



카메라 교정
카메라 왜곡
- 카메라 렌즈의 효과로 생기는 왜곡: 볼록하면 배럴(barrel), 오목하면 핀쿠션(pincushion)
- 교정 방법
- 교정 패턴(Calibration pattern): 다양한 관점에서 알려진 차원의 패턴의 이미지를 여러 장 캡처 (체커보드 패턴, 원형 패턴 등)
- 기하학적 단서(Geometric clues): 직선과 소실점과 같은 기하학적 단서를 사용
- 딥러닝 기반: 다양한 렌즈의 이미지를 딥러닝으로 학습시켜 보정 (한 장만 있어도 사용할 수 있음, 학습된 모델이 필요)
체커보드 패턴 다운로드 받기
- 구글에서 checkerboard pattern camera calibration 으로 검색 (checker 대신 chess도 가능)
- https://markhedleyjones.com/projects/calibration-checkerboard-collection
- 다운로드 받아 인쇄하거나 또는 모니터에 띄워두고 교정하려는 카메라로 촬영
체커보드 패턴의 교차점 찾기
자세히 보기
1
2
3
4
5
6
7
8
9
10
11
src = cv.imread('../data/fisheye01.jpg')
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY) # 흑백으로
patternSize = 7, 10 # + 모양 교차점의 개수(7행 10열)
flags = (cv.CALIB_CB_ADAPTIVE_THRESH | cv.CALIB_CB_FAST_CHECK | cv.CALIB_CB_NORMALIZE_IMAGE)
# 교차 찾기(찾는데 성공하면 retval == True)
retval, corners = cv.findChessboardCorners(gray, patternSize, flags=flags)
if retval:
# 교차점 그리기
cv.drawChessboardCorners(src, patternSize, corners, retval)
display(show(src))

교차점을 더 정확하게
1
2
3
4
5
6
7
# 11x11 범위에서 더 정확하게 찾기. (-1, -1)은 제외하는 범위가 없다는 뜻.
criteria = (cv.TERM_CRITERIA_EPS + cv.TERM_CRITERIA_MAX_ITER, 30, 0.001)
corners2 = cv.cornerSubPix(gray, corners, (11,11), (-1,-1), criteria)
# 찾은 교차점을 원본 이미지에 추가
img_corner = cv.drawChessboardCorners(src, patternSize, corners2, retval)
display(show(img_corner))

왜곡된 체커보드 복구하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# fisheye 로 시작하는 jpg 파일 모두 찾기 (*은 "아무 글자들"을 뜻함)
import glob
# 교정 준비
filenames = glob.glob('../data/fisheye*.jpg')
# 좌표들
objpoints = [] # 3차원 좌표
imgpoints = [] # 2차원 좌표
objp = np.zeros((1, patternSize[0] * patternSize[1], 3), np.float32)
objp[0,:,:2] = np.mgrid[0:patternSize[0], 0:patternSize[1]].T.reshape(-1, 2)
# 모든 이미지에서 교차점 좌표 찾기
for fname in filenames: # 모든 파일에 대해
gray = cv.imread(fname, cv.IMREAD_GRAYSCALE)
retval, corners = cv.findChessboardCorners(gray, patternSize,flags=flags)
if retval: # 교차점을 찾았으면
objpoints.append(objp) # 3차원 좌표 추가
corners2 = cv.cornerSubPix(gray, corners, (11,11),(-1,-1), criteria)
imgpoints.append(corners2) # 2차원 좌표 추가
# 카메라 교정
ret, mtx, dist, rvecs, tvecs = cv.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)
# 이미지에서 렌즈 왜곡 교정
src = cv.imread('../data/fisheye01.jpg') # 이미지 열기
# 왜곡 제거를 위한 교정치 얻기
h,w = gray.shape[:2]
newcameramtx, roi = cv.getOptimalNewCameraMatrix(mtx, dist, (w,h), 1, (w,h))
dst = cv.undistort(src, mtx, dist, None, newcameramtx) # 교정치 적용
display(show(dst))

