
배경 및 목표 (Situation & Task)
- 머신 비전을 중심으로 손글씨 모티브 웹 폰트와 실제 사람 5명의 손글씨를 분류하는 모델을 만들고 사용 가능한 UI를 구현한다
- 업무·교육 맥락: 폰트 식별이 필요한 디자인 업무 효율, 또는 특정 손글씨의 작성자 판별이 필요한 시나리오를 가정.
- 과제 분해
- Stage 1: 합성·실제에 가까운 단어 이미지에서 폰트 클래스(8개) 분류.
- Stage 2: Stage 1에서 학습한 백본 특징을 활용해 팀원 5명 수준의 작성자 식별. → 초기 계획은 이러했으나 이후 진행 과정에서 stage 1 사전학습이 오히려 stage 2 학습에 방해가 됨을 확인하여 별도로 학습함.
- 설계상 제약: 문장 입력 시에는 전처리 단계에서 작은 단위로 분리 후, 단어별 예측에 투표(Voting)로 최종 결과를 내는 흐름을 문서로 정의함.
역할 및 행동 (Action)
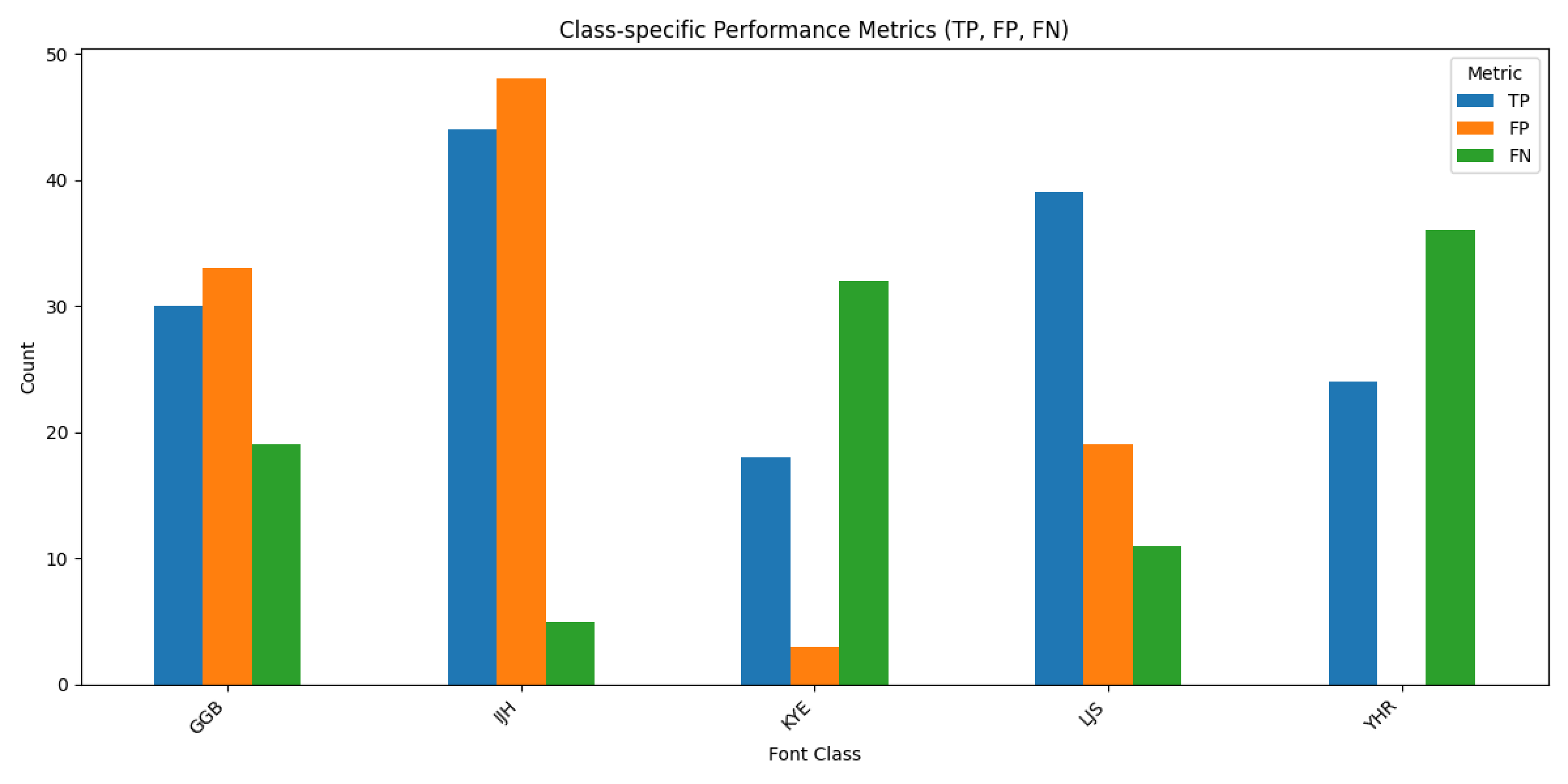
- 팀원들이 작성한 손글씨 이미지를 단어 단위로 분할하여 데이터셋을 만들었음
![]()
- stage 1: 경량, 빠른 학습을 목적으로 MobileNetV2를 선택하였으며, 하이퍼파라미터 및 모델 구성을 바꿔가며 손글씨를 학습시키려고 하였으나, 디지털 폰트 특성상 일관된 특징을 보이며, 손글씨 모티브라는 설정으로 인해 각 폰트의 특색이 너무 확실하여 3번 이하의 에포크만으로도 과적합이 발생하였음. (학습 정확도와 테스트 정확도가 모두 100%였음. 