table of contents
QnA
- 제조업은 불량이 고객에게 전달되었을 때의 패널티가 큰 분야니까, false positive에 대한 성능이 false negative보다 우선하는 편인가? 실제로 모델을 만들 때에도 그런 쪽으로 더 신경쓰는지?
- ok 전자를 2종 오류, 후자를 1종 오류라고 부르는데, 보통 2종 오류가 더 치명적이기 때문에 그쪽 성능을 우선시한다
- 반도체 불량 검사를 위해 한 로트에서 서너개를 뽑아 검사했더니 그 중에 불량이 일부 포함되면, 로트를 다 불량처리하나 아님 남은 웨이퍼에 대해 전수조사해서 진짜 불량만 처리하나? 전수조사도 비용이지만 멀쩡한 웨이퍼를 불량 처리하는 것도 비용일 것 같은데, 보통 어떻게 하는지 궁금하다.
- 그것은 운영자의 노하우와 판단에 달려있다. 근데 웨이퍼 한장이 몇천만원은 하다보니 살릴 수 있는 건 살려서 지나가고, 심각한 오류인 경우에도 그 로트를 따로 빼서 사람이 전수조사하고 살릴 수 있는 건 살려서 보낸다. 그리고 불량이 생각보다 많이 나온다. 그렇기 때문에 가벼운 불량이 조금 나오는 정도는 그냥 보낸다.
- 이 불량 검사에서는 모든 불량을 걸러내기보다는 더이상 진행시킬 수 없는 심각한 결함만 걸러내는 것이 더 주요하다.
- 마지막 최종 검사에서는 예외 없이 전수조사하고, 그때 불량인 것은 당연히 출고되지 않는다.
M5. 데이터 연결
데이터 연결이라는 건 data connectivity를 말하는 것이고, 제일 어렵고 가장 선행되어야 할 것. 데이터 수집 말이다.
그리고 그 다음으로 우선하는 것이 데이터 품질임. 이게 좋아야 모델의 품질이 좋게 나온다.
그 다음은 데이터 전처리. 데이터의 제약사항을 어떻게 잘 처리할 것인지?
그 후엔 AI 모델링, 성능 평가, 적용… 뭐 그런 흐름
근데 사람들은 저 모델링부터 적용까지만 생각하고 AI 금방 만드는 줄 안다. 데이터부터 문제인 줄은 잘 모른다.
데이터 수집
- 데이터의 종류
- 구조
- 정형: 구조화 O. 즉시 사용 가능 → 보통 회귀나 분류에 사용됨.
- 반정형: 어느 정도 구조는 있지만 파싱 필요. 보통 속성과 값의 쌍으로 구성됨. 파싱하면 정형 데이터로 만들 수 있음.
- 비정형: 구조가 1도 없는 데이터. → 분류에 사용 가능
- 특성
- 범주: 종류를 나타냄. obj.
- 명목: 순서 없음. → 보통 분류에 사용됨
- 순서: 순서가 있음.
- 수치 → 보통 회귀에 사용됨 (수치 예측)
- 이산
- 연속
- 범주: 종류를 나타냄. obj.
- 구조
- 데이터 수집
- 제조현장데이터(OT데이터, operational technology data): 주로
IIoT나 PLC, CNC를 통해 수집함- 실제 제조 현장의 다양한 설비로부터 수집되는 데이터
- 센서, 전기 에너지, I/O, PLC 등등
- 다양한 설비 및 프로토콜의 불일치, 데이터 수집 장치 미설치 등 어려움이 많음.
- IT 데이터: 제조 어플리케이션으로부터 얻은 데이터.
ETL을 통해 수집함.- ETL: extract-transform-load
- 원본과 별도로 데이터 분석 전용 DB를 사용함. 사유: 실수로 데이터를 건드려서 수정해도 원본은 안전함.
- 제조현장데이터(OT데이터, operational technology data): 주로
산업 사물인터넷
- 산업 사물인터넷
- 산업용 사물인터넷(좀 더 비싸다)
- 물리적 공장과 가상의 공장을 연결하는 매개
- 설비로부터의 데이터 수집이 가장 큰 목적
- 산업 사물인터넷 필요성: 스마트 팩토리 구현을 위한 핵심 기술
- 높은 신뢰성과 강건성 요구됨(비싸다)
- 산업 사물인터넷 기술 구조
- 데이터 생성 → 연결 → 데이터 처리 → 서비스 제공
- 데이터 생성
- 미가공 raw 데이터 수집
- 센서 데이터의 경우 시간과 측정값의 쌍으로된 시계열 데이터로 수집되는 편
- 엔지니어라는 건 문제를 해결하는 사람이다(공학 첨부됨). 생성된 데이터에서 문제점/원인을 찾고, 그로부터 해결 방법을 고안하는 것이 님들이 할 일이다.
- 근데 아직 AI가 원인 분석은 잘 못해요. 그건 아직도 사람의 직관에 의존한다. 근데 또 그건 아무나 되는 건 아니고 꾸준한 지식 축적을 통해 나오는 인사이트임.
- 연결
- 연결 || 통신 || 네트워크
- 센서 디바이스에서 생성된 데이터를 서버로 전송, 혹은 제어 요소를 서버에서 디바이스로 전송
- 디바이스 네트워크: 비교적 근거리. 와이파이, 블루투스, NFC 등
- 백본 네트워크: 5G, LTE, CDMA, GSM 등 비교적 장거리 네트워크.
- 데이터 처리
- 데이터로부터 유의미한 정보 창출
- 그러기 위한 가공 및 분석
- 데이터 애널리틱스, 클컴, DB, 플랫폼, 미들웨어 등
- 서비스 제공
- 가시화/동작 및 사용자 인터페이스 영역
- 데이터를 처리한 결과가 실제 서비스로 가시화 및 동작되는 어플리케이션
덤
면접 때 가서 인공지능은 데이터 커넥티비티가 중요하다고 말해보세요. 인공지능만 공부한 사람들보다는 조금 더 차별화되어 보일 수 있지 않겠습니까?
만약 면접관이 맞습니다 그럼 어떻게 해결하죠? 라고 물어보면 잘 대답해보세요. 해결 방법은 여러 가지 있어요. 대표적으로 표준입니다. 산업 표준 쓰시면 돼요.
M6. 인공지능
인공지능 모르지 않죠? 근데 알아도 다시 들으세요
- 인공지능 예시
- 공장 현황 대시보드
- 품질 판별(양/불량)
- 시계열 예측, 센서 데이터 예측
- 인공지능 기법
- 아주 예전 인공지능
- 전문가 시스템: 인간의 지식을 기계에 반영
- 규칙 기반 시스템: 주어진 규칙을 기계에 반영. if 산더미.
- 지금 인공지능
- 지도학습: 모든 데이터에 레이블 포함됨.
- 반지도학습: 레이블을 쓰다 말았음.
- 비지도학습: 레이블이 없음. 알아서 분류함.