ArUco 마커
자세히 보기
- Augmented Reality University of Cordoba의 약자
- 흑백 정사각형 패턴 + 내부 이진 코드 (QR 코드와 비슷)
- 단일 마커만으로도 6DoF pose (위치 + 자세) 추정 가능
- 검출 속도가 빠르고 구현이 쉬움
- 마커 크기만 정확히 알면 실공간 좌표 계산 가능
- 일부가 가릴 경우 식별이 안됨
ArUco 마커의 응용
- ArUco 보드(왼쪽): 여러 개의 마커로 보드를 구성, 일부가 가려도 식별 가능
- ChArUco 보드 (가운데, Chessboard + ArUco): 정밀한 카메라 교정에 사용
- 다이아몬드 마커(오른쪽): ArUco 마커를 다이아몬드 형태로 배치하여 좌표와 방향을 더 정확히 탐지
공간 필터링
자세히 보기
공간 주파수
- 공간 주파수: 공간상에서 화소 밝기의 변화율
- 고주파 영역: 화소 밝기가 급변하는 영역(주로 경계)
- 저주파 영역: 화소 밝기의 변화가 거의 없거나 점진적으로 변화하는 영역(주로 배경)
공간 필터링 spacial filtering
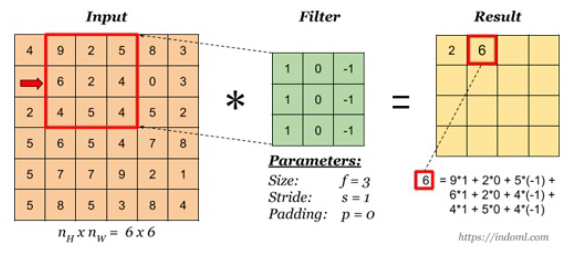
- 인접화소들의 값을 참조하여 화소의 값을 변경하는 처리
- 컨볼루션(convolution)을 이용하여 구현
- 중심 화소의 값을 인접 화소값들의 가중 합으로 대체하는 연산
- 가중치 2차원 배열: 커널(kernel), 필터(filter), 또는 마스크(mask)라고 함
![]()
평균값 필터링
- 주변 3x3 픽셀의 평균으로 채워서 흐리게(blur) 만듦
1
2
3
4
5
6
7
src = cv.imread('../data/temple.webp')
kernel = np.array([
[1/9, 1/9, 1/9],
[1/9, 1/9, 1/9],
[1/9, 1/9, 1/9]], dtype=np.float32)
dst = cv.filter2D(src, -1, kernel)
show(dst)

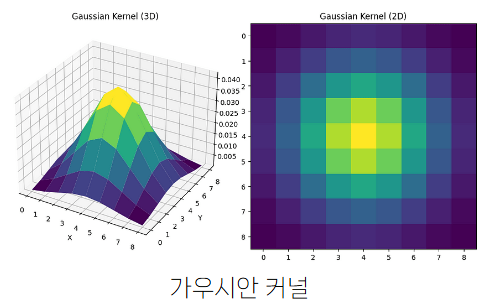
가우시안 블러링 Gaussian Blurring
- 이미지를 흐리게(blur) 만드는 방법
가우시안 함수(=통계의 정규 분포)를 이용 → 가운데는 많이, 주변은 적게 반영
![]()
커널 내 (예: 5x5 범위)에서만 적용
1 2
blur = cv.GaussianBlur(src, (5, 5), 0) show(blur)
커널을 직접 구하려면 아래 처럼
1 2 3 4
kernel = cv.getGaussianKernel(5, 0) kernel = kernel * kernel.T kernel = kernel / np.sum(kernel) dst = cv.filter2D(src, -1, kernel)
수직 성분 추출
- 왼쪽의 픽셀들과 오른쪽의 픽셀들의 차이를 구함
- 수평 방향으로 밝기가 변할 때 결과값이 커짐
- 오른쪽이 밝고 왼쪽은 어두울 때 결과값이 가장 큼
1
2
3
4
5
6
kernel = np.array([
[-1, 0, 1],
[-1, 0, 1],
[-1, 0, 1]], dtype=np.float32)
dst = cv.filter2D(src, -1, kernel)
show(dst)