이는 통상적인 AI 모델이라면 확실하게 과적합된 것임.)
- 모바일넷 배치 32, 에포크 1 → 테스트 정확도 100%
- 모바일넷 배치 80, 에포크 3 → 테스트셋 중 단 1개 틀림
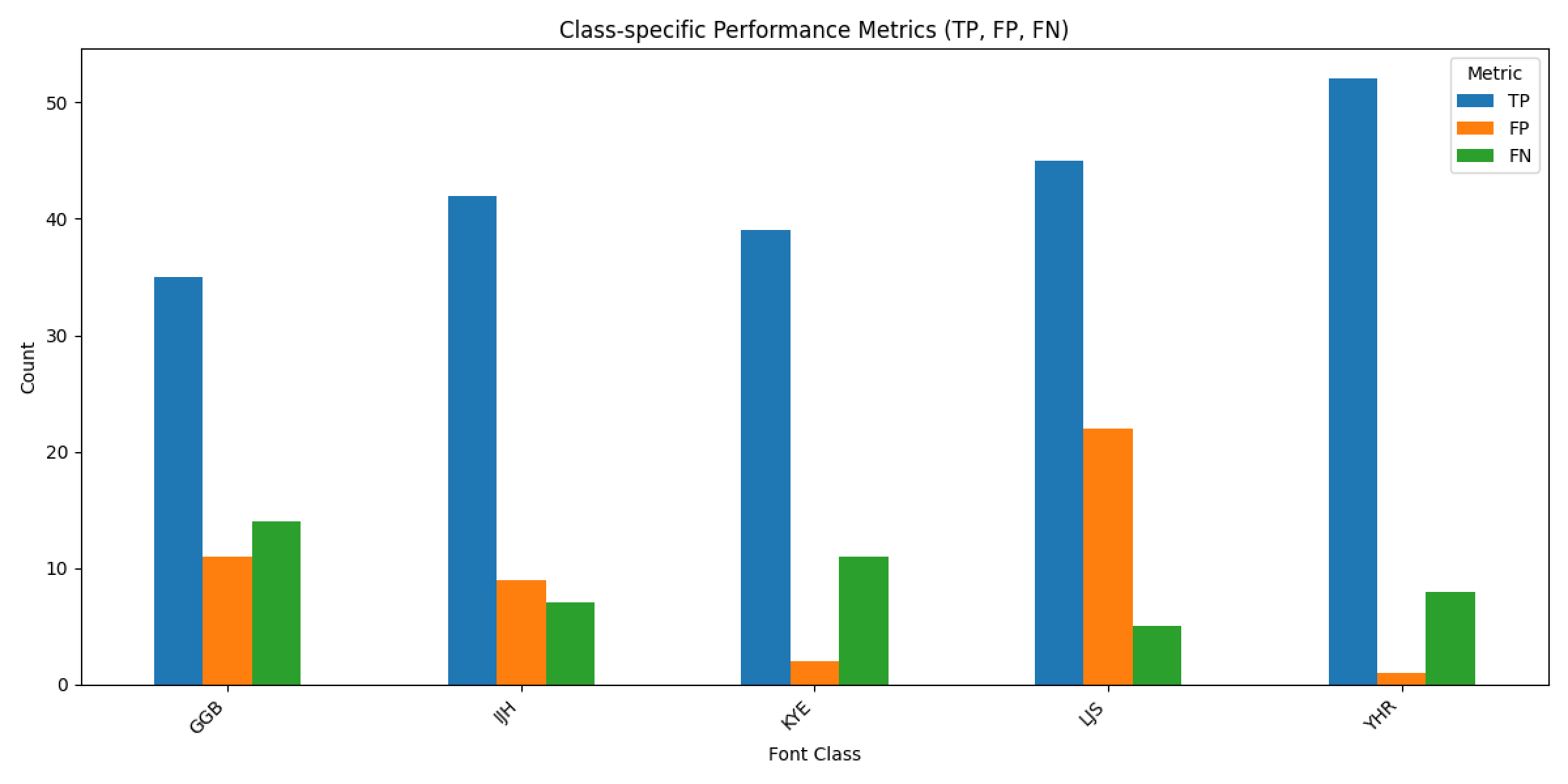
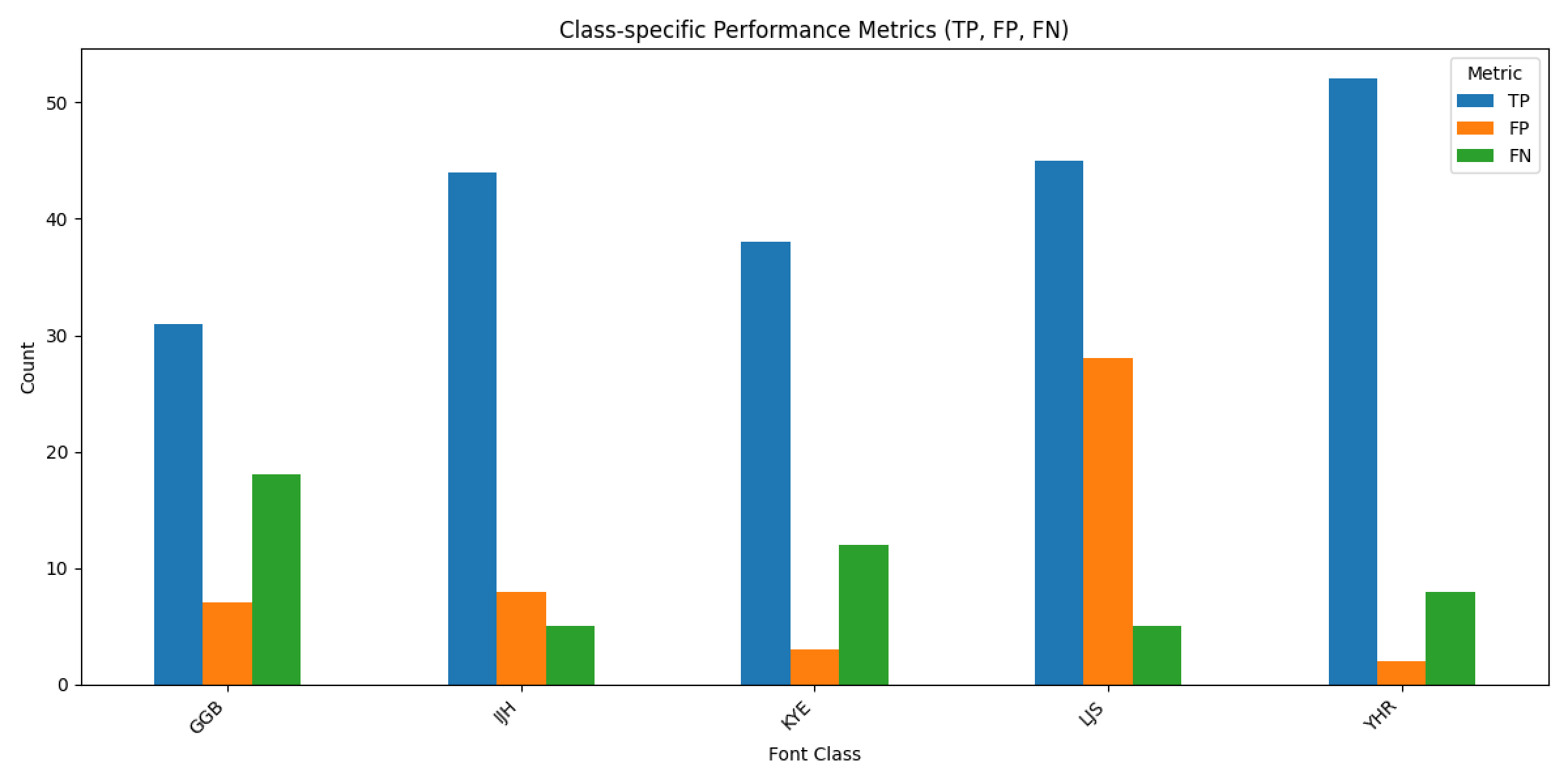
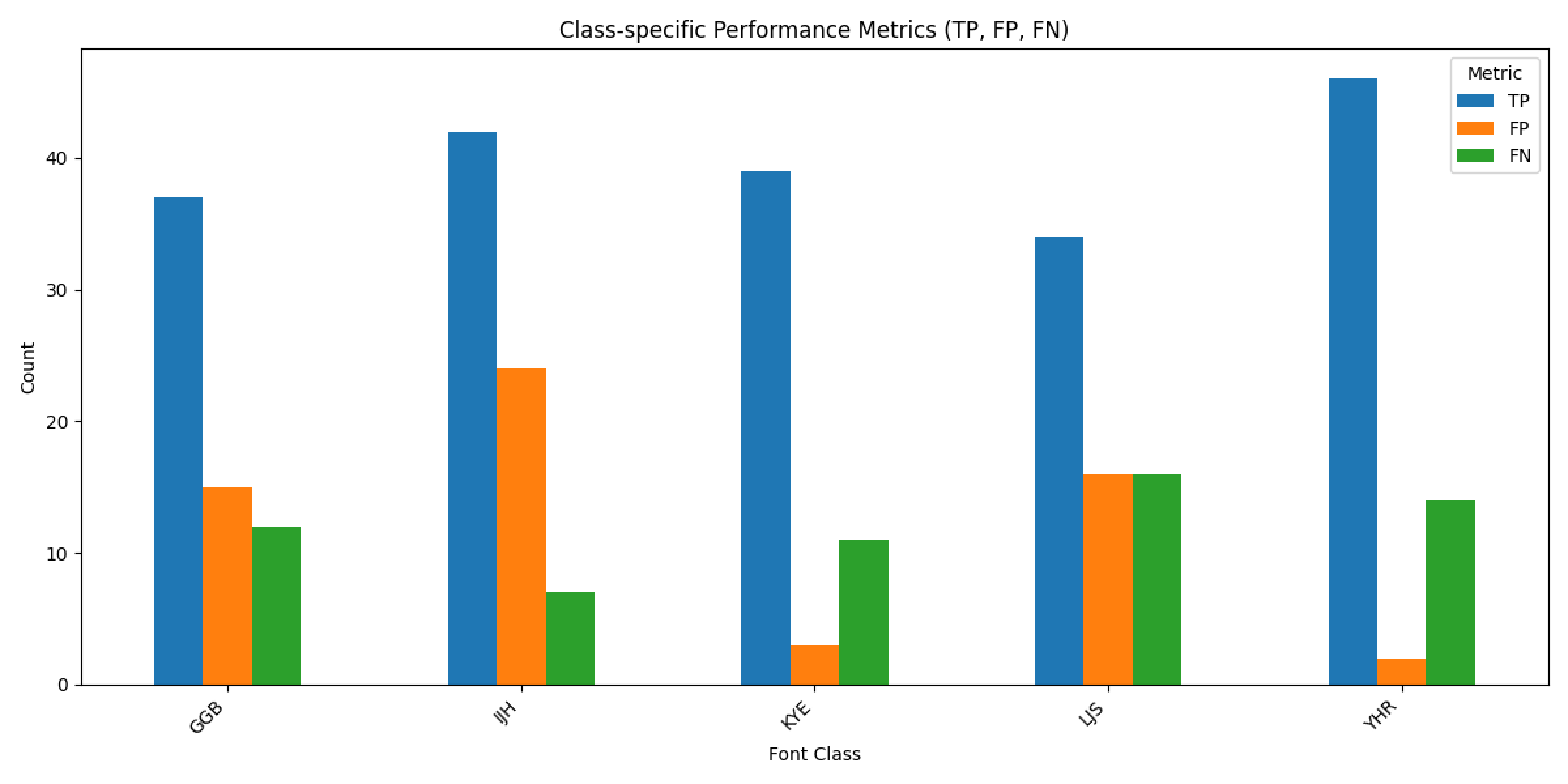
- 이정도면 전이학습 없이 기본적인 CNN으로도 성능을 낼 수 있을 것 같아 시도하였고, 배치 128, 에포크 10으로 96.3% 정확도 달성
