
table of contents
덤
깃/깃허브에 한글 파일명/폴더명 쓰지 마세요……… 내 레포지토리가 이렇게 됐다고요
![]()
- 클론, 푸시, 풀, 커밋 다 되는데 웹사이트만 안나오는 거라 다행이긴 한데요
- 로컬에서는 한글로 똑바로 나오긴 하는데요
- 이제 웹으로는 볼 수 없어 그냥 못해 404 나오더라
- 진짜 현실 부정하고 싶었음
- 저거 보고 충격받아서 수습하다가 수업시간 2시간 날리고 수습 실패함 👍
교수님 강의용 페이지인 것 같은데 볼만한 자료도 좀 있음: https://www.mindscale.kr/
컴퓨터 비전
- 인공지능의 한 분야
- 컴퓨터가 비전을 갖는다 직관적이죠
이미지 처리
- 기계학습으로 치면 전처리 비슷한 거.
- 어떤 기법들이 있는지 알아야 써먹는다. 그 선택지들을 배우는 거임.
컴퓨터 비전 task
- 이미지 분류
- what에 대답하는 문제
- 이미지를 정해진 카테고리 중 하나로 분류
- 지도 학습 필요
- 물체 탐지
- what + where
- 하나의 이미지에서 다수의 물체와 위치를 탐지
- 광학 문자 인식
- OCR 그거
- 신분증 사진 찍을 때에도 씀
- 이미지 분리
- 비대면 회의 시 배경 흐리게 필터 넣는 거랑 비슷한 거임
- 물체 탐지보다 좀 더 세세하게 따짐. 물체 탐지는 박스만 치면 되는데 이미지 분리는 픽셀 단위로 색칠해야 함
- 깊이 추정
- 이미지에 존재하는 물체의 깊이를 예측함
- 약간 어떤 게 앞에 있고 어떤 게 뒤에 있는지 2D 이미지에서 3D 공간감을 예측한다는 말인듯
- 자세 추정
- 관절 등의 특징점을 탐지하고 가려진 부분의 위치도 추정해서 사람의 자세를 추정하기
- 운동 분석, 침입 탐지, 로봇 공학 등에 활용
- 이미지 간 변환
- 한때 유행했었죠 챗지피티한테 사진 주고 지브리 그림체로 그려달라 하기. 그런 화풍 변환 모델.
- 물론 저건 예시고 해상도 상향, 이미지 컬러화, 이미지 편집 등에 쓰임
- 이미지 생성
- 챗지피티가 해주는 거. 사용자의 지시에 따라 백지에서 이미지를 생성.
컴퓨터 비전과 머신러닝
- 머신 러닝
- 머신러닝은 데이터가 중요한데, 요즘 데이터 너무 흔하거든요.
- 지도, 비지도, 강화 학습 이 셋은 여러 번 설명 들었지
- 교수님이 이것저것 썰풀긴 하셨는데 이때 내가 다른 문제,,로 바빴음 그냥 그렇구나 하고 들음
- 지도 학습
- 답을 알려주는 학습 뭔말알.
- 이미지 분류의 원리
- 이미지는 n개의 점으로 구성된다 → n차원 공간 상의 한 좌표라고 볼 수 있다 → 이미지의 종류를 구분하는 그 n차원 내의 경계를 찾아내면 이미지 분류가 가능하다
- 진짜 고능한 발상이다 어떻게 그 n개의 숫자를 좌표로 볼 수가 있지
- 이미지는 n개의 점으로 구성된다 → n차원 공간 상의 한 좌표라고 볼 수 있다 → 이미지의 종류를 구분하는 그 n차원 내의 경계를 찾아내면 이미지 분류가 가능하다
- 뉴런
- 공돌이들이 또 무언가 베꼈다
- 신경 세포 그거
- 인공신경망
- 뉴런 있죠? 그게 하나의 단위가 돼서 뉴런을 다닥다닥 연결하고 계산해라 컴퓨터야! 하는 거임
- 그 뉴런을 퍼셉트론(인공 뉴런)이라고 불러요. 퍼셉트론 자체는 로지스틱 회귀분석과 비슷함.
- 다층 신경망은 퍼셉트론으로 구성된 층을 만들고 그걸 여러 겹 쌓은 것.
- 보편 근사 정리: 어떤 함수든 인공 신경망으로 근사할 수 있음
- 근사
- 아다리 딱딱 맞추는 건 아니어도 대충 비슷하게 맞는 거
- 그거지 $x^2$과 $x^4$은 원점 주변에서 그래프가 비슷하잖아 그런 느낌임
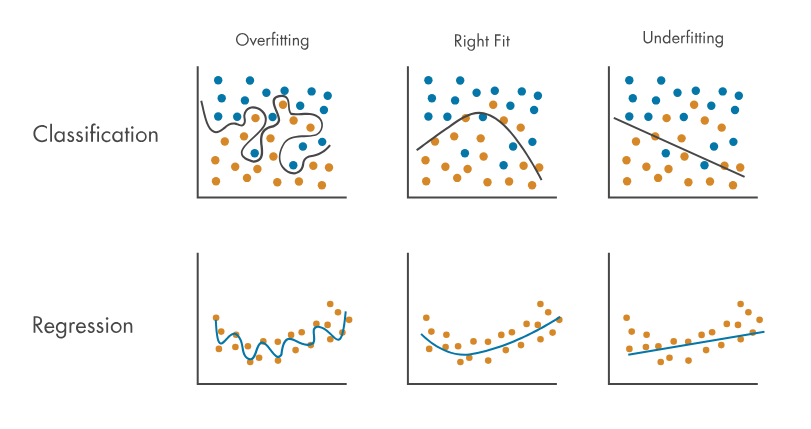
이 개념에서 과소/과대적합이 나온다
![]()
- 미래를 예측하는 게 더 쉬울까요 과거를 설명하는 게 쉬울까요?