수평 성분 추출
- 위쪽의 픽셀들과 아래쪽의 픽셀들의 차이를 구함
- 수직 방향으로 밝기가 변할 때 결과값이 커짐
- 위는 밝고 아래는 어두울 때 결과값이 가장 큼
1
2
3
4
5
6
kernel = np.array([
[1, 1, 1],
[0, 0, 0],
[-1, -1, -1]], dtype=np.float32)
dst = cv.filter2D(src, -1, kernel)
show(dst)

Sharpening
- 주변 픽셀들과의 밝기 차이를 과장해서 날카롭게 만듦(blur의 반대)
- 초점이 맞지 않은 사진을 선명하게 만들 수 있지만, 노이즈도 증가
1
2
3
4
5
kernel = np.array([
[-1, -1, -1],
[-1, 9, -1],
[-1, -1, -1]], dtype=np.float32)
dst = cv.filter2D(src, -1, kernel)

소벨 커널 Sobel kernel
- 경계선(edge) 검출을 위한 커널
1
2
3
4
5
sobelx = cv.Sobel(src, cv.CV_64F, 1, 0, ksize=3) # x 방향의 경계선 검출
sobely = cv.Sobel(src, cv.CV_64F, 0, 1, ksize=3) # y 방향의 경계선 검출
sobel_magnitude = cv.magnitude(sobelx, sobely) # 두 방향의 경계선을 하나로 결합
sobel_result = cv.normalize(sobel_magnitude, None, 0, 255, cv.NORM_MINMAX, cv.CV_8U) # 정규화
show(sobel_result) # 시각화

케니 에지 검출 Canny edge detection
- 소벨 커널을 바탕으로 만든 경계선 검출 알고리즘
1
2
3
4
5
6
7
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY) # 그레이스케일로 변환
# Otsu의 이진화로 상한값 계산
upper, ret = cv.threshold(gray, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
lower = upper / 2 # 하한값은 보통 상한값의 1/2 또는 1/3 사용
blur = cv.GaussianBlur(gray, (9, 9), 0) # 가우시안 블러 적용
edges = cv.Canny(blur, upper, lower)
show(edges) # Canny 엣지 검출 결과 출력

경계선 추출 전 흐리게 하기
- 경계선은 밝기가 급격하게 변하므로 고주파 검출에 해당
- 이미지의 잡음도 고주파이므로 경계선 검출을 방해할 수 있음
- 이미지를 흐리게 하는 것은 낮은 주파수만 통과시키는 것과 같음(low-pass filter)
- 경계선 검출 전에 이미지를 흐리게 하여 잡음을 뭉개면 경계선을 검출하는데 도움이 됨

모양 감지
자세히 보기
전처리
1
2
3
4
5
6
7
8
9
10
11
# 파일 열기
image_path = 'shapes.webp'
image = cv.imread(image_path)
# 흑백 이미지로 변환
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
# 7x7 커널로 가우시안 블러링
blurred = cv.GaussianBlur(gray, (7, 7), 0)
# 이진화
th, bin = cv.threshold(blurred, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
# 보기
Image.fromarray(bin)

윤곽선 추출
검은 색 배경에서 하얀색 물체의 윤곽선을 추출
1
2
3
4
5
6
7
8
9
contours, hierarchy = cv.findContours(
bin.copy(), # 이미지, non-zero 픽셀을 객체로 간주
cv.RETR_EXTERNAL, # 윤곽선 검출 모드
cv.CHAIN_APPROX_SIMPLE) # 윤곽선 근사화 방법
# (SIMPLE: 꼭지점만, NONE: 모든 점)
# 검출된 윤곽선 그리기
contour_image = image.copy()
cv.drawContours(contour_image, contours, -1, (0, 255, 0), 3)
show(contour_image)