![]()
- stage 2: 기존 목표는 stage 1의 학습 가중치를 백본으로 하여 전이학습할 계획이었으나, 후술할 사유로 전이학습 없이 별도로 학습하게 됨
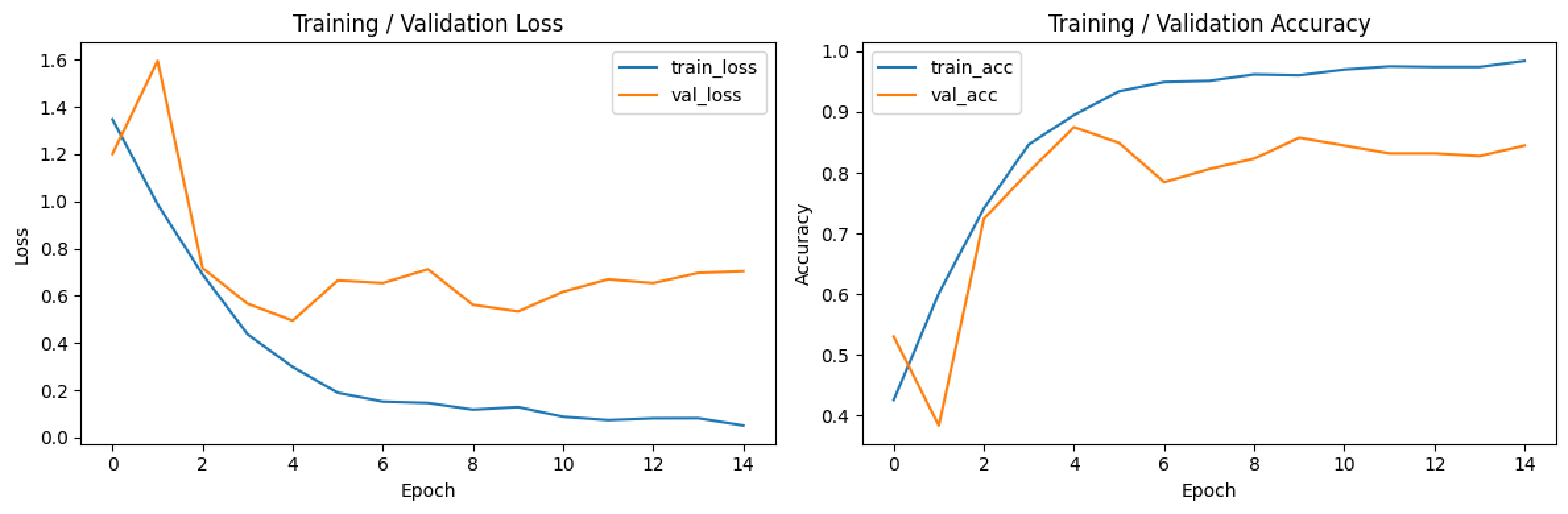
- 모바일넷 폰트 학습(배치 32, 에포크 3) 모델로부터 전이학습, 에포크 30, 배치 80 → 정확도 32.17% → 이정도면 찍기에 가까운 수준
![]()
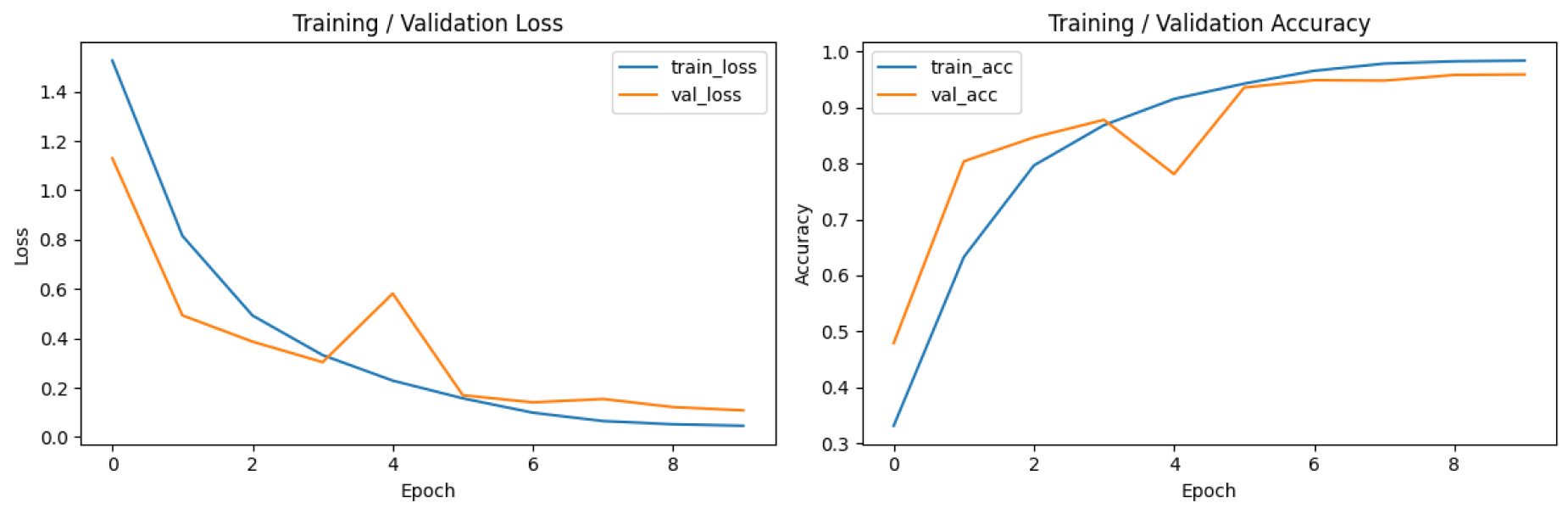
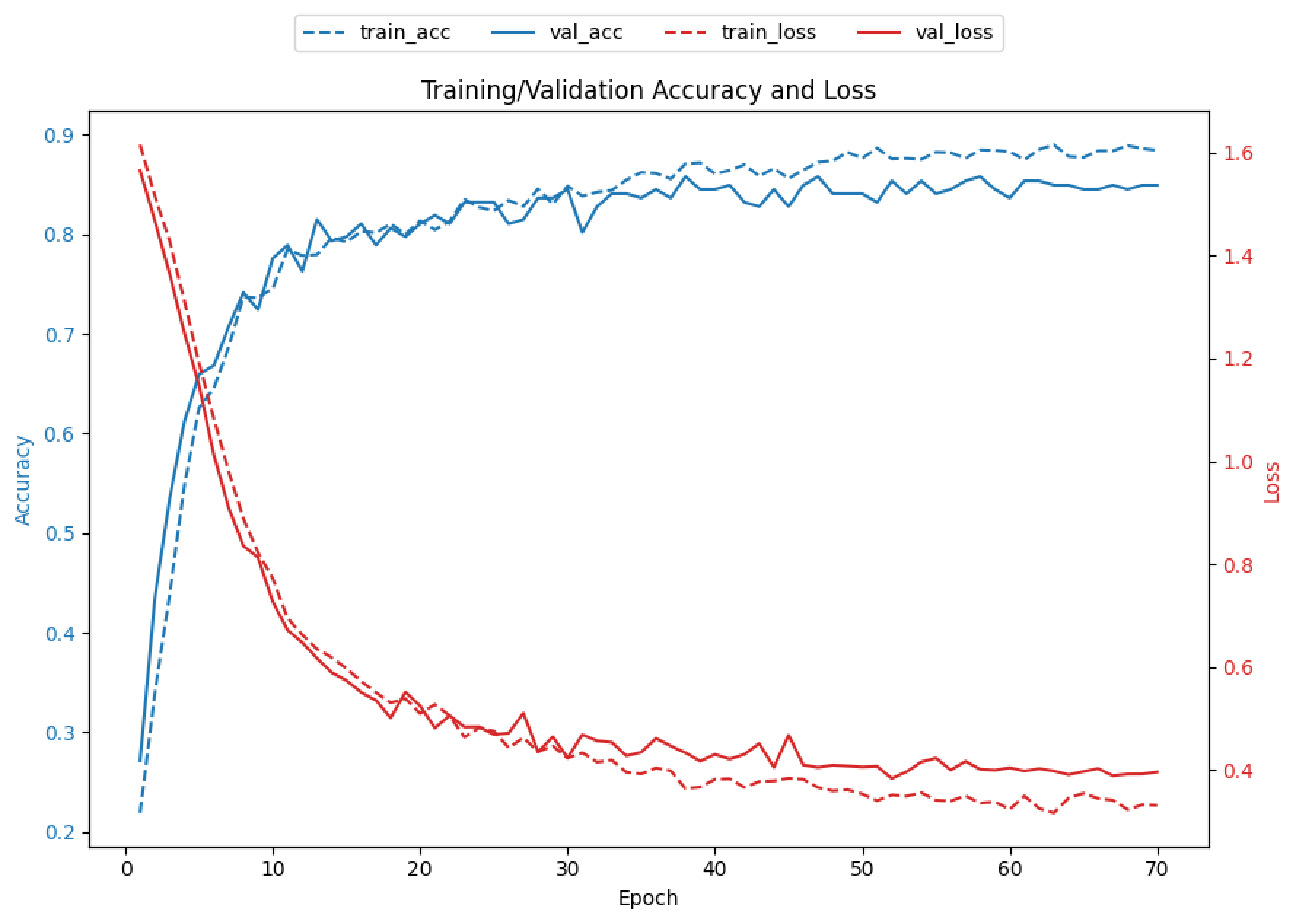
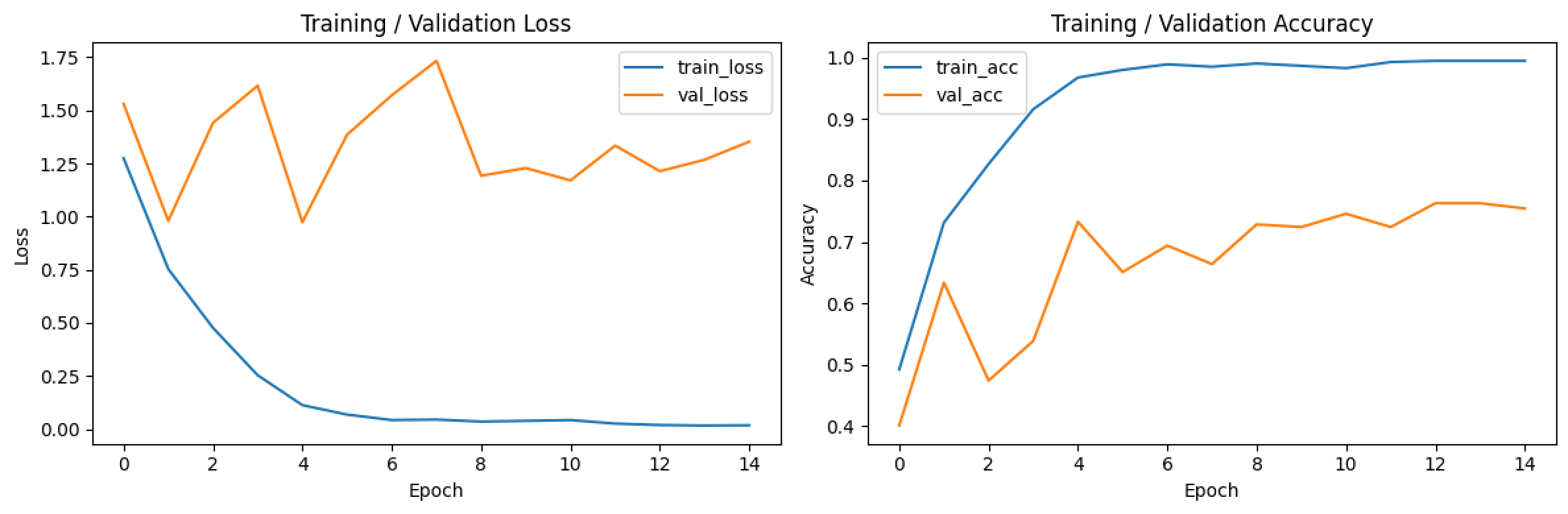