- 미래 예측이 더 쉬워요 원인이 있으면 결과가 있거든
- 과거 설명은 결과를 보고 원인을 찾는 거야. 근데 여러 개의 원인이 동일한 결과를 내. 그럼 그 중에 뭐가 실제 원인이었는지 어떻게 알건데?
- 보통 쉽다고 생각하는 이유는 그럴싸한 설명을 하는 것 자체는 쉽기 때문임. 그게 정답인지 아닌지 알 수 없어서 그렇지.
- 정답이라는 건 뭘 말하는 거냐면 재현성이 있어야 해. 인과관계를 설명한 거잖아. 그 원인이 진짜 딱 맞는 원인이라면 동일한 일이 또 발생했을 때 똑같은 결과가 나와야 해. 근데 이 세상은 그렇게 돌아가지 않거든요.
- 교수님: <이 세상을 다시 만들자>라는 책 추천드립니다 공돌이들에게 아주 추천함
- 모형과 파라미터
- 모형 = 모델: 데이터의 패턴을 나타내는 수식이나 프로그램
- 파라미터: 모형의 구체적 형태를 결정하는 수치
- 파라미터가 많을수록 복잡한 패턴을 나타낼 수 있다
- 인공신경망의 학습: 경사하강법
- 모형의 구조가 똑같아도 파라미터에 따라 결과가 달라진다
- 인공신경망은 아주 복잡하기 때문에 한번에 딱딱 맞는 파라미터를 찾을 수는 없고요
- 조금씩 찔러보면서 잘 하는 방향으로 파라미터를 몰아가는 거임 그게 경사하강법
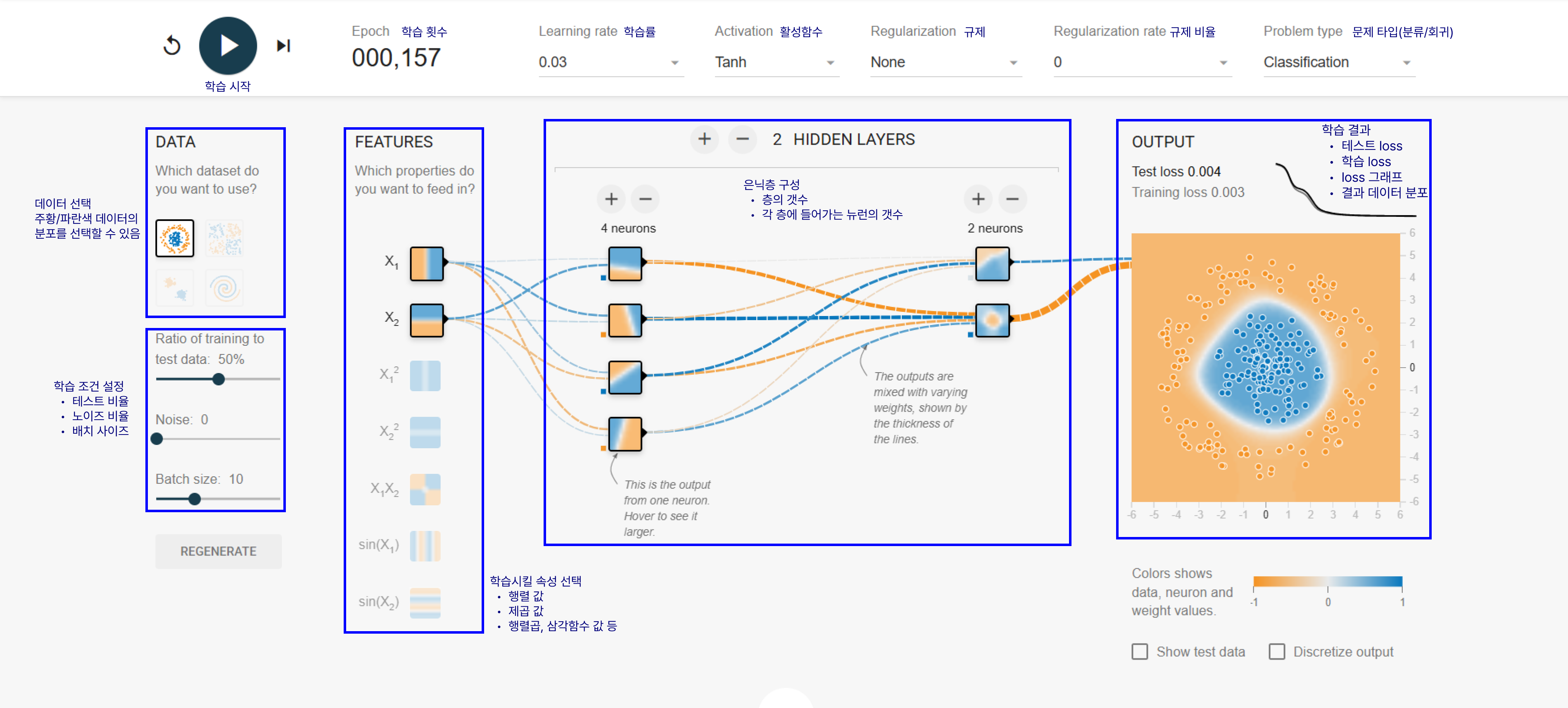
- 지도학습의 원리 실습
https://playground.tensorflow.org/: 인공신경망의 원리를 체험할 수 있는 사이트
![]()
https://teachablemachine.withgoogle.com/: 구글에서 데이터 올리고 간단하게 학습시켜볼 수 있는 사이트
- 난 이 게임을 해봤어요
- 화면에 나온 사람 수 세기: https://dapin1490.github.io/human-record-cctv/
- 개 고양이 구분하기: https://dapin1490.github.io/cat-n-dog/
- 덤: https://dapin1490.github.io/moyeobom-static/
- 난 이 게임을 해봤어요
- 딥러닝 이전과 이후의 특징 추출
- 딥러닝 이전에는 사람이 직접 특징을 추출해줬음
- 딥러닝은 거의 원본을 그대로 받아서 알아서 분석함
- 종단간 학습(end to end): 딥러닝 방식. 거의 원본을 받아서 학습함.