- contours: 검출된 윤곽선 좌표.
- hierarchy: 윤곽선 계층 정보.
- 1, N, 4 형태의 행렬
- 마지막 차원은 [이전, 다음, 자식, 부모]를 나타냄(없으면 -1)
윤곽선 추출
- 윤곽선 검출 모드
- EXTERNAL: 바깥 윤곽선만 검출하여 리스트로
- LIST: 계층 정보 없이 모든 윤곽선 검출
- CCOMP: 2단계까지 계층 구조
- TREE: 다단계 계층 구조
- 근사화 방법
- cv.CHAIN_APPROX_NONE : 윤곽점들의 모든 점
- cv.CHAIN_APPROX_SIMPLE : 윤곽점들 단순화하고 끝점만
- cv.CHAIN_APPROX_TC89_L1 : Teh_Chin 연결 근사 알고리즘 L1 버전을 적용
- cv.CHAIN_APPROX_TC89_KCOS : Teh_Chin 연결 근사 알고리즘 KCOS버전을 적용
윤곽선 그리기
1
2
3
4
5
contoured_image = image.copy() # 이미지 복사
i = 2 # 2번 도형
color = 0, 255, 0 # green
thickness = 3 # 두께
show(cv.drawContours(contoured_image, contours, i, color, thickness))

이미지 모멘트
이미지의 픽셀 분포에 대한 가중치 평균
\[m_{ji} = \sum_{x,y} x^j * y^i * I(x, y)\]- x: 점의 x좌표
- y: 점의 y좌표
- $I(x, y)$: 점의 밝기
응용
- $m_{00}$: 면적(모든 점의 밝기의 합)
- $m_{10} / m_{00}$: 무게 중심의 x좌표, $m_{01} / m_{00}$: 무게 중심의 y좌표
무게 중심 그리기
1
2
3
4
5
6
7
8
9
M = cv.moments(contours[i]) # 모멘트 계산
cX = int(M["m10"] / M["m00"]) # x좌표의 무게 중심
cY = int(M["m01"] / M["m00"]) # y좌표의 무게 중심
dst = image.copy()
center_color = 0, 255, 0 # green
no_stroke = -1 # 테두리 없음
radius = 7 # 반지름
show(cv.circle(dst, (cX, cY), radius, center_color, no_stroke))

Ramer–Douglas–Peucker 알고리즘
- 윤곽선을 다각형으로 근사하기 위한 알고리즘
cv.approxPolyDP으로 사용할 수 있음
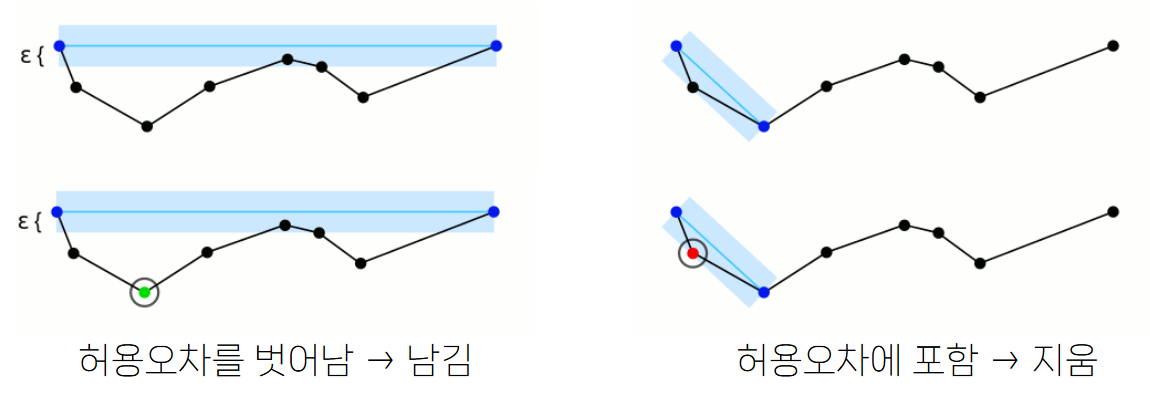
다각형으로 근사
1
2
3
4
5
6
7
8
c = contours[i] # 곡선
peri = cv.arcLength(c, True) # 둘레 길이(폐곡선 여부)
approx = cv.approxPolyDP(
c, # 곡선
0.02 * peri, # 허용 오차
True) # 폐곡선 여부
n = len(approx) # n각형
n # 3
신분증 스캔
신분증 스캔 등에서 추출한 좌표를 정면에서 본 것처럼 변환합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 이미지 파일 불러오기
image = cv.imread('../data/id_card.png')
# 오츠의 이진화
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
_, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY + cv.THRESH_OTSU)
# 가장 큰 사각형 찾기
contours, _ = cv.findContours(binary, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
biggest_rect = None
for contour in contours:
epsilon = 0.02 * cv.arcLength(contour, True)
approx = cv.approxPolyDP(contour, epsilon, True)
if len(approx) == 4 and \
biggest_rect is None or cv.contourArea(approx) > cv.contourArea(biggest_rect):
biggest_rect = approx
# 투시 변환
sorted_corners = sorted(biggest_rect.tolist()) # 꼭지점 정렬
pts1 = np.float32(sorted_corners)
pts2 = np.float32([[0, 0], [0, 200], [400, 0], [400, 200]])
matrix = cv.getPerspectiveTransform(pts1, pts2)
result = cv.warpPerspective(image, matrix, (400, 200)) # 투시 변환