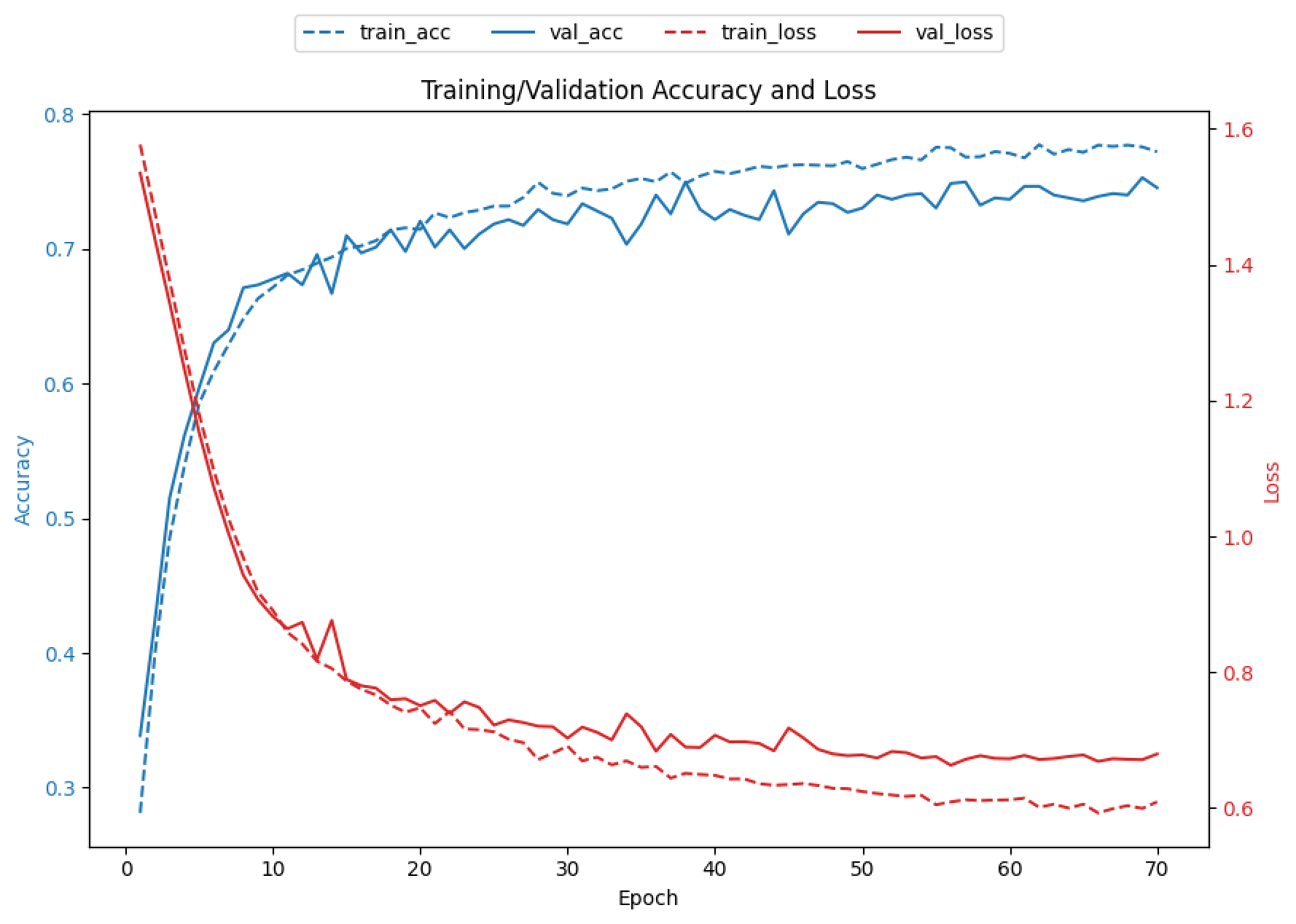
- 배치를 20으로 줄이고 에포크를 70으로 늘려도 정확도는 37.6%에 불과했음. 다만 학습 그래프를 볼 때 loss 그래프가 꾸준히 하향하고 정확도 그래프가 꾸준히 상향하여 에포크를 늘려보기로 했음
![]()
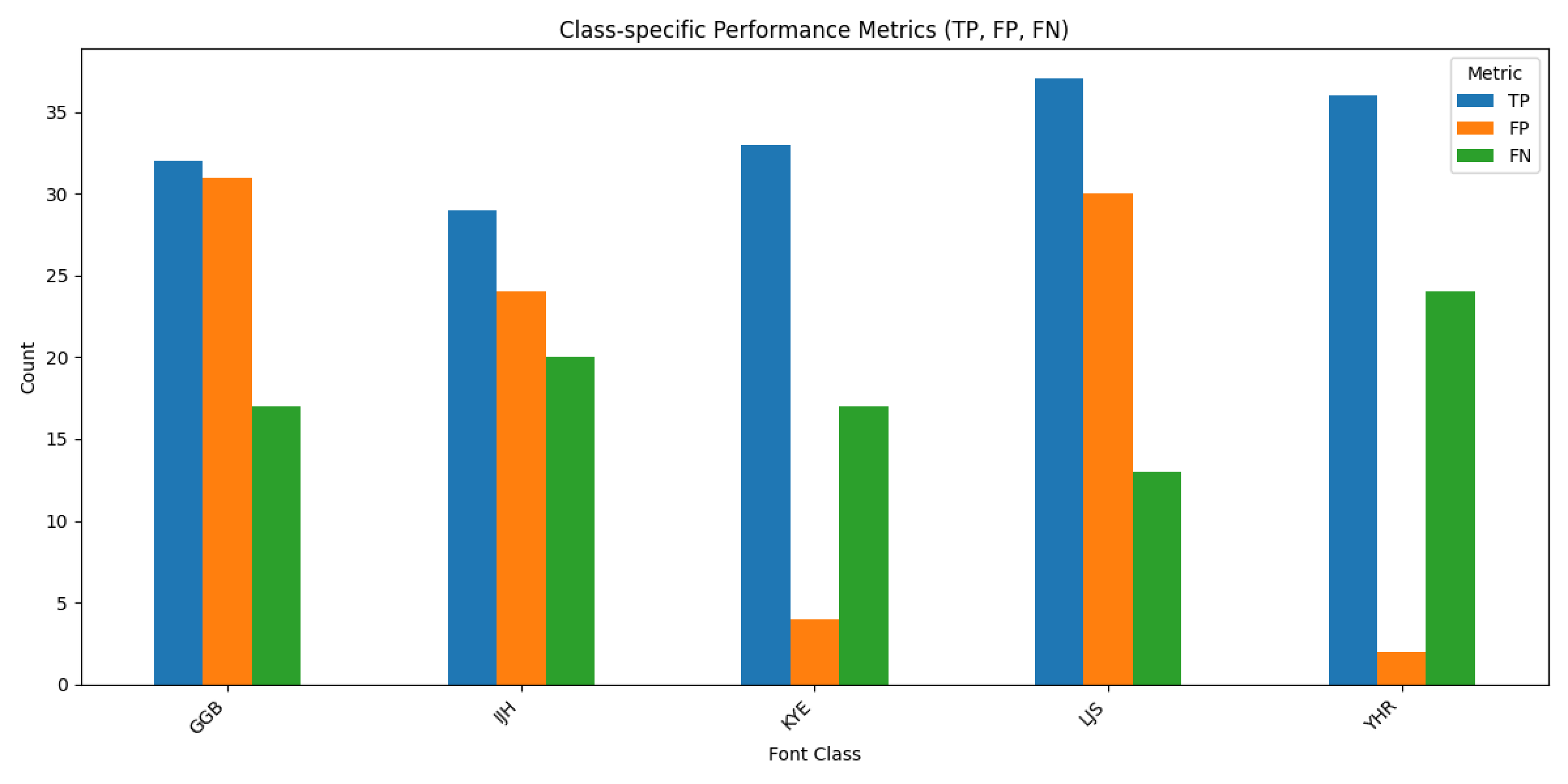
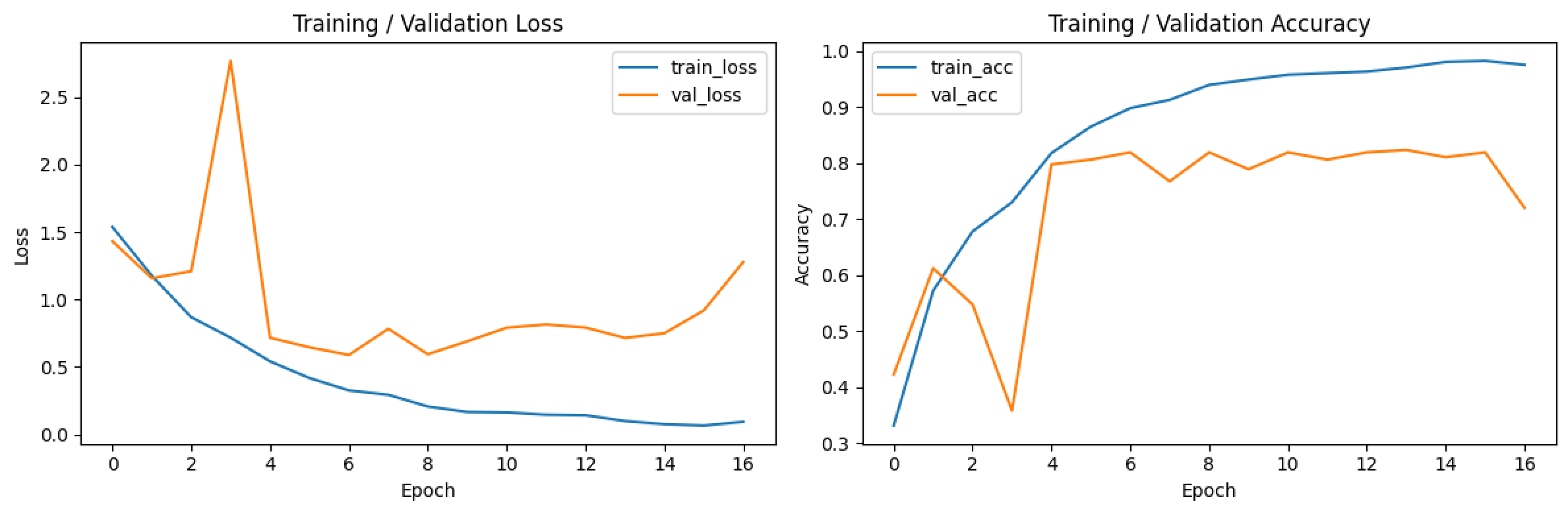
- 다른 조건은 그대로 두고 에포크만 200으로 늘려봤을 때, 정확도는 51.94%까지 상승했으나 학습 그래프가 수렴하는 형태를 보여 과적합이 발생했다 판단. 더이상 에포크를 늘리는 것은 의미가 없다고 판단함.