- 강화학습: 에이전트가 환경 내에서 보상을 기반으로 학습
- 전이학습: 남의 학습 데이터를 물려받아 이어서 튜닝
- 물리정보 기반(physics informed-) 기계학습: 물리적인 지식을 기계학습에 적용 또는 결과 해석. 기계학습의 결과를 물리 정보 및 지식을 기반으로 타당성을 검토함
- 설명가능 인공지능(XAI): 인공지능의 판단 이유를 사람이 이해할 수 있는 방식으로 제공함. 현업에서는 ‘설명 가능함’이라는 속성 때문에 정확도를 좀 손해봐도 설명할 수 있는 인공지능을 사용하기도 한다. 누구나 100% AI를 원하긴 하지만, 그게 안된다는 걸 알고 있고, 꼭 복잡한 모델을 써야만 하는 건 아님.
- 학습의 깊이(대략 딥하냐 아니냐 정도의 차이)
- 기계학습: (아마도 딥러닝이 포함되지 않았을 것) 기계가 데이터를 통해 스스로 학습하여 예측이나 판단
- 심층학습: 깊은 인공신경망 알고리즘을 활용한 기계학습
- 심층학습은 지도/반지도/강화 등과 같이 알고리즘으로 구분된다기보다는 학습 기법에 가깝다고 봄. 지도 학습을 할 때에도 심층학습을 할 수도 있고 아닐 수도 있고, 강화학습도 마찬가지.
- 아주 예전 인공지능
- 인공지능 모델
- 지도학습: X와 Y가 정의되었고, F가 생성됨
- 비지도학습: X와 Y가 구분되지 않고 제공되었고, 그 구분과 F가 생성됨
- random error term인 $\epsilon$이 작을수록 좋은 모델
- 인공지능 모델 종류
- 목적에 따라
- 설명적 모델: 지금 또는 과거에 무슨 일이 있었는지에 대한 설명을 제공. 대표적으로 대시보드 형태로 가시화됨. 가장 일반적이고 쉽고 비용도 낮음.
- 진단적 모델: 왜 이런 일이 발생했는지에 대한 답을 알려주기 위한 모델. 설비 데이터에 갑자기 이상치가 발생한 경우 이상을 감지하고, 상세 분석, 인과 분석을 통해 이유를 밝힘.
- SPC(statistical process control, 통계적 공정 관리): 어떤 센서 값의 상한과 하한을 정해두고, 그 범위 안의 값은 정상으로 간주함
- 가성알람: 설비에 진짜 문제가 있는 게 아닌데 그냥 알람이 울림. 보통 현장에서는 이게 생각보다 되게 많이 울려서 작업자가 시끄럽다고 꺼버리는 경우도 있다고 한다.
- FDC 문제: fault detectional calssification. 불량 감지 문제.
- 예측적 모델: 내일 오후 5시에 호떡집에서 불이 날 거예요. 수요가 가장 많은 영역. 불확실성이 큰 영역에서 더 나은 의사 결정을 내리도록 돕고 실패 확률을 줄임.
- 처방적 모델: 무엇을 하면 될지 알려주는 최적화 모델. 제약 속에서 성능의 최대화/최소화/망목화가 이루어지도록 의사결정 변수 결정 및 제어. 제일 어려움.
- 예시: 수율 최적화
y는 수율(%)이고, 각 x는 설비 파라미터라고 할 때, 수율을 최대화하고 싶다. (수율은 전체 생산품 중 합격품의 비율). 그 식은 아래와 같이 표현할 수 있다.
$y = F(x_1, x_2)+\epsilon \rightarrow \underset{X}{arg}(_{max}y), \ X = {x_1, x_2}$
이때 제약사항은 다음과 같다- $X_1^L \leq X_1 \leq X_1^U$
- $X_2^L \leq X_2 \leq X_2^U$
- $Time \ Fn \sim y$
- $Cost \ Fn \sim y$ 이런 상황에서 최적의 X를 찾아내는 걸 하라는 말임. 최적 설비 파라미터는 $X^\star = { x_1^\star, x_2^\star }$로 나타낸다.
- 예시: 수율 최적화
- 목적에 따라
- CRISP-DM
- 전문가가 사용하는 인공지능 모델 개발 및 적용에 대한 표준적인 방법론
- 인공지능 모델 개발 및 적용에 필요한 정의된 절차 및 산출물을 제공하는 안내서
- 프로세스: 문제 정의 > 데이터 수집 > 데이터 전처리 > 모델링 > 평가 > 적용
- 역할 분담
- 현업 부서: 문제 정의, 공정 모델링, 물리적 분석
- 분석 부서: 데이터 수집, 데이터 전처리, 모델링
- 이후: 평가, 적용, 자동화
- 문제 정의
- 달성하고자 하는 것을 이해하고 인공지능의 목표를 결정하는 과정
- 문제 목표 설정, 성공 기준 수립
- 현재 상황 평가: 자원 목록, 요구사항, 가정 및 제약, 비용과 효과
- 데이터 마이닝 목표 결정: AI의 목표를 결정하는 것.
- ‘전체적인 상황에 대한 문제 정의’와 ‘AI가 해결해야 할 문제 정의’는 다르다. AI가 모든 문제를 다 풀어주는 게 아니다. 중요한 의사결정을 담당하긴 할테지만 AI 모델이 빌드되는 것 이외의 나머지 모든 부분도 문제 정의에 포함된다.
- 데이터 수집
- 원본 데이터 수집
- 데이터 설명: 이게 뭔 데이터인지 알려줘야 분석을 하지. 최대한 친절하게 잘 정리하고 문서화해서 분석 부서로 보내야 말이 통한다.
- 데이터 탐색
- 데이터 품질 검사
- 데이터 설명
- 데이터셋: 통상적으로 데이터 소스는 여러 개가 섞여서 온다. 그 형태도 모두 다르다. 전처리를 통해 하나의 데이터셋(엑셀, csv 등 정형 데이터)으로 통합해줘야 한다.
- 데이터 탐색
- 탐색적 데이터 분석(exploratory data analysis, EDA)
- 데이터를 이해하고 특징을 파악하기 위해 이것저것 해보는 과정
- 평균내기, 분포 그래프 그려보기 등 기초 통계 및 시각화 위주.
- 여기서 데이터의 경향이나 이상치 등을 찾게 된다.
- 근데 보통 아는 전형적이고 이론적인 그래프? 잘 안나온다. 막 맥도날드 같은 그래프 나오고 그럼. → 이럴 때 찾아야 할 것: 그 봉우리들을 나누는 기준점이 분명 있을 것이다. 이 데이터를 대변할 수 있는 기준 정보가 있다. ⇒ 데이터를 더 잘게 쪼개서 보면 패턴이 보인다. 이걸 모델의 입자성이라고 부른다. 데이터 전체에 집착하지 않기.
→ 이런 문제가 생기는 이유는 데이터에 포함되지 않은 맥락에 그 원인이 있는 경우가 있기 때문. 도메인 지식이 이런 데 쓰임.
- 탐색적 데이터 분석(exploratory data analysis, EDA)
- 데이터 전처리
- 상당히 오래걸리고 까다롭고 아직까지도 사람 손을 많이 타는 영역이다. 데이터 이해와 전처리 과정이 전체 과정에서 50-70% 정도 차지한다.
- 여기서 좋은 데이터를 만들어야 모델도 잘 나온다.
- 데이터 선택(이유 필요), 정제, 구성, 통합, 형식화
- 데이터 선택
- 존재하는 모든 피처를 모델에 넣는다고 성능이 잘 나오는 게 아니다. 꼭 필요한 피처만 잘 골라서 넣어야 한다.