볼록 껍질 (Convex Hull)
어떤 도형을 둘러싼 볼록한 다각형을 찾습니다.
1
2
3
4
5
6
7
8
9
10
src = cv.imread("convex.webp") # 예제 데이터
dst = src.copy()
gray = cv.cvtColor(src, cv.COLOR_RGB2GRAY)
ret, binary = cv.threshold(gray, 150, 255, cv.THRESH_BINARY_INV) # 이진화
contours, hierarchy = cv.findContours( # 윤곽선
binary, cv.RETR_CCOMP, cv.CHAIN_APPROX_NONE)
for i in contours:
hull = cv.convexHull(i, clockwise=True) # 볼록 껍질 찾기(True: 시계 방향)
cv.drawContours(dst, [hull], 0, (0, 0, 255), 2)
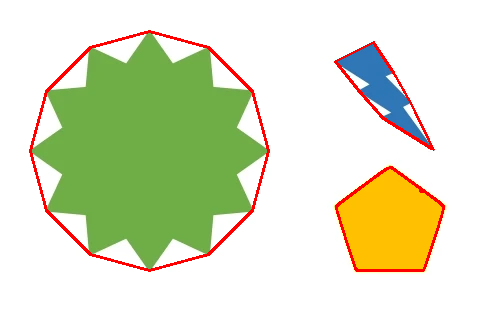
배경 색을 이용해 자르기
배경색과 유사한 부분을 마스킹하여 실제 객체가 있는 부분만 자릅니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
src = cv.imread('nut.png')
bg_color = src[0, 0] # 왼쪽 상단 픽셀 색상 (배경색으로 가정)
error = 10
low = np.where(bg_color > error, bg_color - error, 0)
high = np.where(bg_color < 255 - error, bg_color + error, 255)
mask = cv.inRange(src, low, high) # 배경색과 유사한 색상 검출
mask_inv = cv.bitwise_not(mask) # 배경색이 아닌 부분 검출
coords = cv.findNonZero(mask_inv) # 실제 그림이 있는 좌표 추출
x, y, w, h = cv.boundingRect(coords) # 사각형으로 경계 추출
trimmed = src[y:y+h, x:x+w] # 실제 그림 부분만 자름

윤곽선 관련 기타 함수들
cv.contourArea: 윤곽선이 감싸는 영역의 면적cv.fitLine: 주어진 점에 적합한 직선cv.minEnclosingTriangle: 주어진 점을 감싸는 최소 크기 삼각형cv.boundingRect: 주어진 점을 감싸는 최소 크기 사각형cv.minAreaRect: 주어진 점을 감싸는 최소 크기 회전된 사각형cv.minEnclosingCircle: 주어진 점을 감싸는 최소 크기 원cv.fitEllipse: 주어진 점을 감싸는 타원cv.isContourConvex: 볼록 여부cv.convexityDefects: 볼록 껍질에서 가장 안으로 들어간 점
도형 검출
자세히 보기
직선 검출
1
2
3
4
src = cv.imread("road.webp")
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
# 윤곽선 추출
canny = cv.Canny(gray, 5000, 1500, apertureSize = 5, L2gradient = True)