![]()
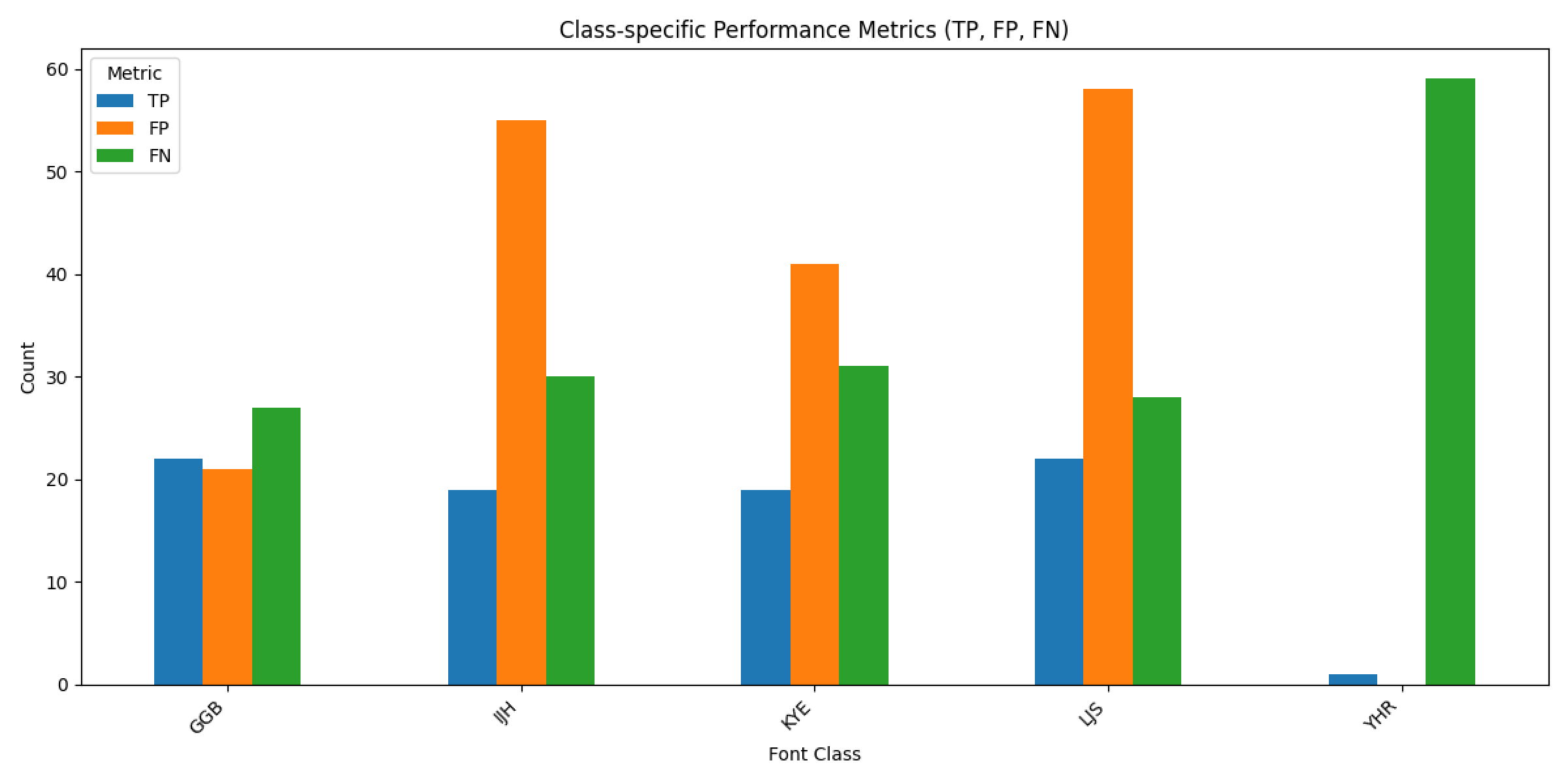
- 웹 폰트와 손글씨의 데이터 특성이 지나치게 다른 것이 문제일까 싶어 폰트를 먼저 학습시키지 않고 바로 모바일넷 → 손글씨로 학습시킴. 배치 20, 에포크 70으로 정확도 64.73%. 마찬가지로 학습 그래프 후반부에 과적합이 발견되나 성능 자체는 향상되었으므로 폰트 사전학습이 오히려 방해됨을 입증함. 웹 폰트의 경우 손글씨를 모티브로 했다고 해도 같은 글자를 출력하면 항상 동일한 이미지가 나올 수 있지만, 사람이 직접 글씨를 쓸 경우 같은 글자를 쓰더라도 완전히 동일할 수 없기 때문에 이러한 규칙성의 차이가 원인이었던 것으로 판단함. 웹 폰트의 규칙성을 학습한 모델에게 손글씨의 불규칙성을 학습시키려고 하니 비효율적이었던 것.
![]()
![]()
- 경량화 및 더 간결한 특징 추출을 위해 이미지의 해상도를 224에서 128로 줄여 동일 조건에서 다시 학습시켜보았으나 정확도는 68.6%에 그쳤고 과적합은 더 빨리 발생했음.
![]()
![]()
- 이 시점에서 다시 CNN을 시도함. 배치 16으로 에포크 10 학습시켰더니 학습셋 정확도는 100%지만 테스트셋 정확도가 60.08%로 상당히 빨리 과적합이 발생함.
![]()
![]()
- 모델이 너무 깊은가 싶어 레이어 수를 줄이고 대신 노드 수를 늘려 다시 동일 조건 학습. 학습 시 정확도는 99%였지만 테스트 정확도는 75%, 여전히 과적합.
![]()
- 그렇다면 모델이 아예 훨씬 더 깊고 복잡해진다면 손글씨의 특징점을 구분하는 데 도움이 될까 싶어 레이어를 늘리고, 배치 64, 에포크 50 학습 시도했으나 에포크 17에서 조기종료되었음. 학습 정확도는 97.52%, 검증 정확도는 71.98%. 유의미한 성과는 거두지 못했음.
![]()
- CNN의 레이어 수를 줄일 때 노드 수를 늘리지 않고 그대로 유지했어야 제대로 된 비교가 되었을 것 같은데 미처 거기까지 생각하지 못해 그러지 않았던 점이 아쉬움.
- 이후 이러한 ‘글씨 구분’ 관련 문제들에 사용되는 기법을 조사하여 샴 네트워크와 엘라스틱 왜곡이라는 기법을 알아내었고, 그 둘을 동시에 적용하여 모델을 만들고자 했으나 샴 네트워크 실행 시간이 너무 오래걸려 포기, 엘라스틱 왜곡만 데이터 증강 기법으로 적용하기로 함.