- 차원 수가 너무 커지면 모델의 성능이 떨어지게 된다. 차원의 저주라고 부른다.
- 선택 방법은 몇 가지 있다
- 각각 상관성을 구해서 상관계수가 높은 것만 고르기
- 다 넣고 하나씩 빼면서 모델 성능 변화 관찰하기
- 데이터 정제
- 중복, 비관련, 비유효, 잡음, 이상치, 불완전, 결측 등 처리할 문제가 차고 넘친다
- 잡을 수 있으면 잡아주되, 그것도 데이터를 이해하고 해야 한다
- 이상치도 좀 골때리는 게 이게 진짜 이상치인지, 가능한 일인지는 이 데이터에 대해 잘 알아야 판단할 수 있다.
- 데이터 통합
- 기준 정보를 활용해 데이터를 join하거나, 합산(aggregation)하기도 한다
- 합산의 경우 기초 통계를 활용할 수 있음. 평균 분산 중앙값 최솟값 최댓값 합계 등. 제조 데이터는 양이 정말 많기 때문에 그걸 다 쓸 수가 없다. 이것은 데이터를 요약하는 것임.
- 데이터 형식화
- 데이터의 의미는 그대로 두고 형식만 바꾸는 과정
- 파일 확장자를 바꾸거나, 단위를 바꾸거나(야드파운드놈들), 원 핫 인코딩과 같이 형태를 변형하거나 스케일을 조정하기도 함.
- 컴퓨터는 문자보다 숫자 처리가 빠르다.
- 원래 데이터 그대로 학습하는 거 안돼요 정규화 하고 쓰세요: 설비 파라미터는 상한과 하한이 보통 알려져 있으니, 그걸 기준으로 스케일링하면 된다. 물론 최종 결과값은 역변환을 해줘야한다.
- 모델링
- 모델링 기법 선택, 테스트 설계 생성, 모델 생성, 모델 평가
- 통계학 기반 기법과 기계 학습 기반 기법 활용
- 테스트 설계 생성
- 데이터셋을 훈련, 검증, 테스트로 분리하는 것. 비율은 때마다 다르다. 보통 자주 쓰는 비율은 있긴 하지만 국룰은 아님.
- 층화 샘플링: 데이터셋의 특성이 각 부분 데이터셋에 그대로 전해지도록 샘플링하는 방법. 보통 파이썬에서 학습셋을 split 할때 알아서 셔플해서 나눠주는 그런 거 말하는 거임.
- 훈련셋: 모델이 보고 배우는 데이터. 모델이 복잡할수록 성능은 향상되긴 하나 과적합 위험 증가
- 검증셋: 모델이 학습 과정에서 채점하는 데이터(학습오차 검증). 과적합 방지에 사용됨.
- 테스트셋: 모델을 채점하는 데이터. 모델의 예측 오차를 검증함. 전체 데이터셋으로부터 분리하긴 했지만, 별개의 데이터라고 간주하고 사용한다. 실제 적용했다 치고 확인하는 오차이기 때문에 예측 오차가 학습 오차보다 우선한다. 예측 오차가 작을수록 좋은 모델.
- 모델링: 기계학습 기반 모델링
- 기계가 데이터로부터 피처를 파악 및 추출하여 새로운 데이터의 특징을 분석하고 예측함.
- 다만 이 예측은 어디까지나 확률이기 때문에 항상 부정확 문제가 있다.
- 선택이 애매한 그레이존이 항상 존재한다. 해결 방법은 알고리즘을 더 강화하는 것일 수도 있고, 따로 분류해 사람에게 판별을 맡기는 것도 있다. 그것은 케바케.
- 데이터는 다다익선이긴 한데, 결국엔 한계가 오긴 한다. 이 세상엔 데이터로 표현이 안되는 피처가 있는 것임.
- 모델링: 모델 생성
- 지도 학습: 회귀(수치 출력)와 분류(범주형 출력)
- 비지도학습: 클러스터링, 이상 탐지, 차원 축소. 지도 학습은 성능 평가가 가능한 반면 비지도학습은 그런 방식의 성능 평가가 어렵다. 간접적인 판별 정도만 가능하다는 이슈가 있음. 그런데 이제 다음 이슈는 최근 제조업에서 레이블 데이터가 없어서 자의 반 타의 반으로 비지도학습으로 넘어가는 추세임. 만약 있다고 해도 그런 건 분리해서 저장되므로 데이터 소스가 분리되어 있다.
- 모델링: 모델 평가
- MSE(평균 제곱 오차), RMSE(평균 제곱근 오차), MAE(평균 절대 오차), MAPE(평균 절대 비율 오차), 결정 계수(R²)
- 결정 계수는 약간 결이 다르다. 모델의 설명력을 보여줌.
- 모델링: 분류 평가 척도
- 적중률: 정답 비율
- 오류율: 오답 비율
- 정밀도
- 재현율
- F1-score
- FP(2종 오류)와 FN(1종 오류): 제조업에서는 불량 출고가 아주 치명적이기 때문에 FP를 줄이는 게 중요하다.
- 모델링: 모델 평가 예시
- 모든 평가 척도에서 우수한 모델이 있다면 그걸 쓰면 되겠지. 그게 안되면 trade-off를 잘 고민해봐야 함. 최종 목표의 성공 기준, 도메인 지식, 엔지니어의 경험 등을 기준으로 고름.
- 평가
- AI 모델 말고, 도메인/현업 입장에서 이걸 진짜 적용해도 될지 말지 평가하기
- 평가 요소: 비용, 오류 최소화(신뢰도), 시간, 지식 관리 등
- 적용
- 시스템에 진짜 적용함
- 어떻게 적용할건지(전개 계획), 모니터링 및 유지 관리 계획, 최종 보고서 생성, 프로젝트 검토
- 여기까지가 개발임. 이 이후는 시스템 운영의 입장임.
- 스마트 팩토리에서의 인공지능
- 인공지능은 어디까지나 도구이자 기술. 사람이 할 수 없는 일을 대신 해줄 뿐 사람을 배제할 수 있는 게 아님.
- 100%는 없음. 오차 보완 필요.
- 정확도를 계속 높여서 오류를 그나마 줄이거나
- 사람이 검수하기
- 설명 가능해야 함. 이해할 수 있어야 함. 모델이 잘못한 건 사람이 책임진다.
- 물리적 분석이 병행되어야 함. 인공지능의 결과가 물리적으로 말이 되는지 검증해야 함.
- 끝없는 유지보수. 시간이 지나거나 조건이 변하면 잘 맞던 모델도 맞지 않게 될 수 있음. 성능이 떨어지면 데이터를 다시 수집해서 다시 학습시켜야 할 수 있다.
- 데이터 확보 및 수집은 어려움. 강건한 데이터 수집 체계 필요.
- 교수님의 팁
- 한 직장에서 적어도 3년은 채우고 나가세요. 너무 자주 옮기면 지속성에 대한 신뢰가 떨어진다. 3년마다 권태기가 3번 오는데, 아무튼 3년은 채워봐라.