- 표상 학습(representation): 신경망이 과제를 수행하는 데 적합한 특징들을 내부적으로 학습
인간과 기계의 학습 방법 차이
대상 / 구분 인간 기계 정의 스스로 생각하는 인격화된 존재 비인격적 존재 데이터 요구량 소량, 없어도 가능 대량 필요 학습 범위 되는대로 다, 전이 가능 좁은 범위, 전이 어려움 - 제로 샷 러닝: 추가 데이터 없는 전이 학습
- 매우 다양한 범위의 문제를 하나의 모델에 학습시켜서 널리 쓰이게 하는 것
- 기존 문제와 유사한 새로운 문제도 가능
- 제로 샷 러닝: 추가 데이터 없는 전이 학습
이미지 파일의 형식
컴퓨터 그래픽의 방식
- 비트맵 방식: 이미지를 픽셀(pixel)로 표현
- 벡터 방식: 이미지를 선으로 표현
- 포인트 클라우드 방식: 점의 3차원 좌표로 표현
- 일반적으로 컴퓨터 비전에서는 비트맵 방식을 사용
비트맵 방식 bitmap
- 이미지를 작은 정사각형 모양의 픽셀로 저장하는 방식
- 각각의 픽셀이 밝기를 가짐
- 픽셀이 꺼지면(밝기 0) 검은 색이 되고, 최대로 켜지면 흰색. 그 중간에서는 회색.
- 대부분의 사진 및 비디오 파일 형식, 이미지 처리나 컴퓨터 비전에서도 주로 사용
- 비트맵 방식은 이미지를 확대하거나 축소할 때 왜곡이 생길 수 있음
- 이미지의 크기가 커지면, 이미지 한 장에 들어가는 점의 개수도 늘어나기 때문에 용량이 커짐
컬러 비트맵 이미지
- 여러 개의 픽셀을 합쳐서 표현
- 빛의 삼원색(RGB): 빨강(R), 초록(G), 파랑(B)
- 인쇄용 이미지는 CMYK를 사용
- 색상이 중요하지 않으면 흑백으로 변환하여 계산량을 절약
비트맵 저장 형식
- JPEG(Joint Photographic Experts Group)
- 대부분의 사진이나 이미지에 사용되며, 손실 압축 방식으로 이미지를 압축
- 편집/저장을 반복하면 화질이 열화됨
- GIF(Graphics Interchange Format)와 PNG(Portable Network Graphics)
- 작은 애니메이션 이미지나 로고, 아이콘 등에 사용
- 비손실 압축 방식으로 그래픽이나 웹 디자인에 많이 사용
- WebP
- Google에서 웹 페이지에서 더욱 빠르게 로딩되도록 개발한 영상/이미지 파일 포맷
- 기존의 JPEG와 PNG, GIF의 장점을 모두 합쳐서 손실 압축과 비손실 압축을 모두 지원
- 더 효율적인 압축 방식을 사용하기 때문에 파일 크기는 더 작고, 이미지 품질은 더 높은 특징
- tiff: Tagged Image File Format 출력용
- raw Raw Image File: 비압축 원본
벡터 방식 vector
- 벡터 방식은 이미지를 수학적인 곡선과 모양으로 표현
- 그래픽 디자인 및 로고 등에 사용
- 이미지를 확대하거나 축소할 때도 깨지지 않고 선명한 이미지를 유지
- 수학적인 곡선이므로 계산만 다시 하면 이미지를 무한히 확대/축소할 수 있어서, 이미지의 크기와 용량이 관계가 없음
- 카메라로 찍은 사진 등은 픽셀 방식의 형태여서 벡터 방식으로 저장하려면 변환이 필요