![]()
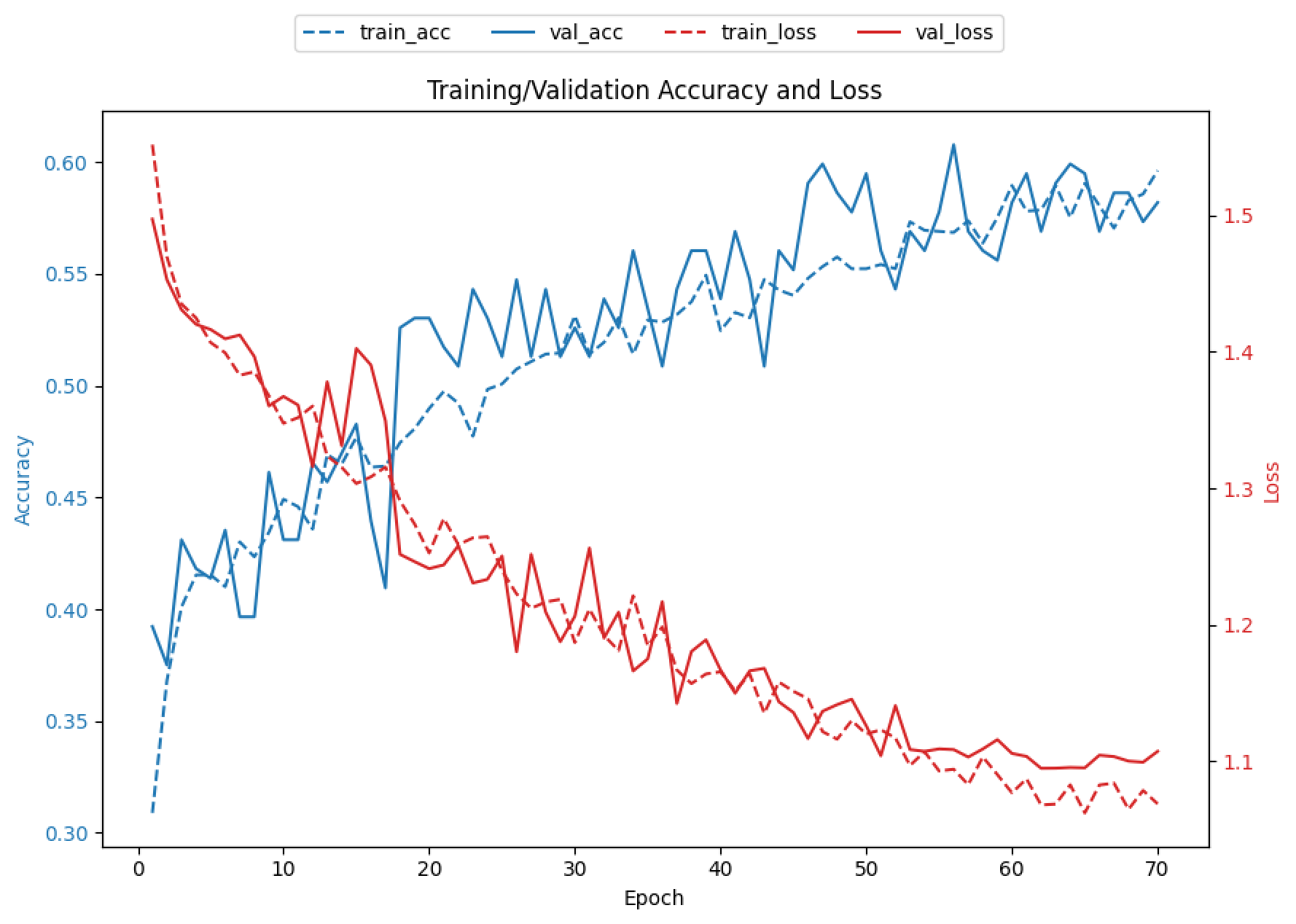
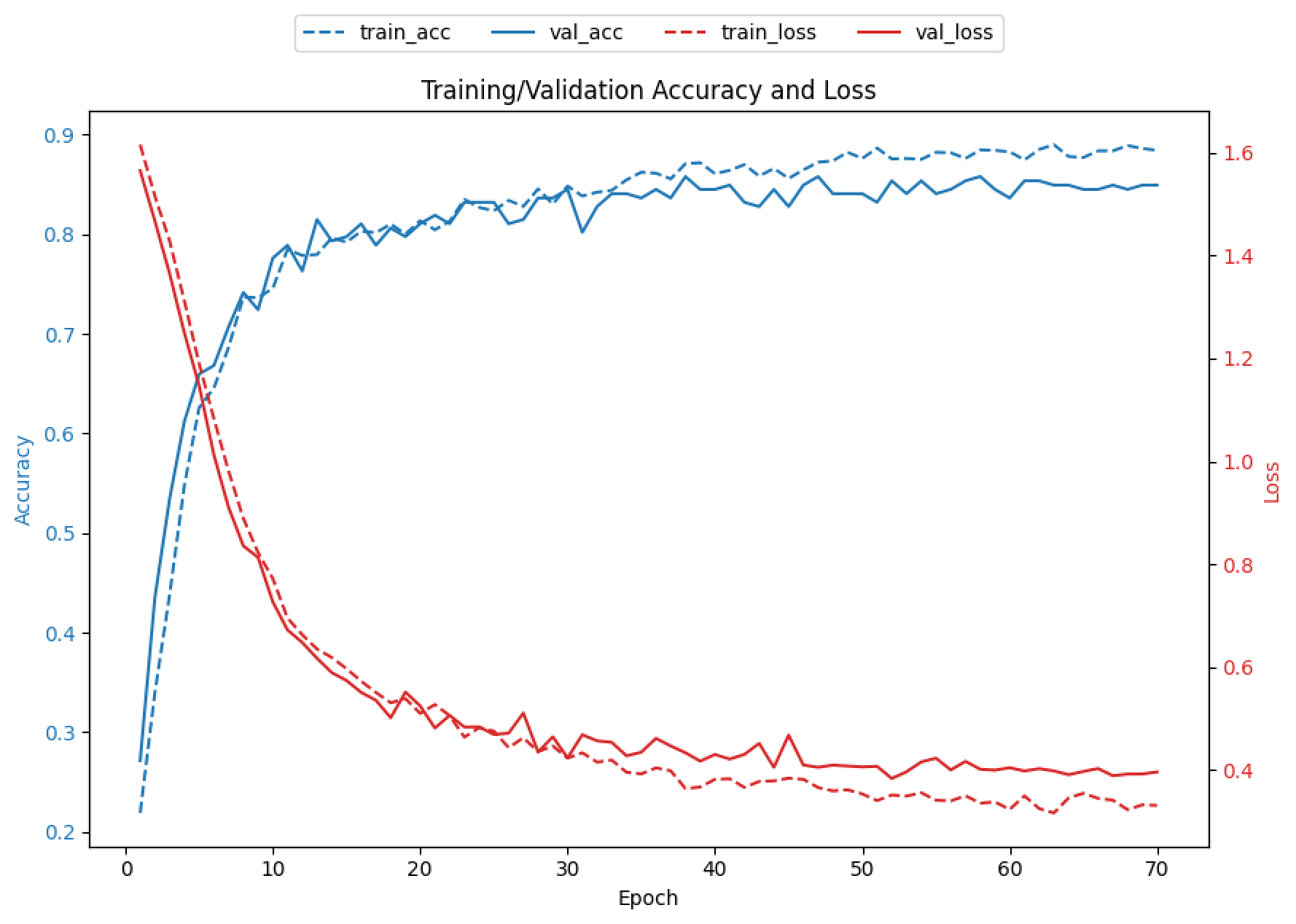
- 원본:증강 = 1:3 배율로 엘라스틱 왜곡을 적용하여 새 데이터셋을 만들었고(테스트셋은 증강하지 않음), 배치 64, 에포크 70으로 모바일넷에 학습시켜 82.56%의 정확도 달성. 학습 그래프에 과적합이 보이지 않아 에포크를 늘려보기로 함
![]()
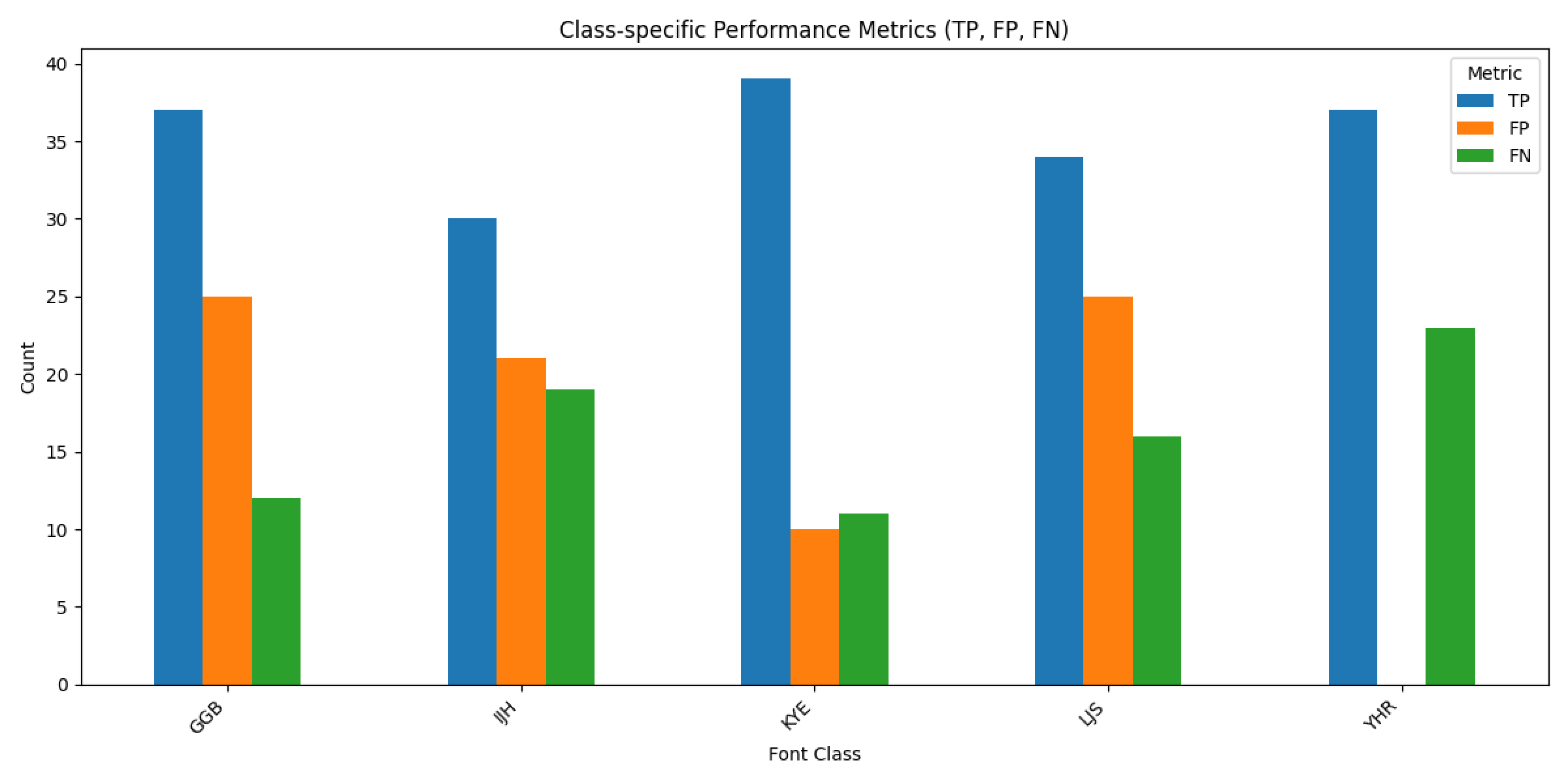
- 그러나 에포크를 150으로 늘리자 오히려 정확도는 81.4%로 근소하게 떨어져 이미 과적합이 진행되었다고 판단함.