M7. 제조 인공지능 사례
- 자료 영상 보는 동안 뭔가 찾았음. 자율주행 자동차 관련 현대엔지비 무료 강의 모음
항공기 엔진 예측 유지보수
- 항공기 엔진 > 수치 데이터 > 회귀(수치 예측) > 잔여유효수명(RUL)
- 데이터셋: CMAPSS 터보팬 엔진 데이터
- 미국 나사에서 제공하며, RUL 예측 연구에서 많이 활용함
- 분할도 미리 다 해줬음
- 실제 잔여유효수명도 제공함
- 굳이 강의자료에 있는 거 다 옮겨적을 것까진 아닌 것 같고 강의자료 읽으세요
- 설비 시스템 유지보수 관리: 유지보수 정책은 다양함
- 사후보전(CM): 소 잃고 외양간 고치기. 라고는 했지만 상황이 여의치 않아 이렇게 유지되는 사업장도 있음.
- 예방 보전(PM): 정기점검. 정해진 기준대로 일정을 정해 실시. 가장 많이 쓰는 방법.
- 상태 기반 보전(CBM): 시스템 상태 임계치를 설정하고 모니터링 측정값을 근거로 실시
- 예측 보전(PdM): 언제쯤 고장이 날지 예측해보고 보수. 자연유효수명 예측을 기반으로 함. 센서 데이터를 이용한 스마트 팩토리에서 활용하고 있음.
- 잔여유효수명(remaining useful life) 예측
- 설비의 현재 상태를 기준으로 언제 고장날지 나타냄
용접공정에 대한 품질분류
- 용접 공정
- 금속을 순간적인 고에너지로 녹였다가 굳혀서 두 금속을 접합하는 것
- 요즘은 용접을 이용한 적층식 3D 프린팅 기술도 있다고 함
- 다만 소재가 녹았다 붙는 공정의 특성 상 불량이 다양하고 많이 발생함
- 용접 불량 종류
- 외관 불량: 겉으로 보면 문제가 보임 → 카메라 달면 됨
- 내관 불량: 안쪽에 불량이 생김 → 비파괴검사(엑스레이, CT, MRI 등 의학기술)를 활용해 안쪽을 투시해서 보면 됨. 물론 비싸고 시간이 걸림… 보통은 검사 장비가 없어서 외관 불량만 검사한다고 함
- 녹았다 붙는 과정에서 안에 기체가 들어감 → 여기서부터 크랙이 발생함. 응력이 집중됨. 추후 불량이 될 것.
- 용접 파라미터
- 1D 데이터 → 시계열 데이터, 95% 정도 성능
- 이동 속도: 토치가 이동하는 속도
- 와이어 공급 속도: 와이어가 이동하는 속도
- 전류: 토치에 전달되는 전류의 크기
- 2D 데이터 → 이미지 데이터, 98% 정도 성능
- 용접하는 과정 영상
- 완성된 접합부의 사진
- 1D 데이터 → 시계열 데이터, 95% 정도 성능
- 시계열 데이터를 다루는 방법 중 하나: 윈도우 슬라이딩
- 보통 AI의 성능을 말할 때는 “최대” 성능을 말합니다. 최소 성능 말하면 기분이 안좋잖아요. 99.9%에 속지 마세요~
- 보통 제조를 하면 당연히 정상이 대부분이고 불량은 아주 적다. 하지만 이 데이터로 AI를 만들어야한다. 데이터의 불균형 어떻게 하겠는가?
- 오버샘플링: 불량품 데이터를 증강해서 양품 데이터만큼 만듦
- 언더샘플링: 양품 데이터를 불량품 데이터만큼 줄임
보통 오버샘플링을 쓴다고 함.
- 제조업에서는 CNN의 성능이 이미 어느 정도 인정되었으니 그거 쓰시면 돼요.
- 앙상블 모델 → 99% 나왔다고 함
- 서로 다른 여러 개의 모델을 결합해 판단하는 것
- 이번 사례의 경우 1D 데이터 모델과 2D 데이터 모델 각각 학습 후 판단하고, 그 결과를 다시 분류기가 학습하고 분류하여 최종 결정을 진행했음.
M8. 제조 데이터 분석 과제 - 산제 전처리 공정
미리 전달받은 첨부 파일 기반 실습 (링크에 첨부된 것을 기반으로 약간 더 정리된 것을 받음)
- 아연 도금: 부식에 강해짐
- 산제 전처리 공정: 아연 도금을 하기 전에 원래 있던 녹을 제거하고 씻어내는 등 아연 도금을 수행하기 직전까지의 전처리 과정
- process rate: 전체 제품군 대비 합격품의 비율(수율)
- 산제 전처리 공정의 문제점
- 제품의 색상 불량, 흑색 불량 등이 발생할 수 있음
- 공정에 사용할수록 용액의 농도가 변하므로 점차 산처리 품질 저하, 도금 품질 불량 발생
- 이 공정의 전처리 공정 시간을 가능한 줄이는 것이 목표
- 현재 다양한 데이터를 구하고 있으나, 활용을 못하는 상황
- 하지만 이 데이터를 품질 예측에 사용할 수 있을 것으로 판단함
⇒ $f(pH, 온도)+\epsilon$을 구하라
- 조건
- 독립변수(x)는 용액의 pH 농도와 온도, 종속변수(y)는 수율이다.