- 컴퓨터 비전에서는 벡터 방식은 잘 쓰지 않음
- 저장 형식
- pdf: Portable Document Format 문서용
- eps: Encapsulated PostScript 문서용 (pdf로 대체)
- svg: Scalable Vector Graphics 주로 웹 사이트에서 사용
포인트 클라우드
- 3D 이미지에 사용하는 방식
- 각각의 포인트는 이미지의 한 점을 나타내며 색상 정보도 함께 저장
- 주로 라이다(LiDAR) 같은 장비로 찍은 이미지를 표현할 때 사용
이미지 파일의 색상 모드
- RGB: 빨강, 초록, 파랑 3가지 색을 사용하는 모드
- RGBA: 빨강, 초록, 파랑 3가지 색과 투명도(알파 채널)를 사용하는 모드
- L: 이미지를 흑백으로 표현하는 모드
- 각 픽셀의 색상은 0부터 255까지의 값으로 표현
- 0은 검은색, 255는 흰색을 의미
- CMYK: 색상을 시안(Cyan), 마젠타(Magenta), 노랑(Yellow), 검정(Black) 4가지 색으로 나타내는 모드
- 주로 인쇄를 위한 이미지 파일에 사용
- 덤: 퍼플과 바이올렛의 차이
- 퍼플: 빨강 + 파랑
- 바이올렛: 가장 파장이 짧은 색 (좀 더 파랗게 생김)
PIL 라이브러리
- 기본적인 이미지 처리 라이브러리
설치
1
pip install pillow이미지 불러와서 보여주고 포맷 출력하기
1 2 3 4 5 6
from PIL import Image from IPython.display import display img = Image.open(r"..\data\balloon.webp") display(img) img.format, img.mode, img.size # ('WEBP', 'RGB', (1024, 1024))
흑백으로 바꿔서 출력하기
1 2
bw = img.convert("L") display(bw)
자동 컬러파레트로 색깔 갯수 제한해서 출력하기
1 2
bw = img.convert("P", palette=Image.ADAPTIVE, colors=5) display(bw)
OpenCV
설치
1
pip install opencv-python파일 열고 기본 정보 보기
1 2 3 4 5 6
import cv2 as cv image_path = r"..\data\balloon.webp" image = cv.imread(image_path) image.shape, image.size, image.dtype
이미지 보여주기: PIL과 3원색 순서가 달라서 변환 필요, cv 자체는 이미지를 배열로 저장함
1 2 3 4 5 6 7 8
from PIL import Image # Pillow 라이브러리 임포트 def show(image): # OpenCV 형식의 image를 PIL로 바꿔주는 함수 rgb = cv.cvtColor(image, cv.COLOR_BGR2RGB) # BGR → RGB로 채널 순서 변경 return Image.fromarray(rgb) # 객체 변환: 넘파이 배열 → PIL 형식으로 show(image)