![]()
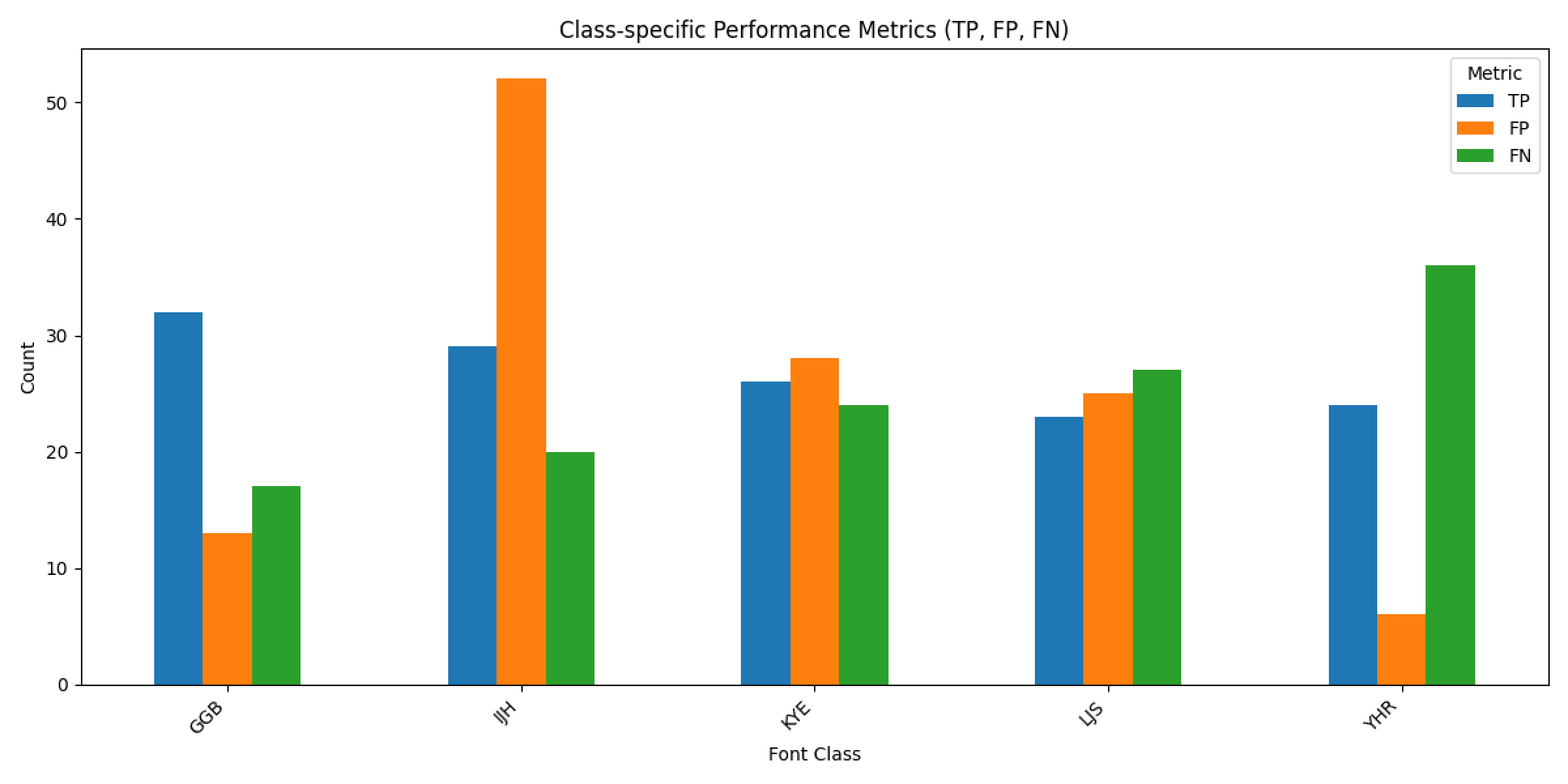
- 데이터를 더 어렵게 만들고 학습을 시키면 과적합이 덜 될까 싶어 엘라스틱 왜곡 증강 데이터셋에 배경색 추가 / HSV 변조 / 색 반전 / 가우시안 블러 / 투시, 회전, 이동 등의 증강을 추가로 적용하고 학습시켰으나 정확도는 76.74%로 떨어짐. 증강이 과했음.
![]()
![]()
- 프로젝트 기한 상의 문제로 더이상의 탐색이나 실험은 진행하지 못했고, 엘라스틱 왜곡을 적용한 모바일넷 모델의 82.56% 정확도가 최고기록으로 마무리됨. (물론 다른 팀원들은 더 성능이 좋은 모델을 만들었기 때문에 최종 모델로 선정되지는 못했음)
![]()
- 모바일넷 폰트 학습(배치 32, 에포크 3) 모델로부터 전이학습, 에포크 30, 배치 80 → 정확도 32.17% → 이정도면 찍기에 가까운 수준
- 프로젝트가 종료된 후 데이터셋에 문제가 있었음을 깨달음
- 팀원 손글씨를 자동으로 크롭할 때 상당량의 이미지가 누락되었음. 원래는 데이터셋이 2배 이상으로 많아야 했으나, 이를 바로 인지하지 못해 프로젝트가 끝날 때까지 적은 데이터셋으로 진행했음. 이번에 배웠으니 다음엔 같은 일 없을 것.



기여도 구분
팀원. 데이터셋을 준비 및 가공하고 증강하였으며, 비록 최종 결과물에는 반영되지 못했지만 다양한 시도를 통해 전이학습과 데이터셋에 대해 탐구했음.
결과 및 성과 (Result)
- 데이터셋의 특성에 맞는 적절한 증강 기법 사용으로 최대 70%에 머물던 모델 정확도를 82.56%까지 향상함
- 데이터의 특성 및 특징에 따라 유사한 부류의 데이터라도 전이학습과 사전학습에 같이 사용할 경우 오히려 성능에 방해가 되는 경우도 있음을 밝혀냄
- 과도한 증강은 오히려 모델이 원활히 학습하는 것을 방해하여 성능 저하를 유발함을 확인함
- 데이터의 부족 혹은 무결성 훼손이 모델의 성능에 미치는 영향을 직접 확인함으로써 이러한 사항을 고려하고 데이터셋을 모델링할 수 있는 인사이트를 얻음