- pH 농도의 최소 기준은 정해져 있다
- 산성 반응 시 반응열이 존재하므로 온도는 맘대로 조절할 수 없음
- 공정 시간은 조절 가능
- 공정 시간이 길어지면 비용 문제와 품질 문제가 발생
- 공정 시간이 짧아지면 산제 전처리가 깔끔하게 완료되지 않아 품질 저하 문제 발생
- 데이터 속성
- Index: 인덱스(int)
- Date: 날짜를 정수로 나타냄(int)
- LoT: 로트 번호(int)
- DateTime: 초 단위 날짜(datetime)
- pH: 전처리 설비 내 공정 pH 농도 측정값(float)
- Temperature: 전처리 설비 내 공정 온도 측정값(float64)
- ProcessRate: 전처리 완료된 결과물의 수율(float64)
- pH_Standard: 정규화된 pH 값(float64)
- Temperature_Standard: 정규화된 온도 값(float64)
- ProcessRate_Standard: 정규화된 수율 값(float64)
탐색적 데이터 분석
- 데이터 기본 정보 확인
전체 데이터
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
<class 'pandas.core.frame.DataFrame'> RangeIndex: 50094 entries, 0 to 50093 Data columns (total 10 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Index 50094 non-null int64 1 Date 50094 non-null int64 2 LoT 50094 non-null int64 3 DateTime 50094 non-null datetime64[ns] 4 pH 50094 non-null float64 5 Temperature 50094 non-null float64 6 ProcessRate 50094 non-null float64 7 pH_Standard 50094 non-null float64 8 Temperature_Standard 50094 non-null float64 9 ProcessRate_Standard 50094 non-null float64 dtypes: datetime64[ns](1), float64(6), int64(3) memory usage: 3.8 MB
lot별 평균 데이터
1 2 3 4 5 6 7 8 9 10 11 12