비디오 불러오고 기본 정보 알아내기
1 2 3
video = cv.VideoCapture(r'../data/자전거.mp4') fps = video.get(cv.CAP_PROP_FPS) frame_interval = int(1000 / fps)
재생하기
1 2 3 4 5 6 7 8 9 10 11 12 13 14
while(video.isOpened()): # 파일이 열려있는 동안 ret, frame = video.read() # 한 프레임 읽음 if not ret: # 없으면 break # 중단 gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY) # 흑백으로 cv.imshow('frame', gray) # 출력 if cv.waitKey(frame_interval) == ord('q'): # 키 입력을 기다림, q가 입력되면 break # 중단 video.release() # 파일 닫음 cv.destroyAllWindows() # 창 닫음
웹캠 잡기
1 2 3 4 5 6 7 8 9 10 11 12 13 14
video = cv.VideoCapture(0) # 캡처 준비 # 캡처할 이미지의 폭을 640으로 설정, 높이를 480으로 설정 video.set(cv.CAP_PROP_FRAME_WIDTH, 640) video.set(cv.CAP_PROP_FRAME_HEIGHT, 480) # 캡처 ret, img = video.read() # ret: 성공 여부 # img: 캡처된 이미지(넘파이 배열) video.release() # 카메라 해제 display(show(img))
이미지 연산
이미지끼리 연산할 때는 서로 크기가 같아야 함
이미지에 값 더하기: 그냥 덧셈하면 255보다 큰 값이 생길 수 있으니 cv를 쓰는 게 안전함
1
show(cv.add(image, 100))
이미지끼리 더하기
1 2 3
chair = cv.imread('../data/chair.webp') explosion = cv.imread('../data/explosion.webp') display(show(cv.add(chair, explosion)))
이미지 가중치 더하기
1
display(show(cv.addWeighted(chair, 0.2, explosion, 0.8, 10)))
네거티브
1
show(255 - image) # negative
이미지끼리 빼기
1 2
black_circle = cv.imread('../data/black_circle.png') display(show(cv.subtract(chair, black_circle)))
두 개의 이미지 차이의 절대값(순서에 영향 X)
1 2
cv.absdiff(chair, explosion) cv.absdiff(explosion, chair)
곱셈 (1 이상의 값을 곱하면 밝아짐)
1
show(cv.multiply(image, 3.0)) # 3.0을 곱하면 모든 픽셀의 밝기가 3배 밝아짐