허프 변환
- 윤곽선을 이루는 점들을 지나는 직선의 방정식을 찾음
- 여러 개의 직선들 중에 가장 조건에 맞는 직선들만 골라냄
멀티 스케일 허프 변환 Multi-Scale Hough Transform
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
lines = cv.HoughLines(
canny,
0.8, # 거리 측정 해상도, 0~1
np.pi / 180, # 각도의 해상도(라디안)
150, # 임계값(키울 수록 정확도 증가하고 검출되는 직선의 수는 감소)
srn = 100, # 거리의 약수(≥0), 허프 변환을 좀 더 정확하게 하기 위한 값
stn = 200, # 각도의 약수(≥0), 허프 변환을 좀 더 정확하게 하기 위한 값
min_theta = 0, # 최소 각도
max_theta = np.pi) # 최대 각도
# -------------
dst = src.copy()
for i in lines:
rho, theta = i[0][0], i[0][1]
a, b = np.cos(theta), np.sin(theta)
x0, y0 = int(a*rho), int(b*rho)
scale = src.shape[0] + src.shape[1]
x1 = int(x0 + scale * -b)
y1 = int(y0 + scale * a)
x2 = int(x0 - scale * -b)
y2 = int(y0 - scale * a)
cv.line(dst, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv.circle(dst, (x0, y0), 3, (255, 0, 0), 5, cv.FILLED)
display(show(dst))

점진성 확률적 허프 변환 Progressive Probabilistic Hough Transform
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 속도는 빠르지만 정확성은 떨어지는 방식
lines = cv.HoughLinesP(
canny,
0.8, # 거리 측정 해상도, 0~1
np.pi / 180, # 각도의 해상도(라디안)
90, # 임계값(키울 수록 정확도 증가하고 검출되는 직선의 수는 감소)
minLineLength = 10, # 검출할 직선의 최소 길이
maxLineGap = 100) # 최대 허용 간격(이 간격 내에 있는 직선은 검출 안함)
# ----------------
dst = src.copy()
lines = lines.astype(int, copy=False)
for i in lines:
cv.line(
dst,
(i[0][0], i[0][1]), # 시작
(i[0][2], i[0][3]), # 끝
(0, 255, 0), # 색깔
5) # 굵기
display(show(dst))

원 검출
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
src = cv.imread("../data/balls.webp") # 예제 이미지
gray = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
circles = cv.HoughCircles(# 허프 변환
gray,
cv.HOUGH_GRADIENT, # 검출 방법, HOUGH_GRADIENT_ALT도 있음
1, # 해상도 비율
100, # 원의 중심 간 최소 거리
param1 = 250, # 검출 방법의 매개 변수
param2 = 10, # 검출 방법의 매개 변수
minRadius = 80, # 최소 반지름
maxRadius = 120) # 최대 반지름
# -------------------
dst = src.copy()
circles = circles.astype(int)
for i in circles[0]:
cv.circle(dst, (i[0], i[1]), i[2], (255, 255, 255), 5)
display(show(dst))