<class 'pandas.core.frame.DataFrame'> RangeIndex: 726 entries, 0 to 725 Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Date 726 non-null int64 1 LoT 726 non-null int64 2 Average_pH 726 non-null float64 3 Average_Temperature 726 non-null float64 4 ProcessRate 726 non-null float64 dtypes: float64(3), int64(2) memory usage: 28.5 KB
data.describe()
Index Date LoT DateTime pH Temperature ProcessRate pH_Standard Temperature_Standard ProcessRate_Standard count 50094 50094 50094 50094 50094 50094 50094 50094 50094 50094 mean 25047.5 44470.66667 11.5 2021-10-02 02:08:09 2.006488003 49.87612688 96.06422865 -1.66751E-14 -4.40186E-14 1.92268E-12 min 1 44445 1 2021-09-06 09:01:18 1.01 38.02 80.78 -1.806220477 -8.812857479 -4.760521432 25% 12524.25 44455 6 2021-09-16 09:34:29 1.56 49.28 96.17 -0.809298026 -0.443111085 0.032944206 50% 25047.5 44470 11.5 2021-10-01 10:07:49 2 49.97 96.635 -0.011760064 0.06977746 0.177776014 75% 37570.75 44484 17 2021-10-15 10:41:50 2.44 50.63 97.26 0.785777897 0.560366502 0.372442422 max 50094 44496 22 2021-10-27 11:15:01 3.99 54.19 98.45 3.595286624 3.206574065 0.743087264 std 14461.03653 16.06945478 6.344352095 0.551697877 1.345321527 3.2106207 1 1 1 확인된 것
- 결측값은 없음
- pH는 대략 1부터 4 미만까지
- 온도는 대충 38도부터 54도까지
- 수율은 80~98 정도
- 그래프 아무거나 그려보기
- pH와 온도의 조합별 수율 확인하기
![]()
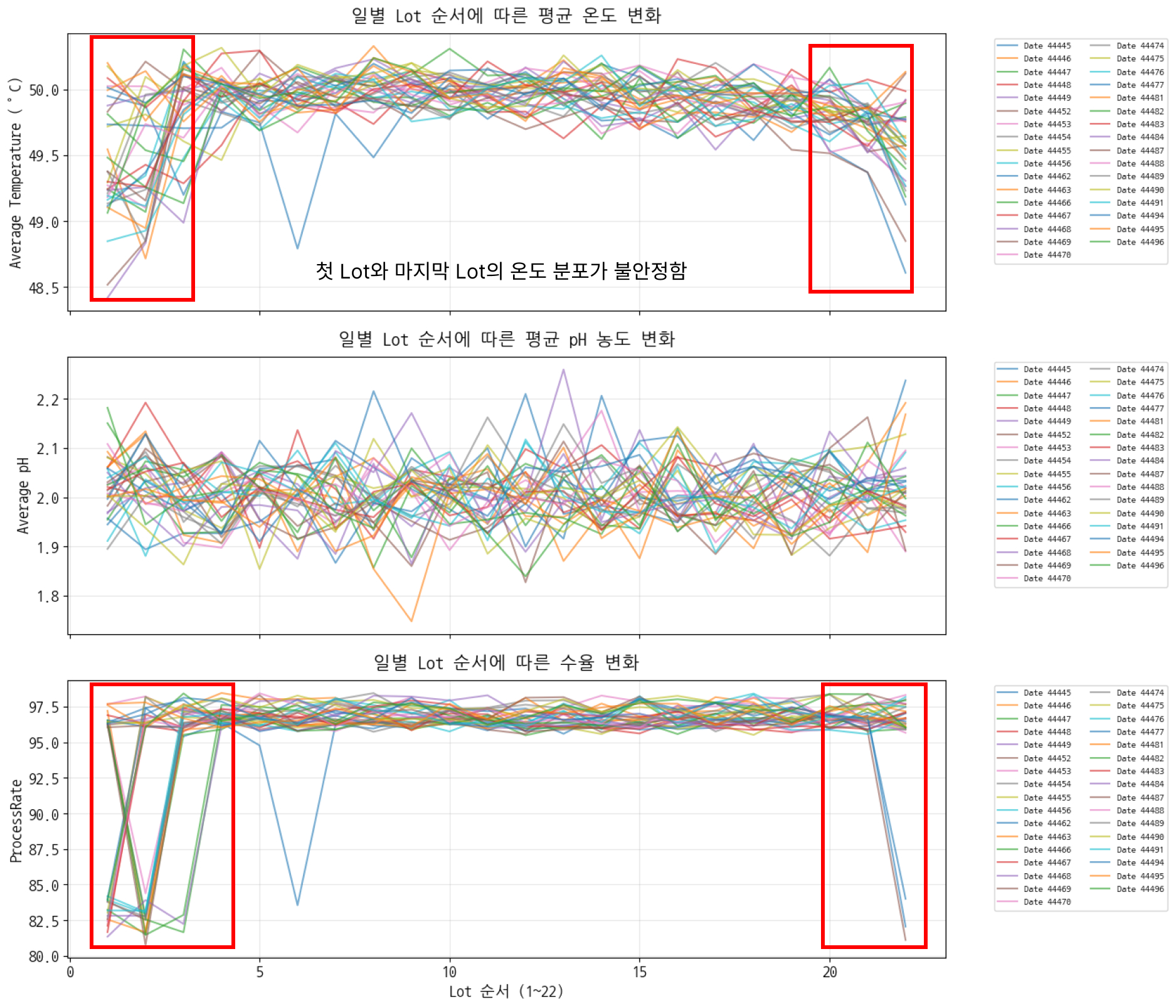
pH(x축)는 전체 범위에 걸쳐 수율이 괜찮은 반면 온도(y축)는 위와 아래의 수율에 차이가 있다 ⇒ 온도가 문제일 수도 있다 - 일일 lot별 변화 그래프