나눗셈 (1 이상의 값을 나누면 어두워짐)
1
show(cv.divide(image, 3.0)) # 3.0으로 나누면 모든 픽셀의 밝기가 1/3으로 어두워짐
컬러스페이스 바꾸기
- 색을 표현하는 방법
- RGB: 빛의 삼원색인 빨강(R), 초록(G), 파랑(B)을 사용
- 과거에는 BGR이 널리 쓰이다, 현재는 RGB로 주류가 바뀜
- OpenCV는 BGR이 주로 쓰이던 시절에 개발되어 BGR이 기본
- HSV:
- 색상(Hue): 빨강, 파랑, 노랑 등
- 채도(Saturation): 진하다, 흐리다
- 명도(Value): 밝다, 어둡다
- Gray: 흑백
- RGB: 빛의 삼원색인 빨강(R), 초록(G), 파랑(B)을 사용
BGR → 흑백
1 2 3
gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY) Image.fromarray(gray) # same show(gray)
흑백 → BGR (없는 색이 생기지는 않음)
1
show(cv.cvtColor(gray, cv.COLOR_GRAY2BGR))
BGR → HSV
1
show(cv.cvtColor(image, cv.COLOR_BGR2HSV))
채널 분리
BGR 채널을 분리
1
b, g, r = cv.split(image)
B 채널만 보기(흑백으로 보임)
1
Image.fromarray(b)
GR 채널을 0으로 채우면 파란색으로 볼 수 있음
1 2
z = np.zeros_like(b) # b와 같은 모양의 0으로 가득찬 배열 show(cv.merge((b, z, z))) # 초록과 빨강은 0으로 채워서 합침
히스토그램 균일화
보통 raw 이미지는 RGB 히스토그램이 균일하지 않다
![]()
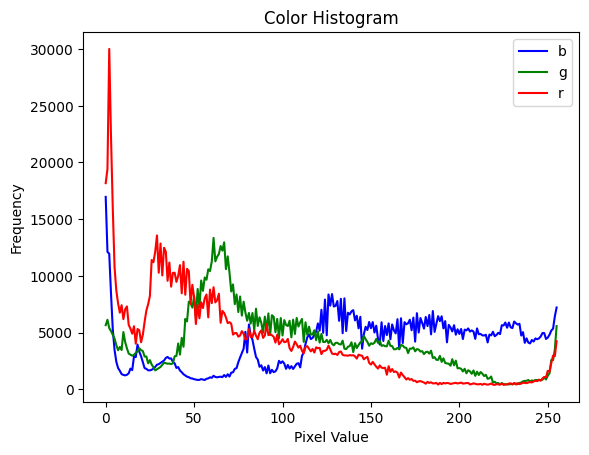
그냥 히스토그램 균일화
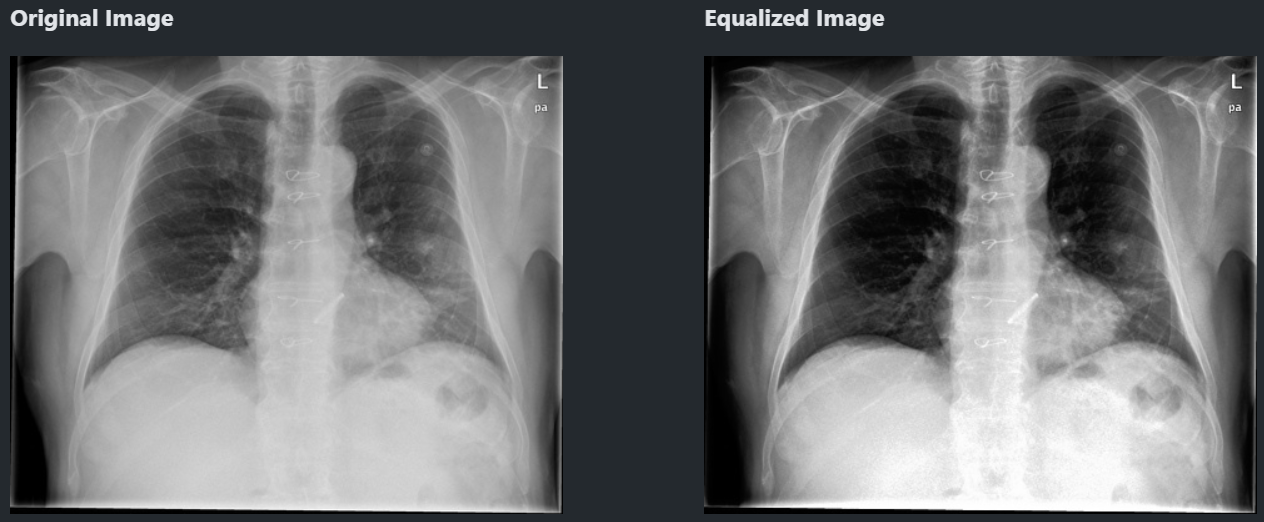
저 히스토그램을 서로 비슷비슷하게 맞춰주는 게 히스토그램 균일화. 기본적인 전처리임.
1
cv.equalizeHist(image)
![]()
- 명암이 좀 더 확실해지는데 대신 특징이 일부 사라질 수 있음.
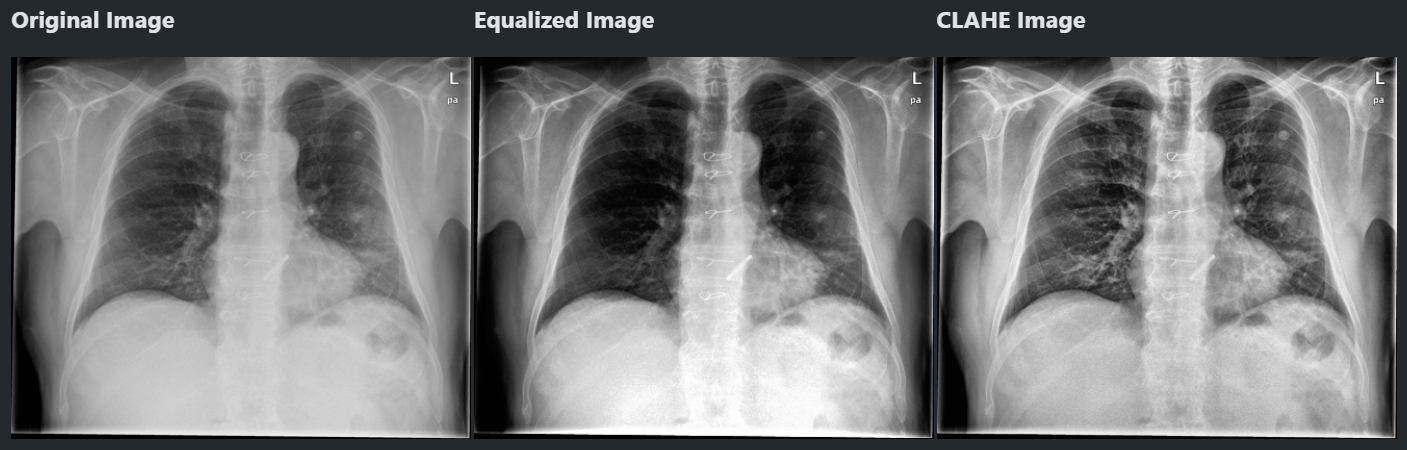
CLAHE 히스토그램 균일화
- 그래서 준비했습니다 CLAHE 히스토그램 균일화
- 이미지를 여러 개의 타일로 나누어 타일마다 균일화
- 노이즈가 있을 수 있으므로 제한을 넘는 값은 모든 영역에 균일하게 배분
1 2 3 4
clahe = cv.createCLAHE( clipLimit=2.0, # 밝기 제한을 설정. 보통 2.0-4.0 tileGridSize=(8, 8)) # 이미지를 가로 8개, 세로 8개의 타일 -> 총 64개로 나눔 clahed = clahe.apply(src)
![]()
- 이제 좀 특징이 잘보이지
컬러 이미지의 히스토그램 균일화
컬러 이미지를 그냥 균일화하면 색깔이 바뀌어버린다
1 2 3 4 5 6