이미지 매칭
자세히 보기
이미지 매칭 Image Matching
- 서로 다른 두 이미지를 비교해서 짝이 맞는 같은 형태의 객체가 있는지 찾아내는 기술
- 키포인트 (Keypoint): 이미지 내에서 특징적인 위치를 나타내는 점
- 디스크립터 (Descriptor): 키포인트 주변의 지역적인 이미지 정보를 숫자 벡터로 표현한 것.
- 이 벡터는 해당 키포인트의 “지문” 역할
- 다른 이미지에서 유사한 특징점을 찾을 때 비교에 사용
- ORB (Oriented FAST and Rotated BRIEF) 특징점 검출기:
- FAST 알고리즘을 이용해 키포인트 검출
- BRIEF 알고리즘을 이용해 디스크립터 생성
- Oriented & Rotated: 키포인트의 방향성과 디스크립터의 회전 개념을 추가
특징 디스크립터 Feature Descriptor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
img1 = cv.imread('../data/taekwonv1.jpg') # 비교할 이미지 로드
img2 = cv.imread('../data/figures2.jpg')
gray1 = cv.cvtColor(img1, cv.COLOR_BGR2GRAY) # 특징점 검출을 위해 흑백으로
gray2 = cv.cvtColor(img2, cv.COLOR_BGR2GRAY)
# ORB(Oriented FAST and Rotated BRIEF) 특징점 검출기
detector = cv.ORB_create() # 검출기 생성
kp1, desc1 = detector.detectAndCompute(gray1, None) # 각 이미지의 키포인트(kp)와
kp2, desc2 = detector.detectAndCompute(gray2, None) # 디스크립터(desc)를 추출
# ------------------------------
# 중간 과정 시각화
img1_kp = cv.drawKeypoints(img1, kp1, None, color=(0, 255, 0))
img2_kp = cv.drawKeypoints(img2, kp2, None, color=(0, 255, 0))
html = f"""<table>
<tr>
<td><img src="data:image/jpeg;base64,{to_base64(img1_kp)}"><br>이미지 1의 특징점</td>
<td><img src="data:image/jpeg;base64,{to_base64(img2_kp)}"><br>이미지 2의 특징점</td>
</tr>
</table>"""
display(HTML(html))

특징 매칭 Feature Matching
1
2
3
4
5
6
7
8
9
10
11
# 2개의 그림에서 특징들이 서로 일치하는 부분을 매칭
matcher = cv.BFMatcher(cv.NORM_HAMMING, crossCheck=True)
matches = matcher.match(desc1, desc2)
# 매칭된 결과를 거리의 오름차순으로 정렬(가까울 수록 좋은 매칭)
matches = sorted(matches, key=lambda x:x.distance)
# 결과 시각화 (다음 장)
res1 = cv.drawMatches(img1, kp1, img2, kp2, matches, None,
flags=cv.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
show(res1)

- 모서리만 보고 매칭하는 것이기 때문에 정확하긴 어렵다. 여기서는 대략적인 매칭이면 됐음.
호모그래피 Homography
- 두 장의 사진이 다른 방향과 각도에서 촬영한 것이므로 완전히 일치하지는 않음
- 투시 변환을 통해서 방향과 각도를 맞출 수 있음(호모그래피 ≒ 투시 변환)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 두 이미지에서 매칭된 점의 좌표들을 추출
src_pts = np.float32([ kp1[m.queryIdx].pt for m in matches ])
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in matches ])
# RANSAC 알고리즘으로 두 좌표들을 최대한 맞출 수 있는 변환 행렬을 계산
# (임계값 5.0 이하의 점들만 포함)
mtrx, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC, 5.0)
# ---------------
h,w = img1.shape[:2] # 원본 이미지 크기
pts = np.float32([ [[0,0]],[[0,h-1]],[[w-1,h-1]],[[w-1,0]] ]) # 원본 이미지의 네 모서리 좌표
dst = cv.perspectiveTransform(pts, mtrx) # ..가 img2에 어떻게 변환되는지
# 시각화
img2 = cv.polylines(img2,[np.int32(dst)],True,(0, 255, 0),3, cv.LINE_AA)
show(img2)

좋은 매칭점만 보기
1
2
3
4
5
6
7
8
matchesMask = mask.ravel().tolist() # RANSAC 알고리즘으로 걸러진 좋은 매칭점은 1
res2 = cv.drawMatches(img1, kp1, img2, kp2, matches, None, # ..만 시각화
matchesMask = matchesMask,
flags=cv.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS)
display(show(res2))
# 좋은 매칭점의 개수(적으면 물체가 없다고 판단할 수 있음)
print(f"num of good match point: {sum(matchesMask)}") # 27