![]()
⇒ 온도가 수율에 더 영향을 주고 있다
→ 온도는 산성 용액의 반응으로 발생하는 반응열에 의해 정해지며,
일반적으로 온도가 높을 경우 화학 반응이 촉진됨
→ 처음과 끝에는 대체로 온도가 낮은 편
→ 처음과 끝에는 화학 반응이 원활하지 않았다
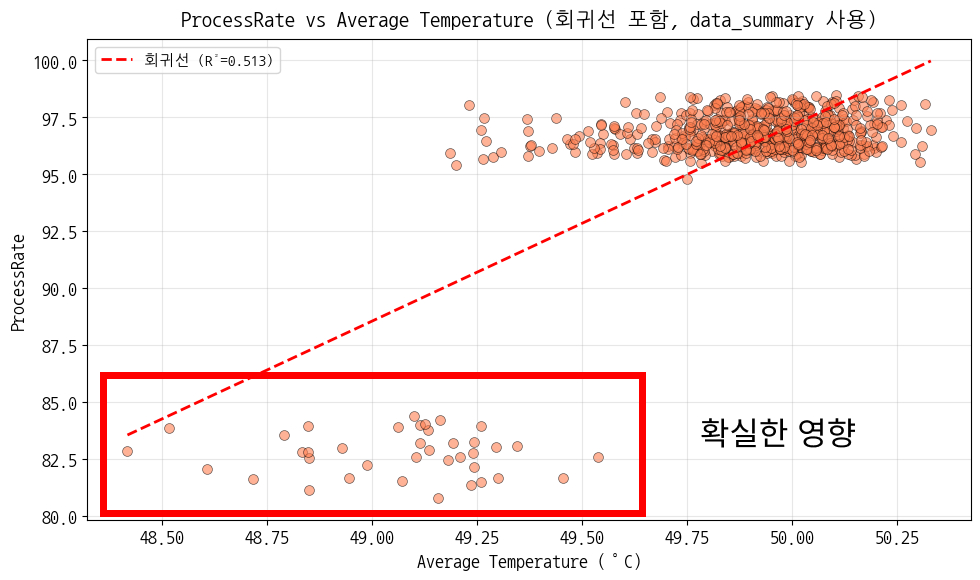
→ 어떻게 하면 시작부터 반응을 원활하게 하고, 끝까지 원활하게 할 것인가? - 수율과 온도의 관계 좀 더 확인하기
![]()
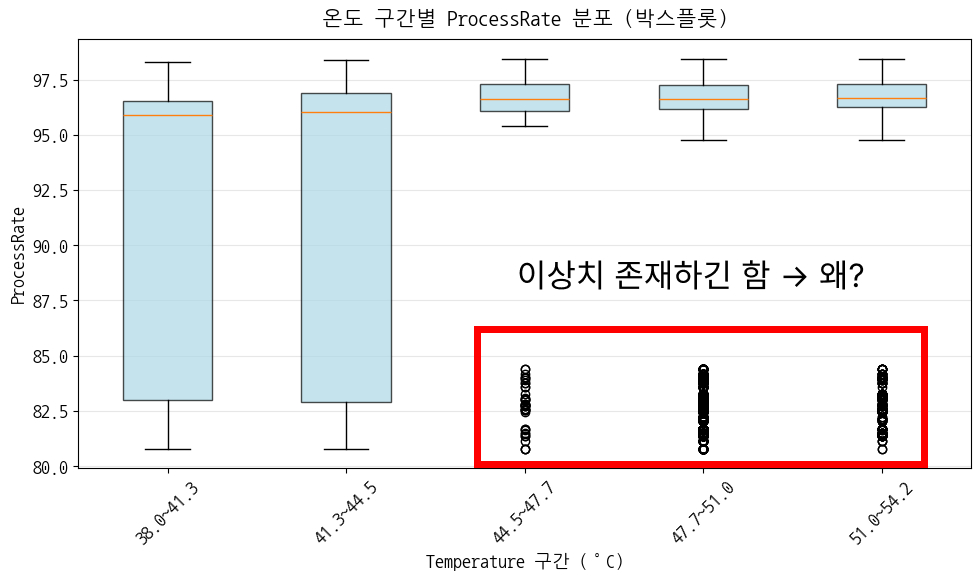
일일 평균 데이터로 온도별 수율 그래프를 보면 확실히 온도가 낮을 때 수율도 낮다
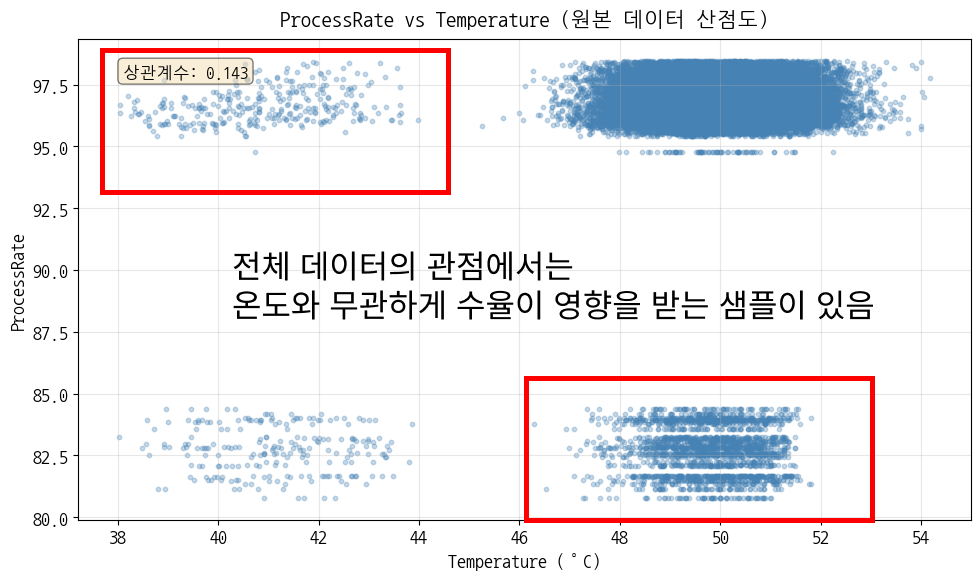
![]() 다만 평균이 아닌 전체 데이터로 똑같이 그려보면 ‘온도가 낮으면 수율이 낮을 것이다’에 해당하지 않는 샘플도 꽤 있음
다만 평균이 아닌 전체 데이터로 똑같이 그려보면 ‘온도가 낮으면 수율이 낮을 것이다’에 해당하지 않는 샘플도 꽤 있음
![]()
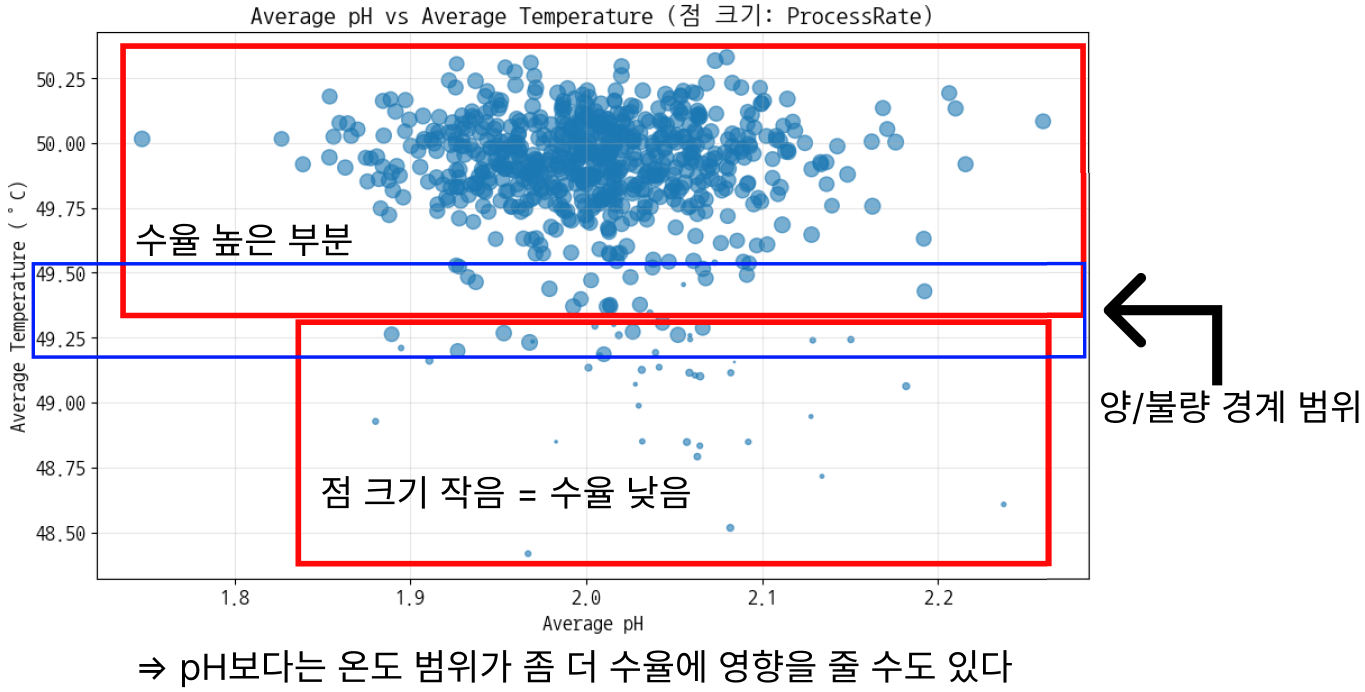
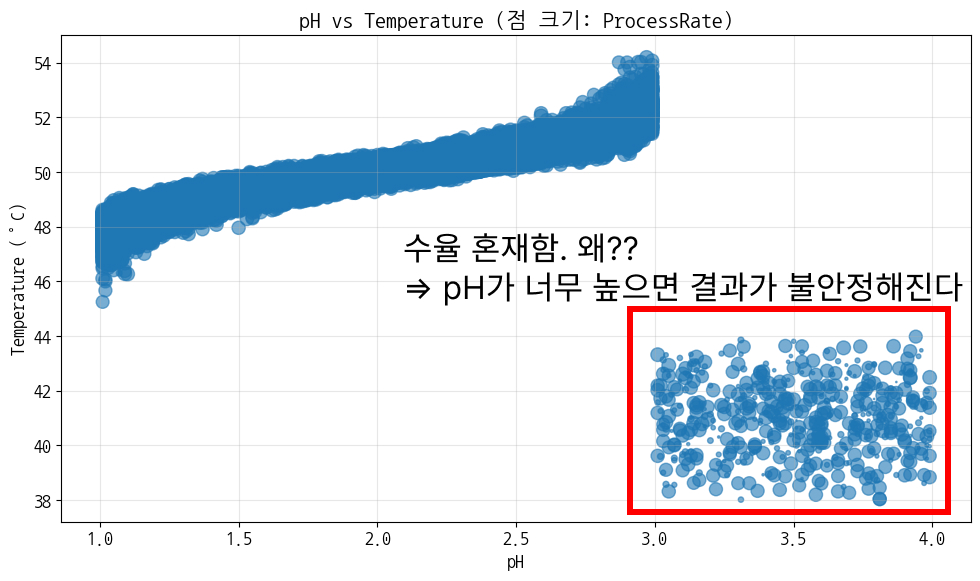
다시 봐도 이상치가 있음 → 이건 pH가 뭔가 했다. 이전엔 일일 평균 데이터로 온도-pH-수율 그래프를 그렸지만 거기선 보이지 않았기 때문에 전체 데이터로 다시 그려볼 필요가 있다. - 전체 데이터로 온도-pH-수율 그래프 다시 그리기 (온도와 pH가 각각 축이고 수율이 점 크기)
![]()
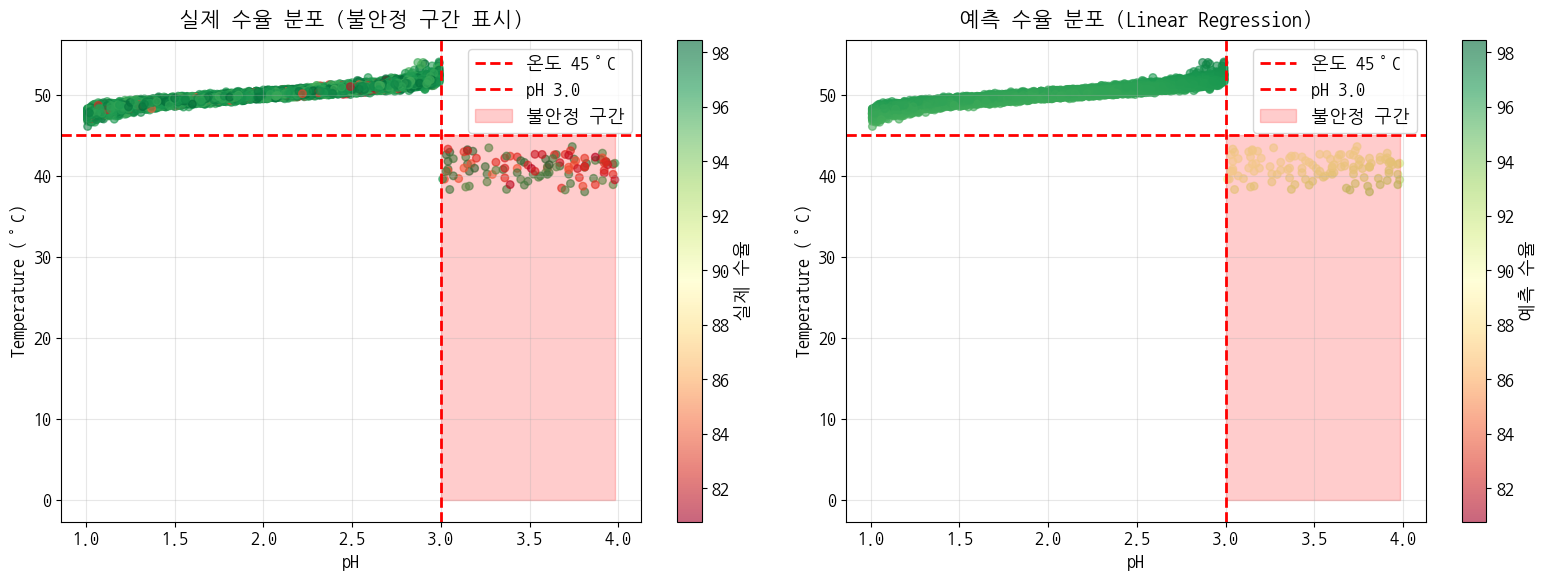
다시 보니까 pH와 온도의 관계는 명확한데, pH가 3.0을 넘어가는 순간 분포가 달라짐 - 결론
- pH 정상(3.0 이하), 온도 낮음(45 미만) → 수율 하락
- pH 너무 높음(3.0 이상) → 수율 불안정
⇒ 두 인사이트는 pH 3.0 이상, 온도 45 미만이라는 공통적인 특성으로 정리됨
- pH와 온도의 조합별 수율 확인하기
모델 만들기
미리 요약하자면
데이터 분석에서 얻은 인사이트를 기반으로 추가 속성을 생성하여 모델을 만들자! → 방향은 정답
근데 데이터를 정규화하지 않아서 모델이 이상하게 나왔었음 데이터를 정규화해야만 하는 이유: 모든 속성의 영향력을 비슷하게 만들기 위해. pH의 경우 1~4 범위인데 반해 온도는 38~50 정도의 범위였기 때문에 변수로 사용될 경우 온도의 영향력이 압도적이게 된다. 이걸 모두 평균이 0, 분산이 1이 되도록 정규화한 후에 사용해야 영향력이 비슷해지고, 중요한 속성이 제몫을 할 수 있게 되는 것.