src = cv.imread('../data/low.jpg') b,g,r = cv.split(src) be = cv.equalizeHist(b) # 파랑의 균일화 ge = cv.equalizeHist(g) # 초록의 균일화 re = cv.equalizeHist(r) # 빨강의 균일화 eqd1 = cv.merge((be,ge,re)) # 결합
![]()

HSV 히스토그램 균일화
그럴 때는 HSV로 히스토그램 균일화를 해야 한다
1 2 3 4 5
hsv = cv.cvtColor(src, cv.COLOR_BGR2HSV) # HSV로 바꿈 h,s,v = cv.split(hsv) # 색상(H) 채도(S) 명도(V)를 분리 eqd_v = cv.equalizeHist(v) # 밝기만 균일화(어두운 곳은 어둡게, 밝은 곳은 밝게) mgd = cv.merge((h,s,eqd_v)) # 색상과 채도는 그대로, 밝기만 바꿔서 합침 eqd2 = cv.cvtColor(mgd, cv.COLOR_HSV2BGR) # BGR로 바꿈
![]()
- 색깔은 지키고 명암은 확실해졌지

히스토그램 이진화
이 이미지는 앞으로 흑 or 백 2색만 남는다
1 2 3 4
src = cv.imread('../data/newspaper.png', cv.IMREAD_GRAYSCALE) hist = cv.calcHist([src], [0], mask=None, histSize=[256], ranges=[0, 256]) th, bin = cv.threshold(src, 190, 255, cv.THRESH_BINARY) show(bin)
![]()
- pdf 스캔 앱으로 사진 찍은 것처럼 생겼지
- 대신 이미지가 좀 더러워지긴 했는데 저건 좀 더 보정하면 됨

이진화 방법
- cv.THRESH_BINARY: 임계값 이상 = 최댓값, 임계값 이하 = 0
- cv.THRESH_BINARY_INV: 위의 반전
- cv.THRESH_TOZERO: 임계값 이하만 0으로
- cv.THRESH_TOZERO_INV: 위의 반전
- cv.THRESH_TRUNC: 임계값 이상만 임계값으로
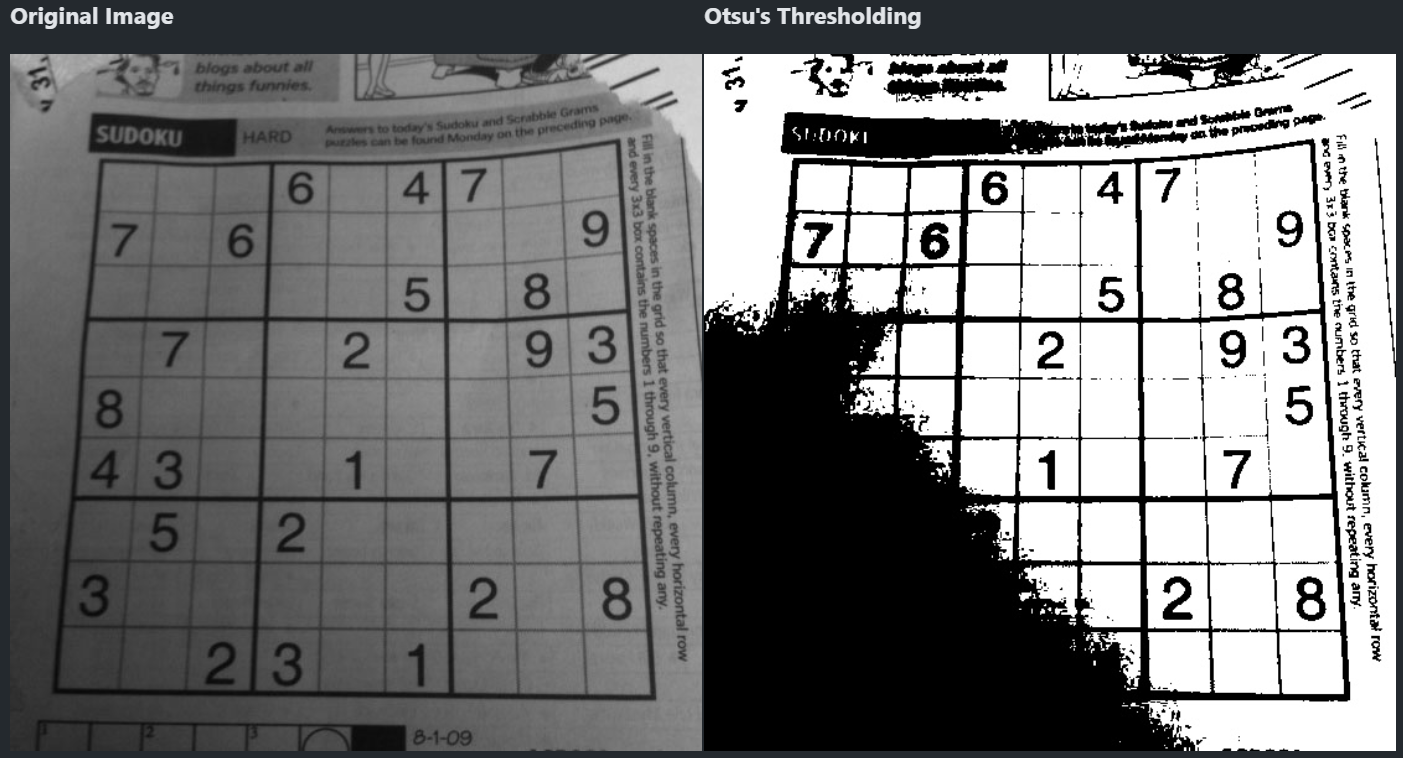
오츠의 이진화 알고리즘
모든 임계값 중에서 명암 분포가 가장 균일한 것을 자동으로 선택하는 알고리즘
1 2
th, bin2 = cv.threshold(src, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU) show(bin2)
![]()
- 비교적? 적당함

global thresholding 문제
조명이 일정하지 않거나 배경색이 여러 개이면 하나의 문턱값으로 구분할 경우 문제가 됨
1 2
src = cv.imread('../data/sudoku.png', cv.IMREAD_GRAYSCALE) th, bin = cv.threshold(src, 0, 255, cv.THRESH_BINARY | cv.THRESH_OTSU)
![]()
- 밝은 건 하얗게 사라졌고 어두운 건 검게 사라짐
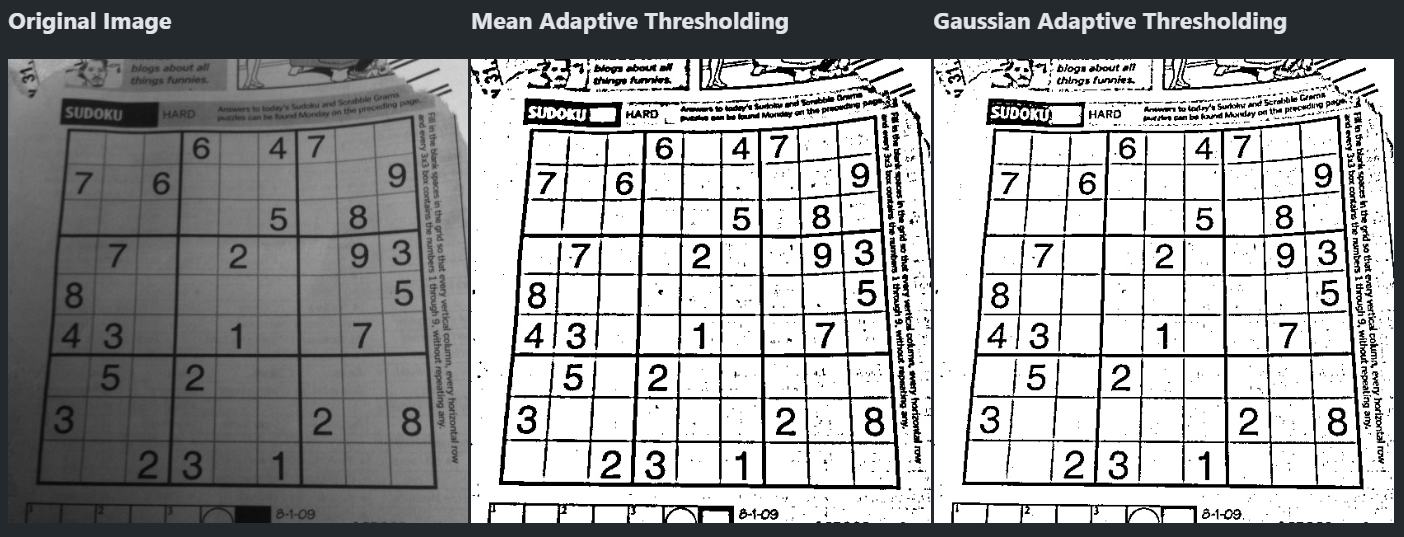
Adaptive Thresholding
이미지를 여러 개의 블록으로 나누어 이진화
1 2 3 4 5 6 7 8 9 10
block_size = 15 # 주변 15픽셀을 참고 C = 5 # 가감할 상수 # 주변 픽셀의 평균을 이용: 선명하지만 노이즈 adap2 = cv.adaptiveThreshold( src, 255, cv.ADAPTIVE_THRESH_MEAN_C, cv.THRESH_BINARY, block_size, C) # 가우시안 분포를 이용: 노이즈가 적음 adap3 = cv.adaptiveThreshold( src, 255, cv.ADAPTIVE_THRESH_GAUSSIAN_C, cv.THRESH_BINARY, block_size, C)
![]()
- 훨씬 잘보인다
Look-Up Table을 이용한 색 변환
- 픽셀마다 색상 변환을 계산하려면 그림이 크거나 많을 때 많은 계산이 필요함
- 미리 픽셀 값별로 변환할 값을 Look-Up Table로 만들어두면 계산을 절약할 수 있음
이건 밝기를 8단계로 분류한 이미지 만드는 코드
1 2 3 4 5 6 7 8 9 10 11
src = cv.imread('../data/balloon.webp') # 예제 파일 ones = np.ones(32, dtype=np.uint8) # 1을 32개 만듦 lut = np.concatenate(( ones * 0, ones * 32, ones * 64, ones * 96, # 0-31까지 32개는 0, 32-63까지 32개는 32, 64-95까지 32개는 64, … ones * 128, ones * 160, ones * 192, ones * 224), ) print(lut.shape) # 0-255까지 총 256개의 픽셀값을 어떻게 계산할지 Look-Up Table로 만듦 dst = cv.LUT(src, lut) show(dst) # 밝기가 8단계(0, 32, 64, … 224)
![]()
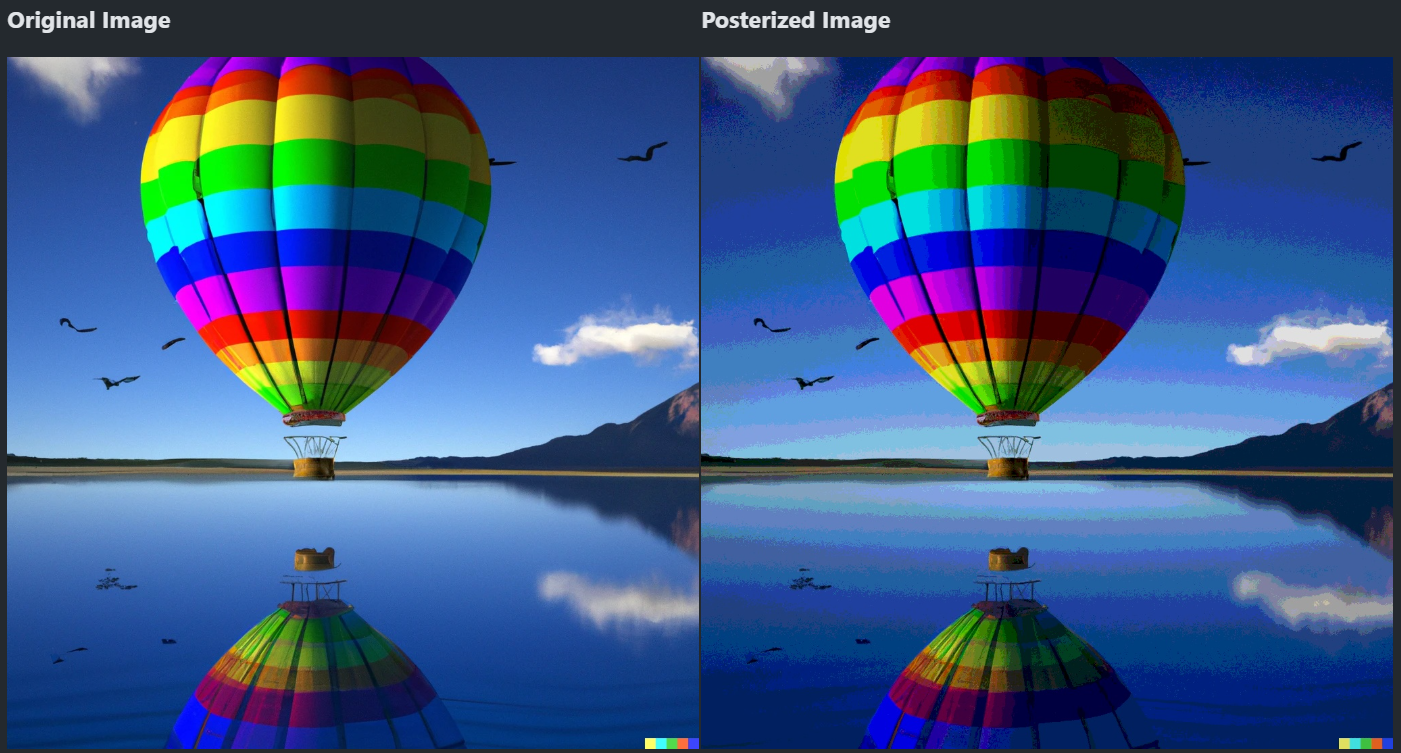
감마 보정
- 일괄적으로 밝기를 높이면 밝은 영역이 모두 흰색이 되어 디테일이 뭉개짐 (밝기를 낮출 때도 같음)
- 감마 함수를 이용하여 밝기를 비선형으로 보정할 수 있음
- 감마(γ) < 1: 어두운 곳이 더 밝아 짐
- 감마(γ) > 1: 밝은 곳이 더 어두워 짐
1
2
3
4
5
6
lut = np.zeros(256, dtype=np.uint8)
gamma = 0.5 # 어두운 곳을 밝게
# 보정 함수를 미리 계산하여 Look-up Table을 채움
for i in range(256):
lut[i] = np.power(i/255.0, gamma) * 255.
dst = cv.LUT(src, lut) # LUT를 적용하면 픽셀마다 계산할 필요 없음
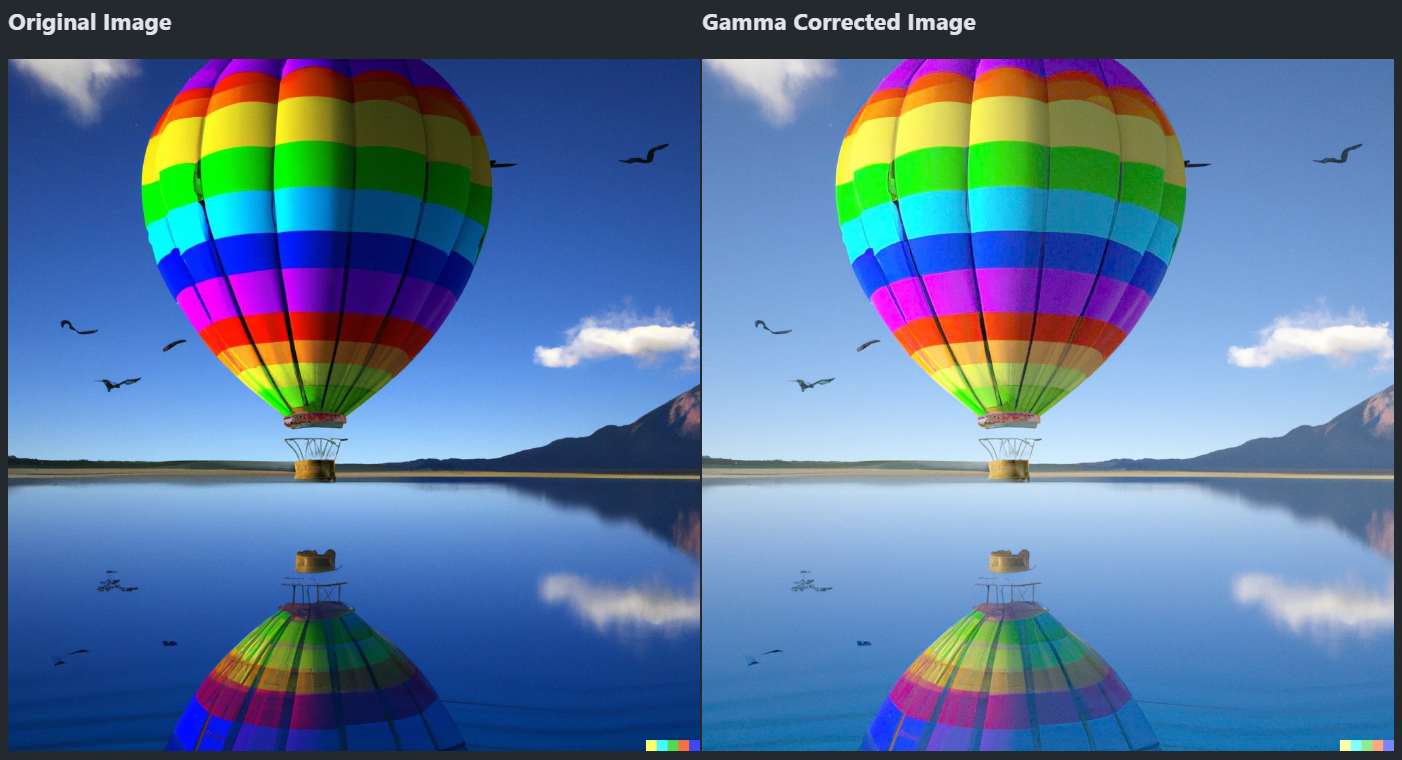
- 이미지가 좀 더 화사하고 예뻐졌다