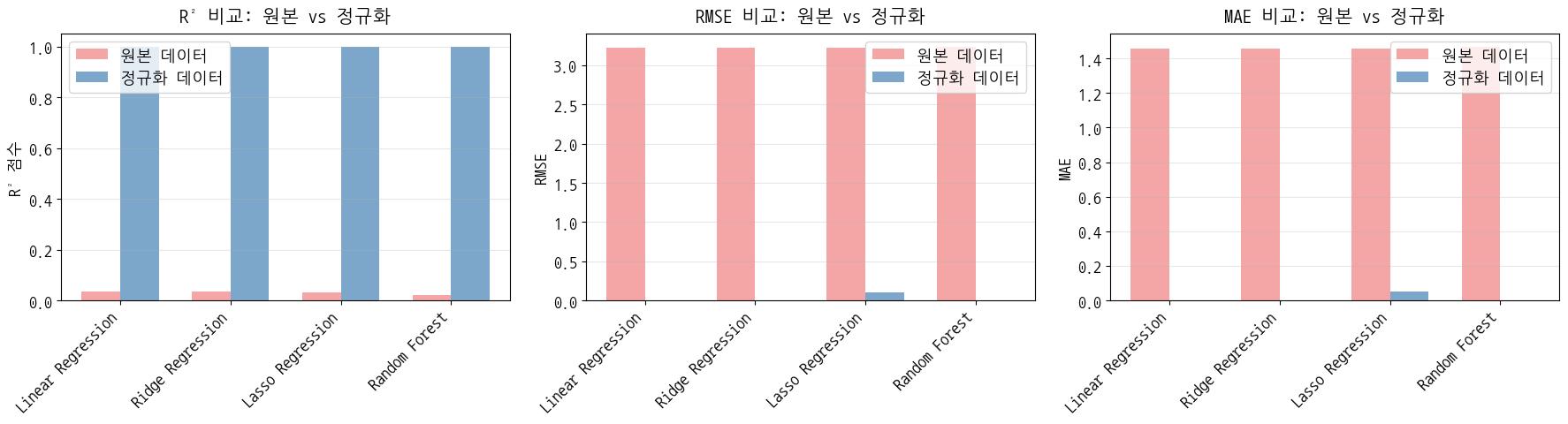
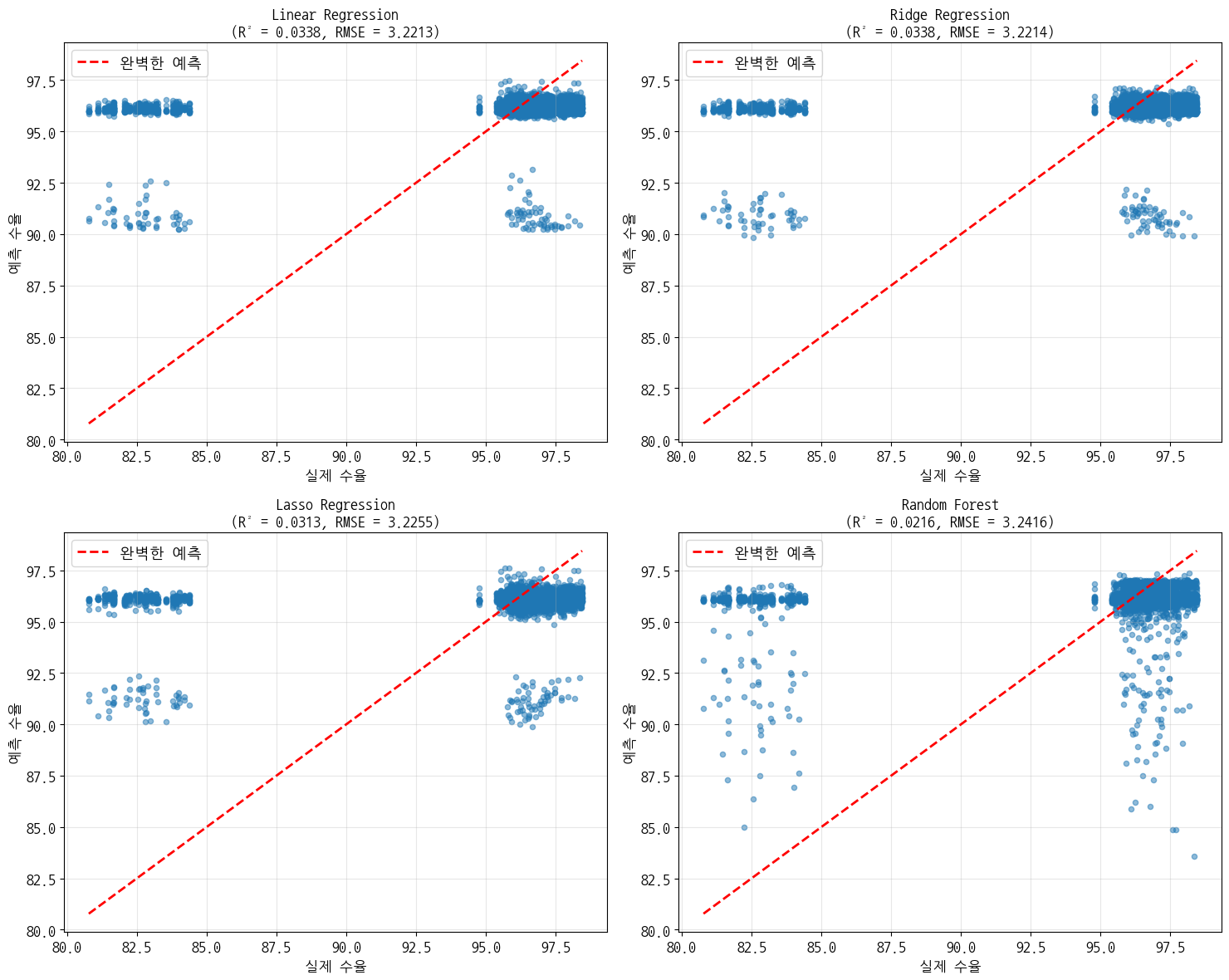
- 원본 데이터로 추가 속성 만들어서 모델 빌드 → R² 값이 0.03 정도 나옴
- 정규화 데이터로 추가 속성 만들어서 모델 빌드 → R² 값이 1에 가깝게 나옴
비정규화 모델
- 사용한 기본 제공 속성
- lot
- pH
- Temperature
- ProcessRate
- 새로 만든 속성
- unstable_condition: pH 3.0 이상, 온도 45 미만 조건
- pH 높음: 3.0 이상
- 온도 낮음: 45 미만
- 상호작용 특성: pH 값과 온도 값의 곱
- pH와 온도 각각의 제곱 값
- 수율 불안정 구간과의 거리 값:
pH - 3.0,온도 - 45
- 데이터 준비
- 학습 데이터 크기: (40075, 10)
- 테스트 데이터 크기: (10019, 10)
- 특성 목록:
['pH', 'Temperature', 'unstable_condition', 'ph_high', 'temp_low', 'ph_temp_interaction', 'ph_squared', 'temp_squared', 'ph_distance_from_3', 'temp_distance_from_45']
- 모델 학습 및 평가
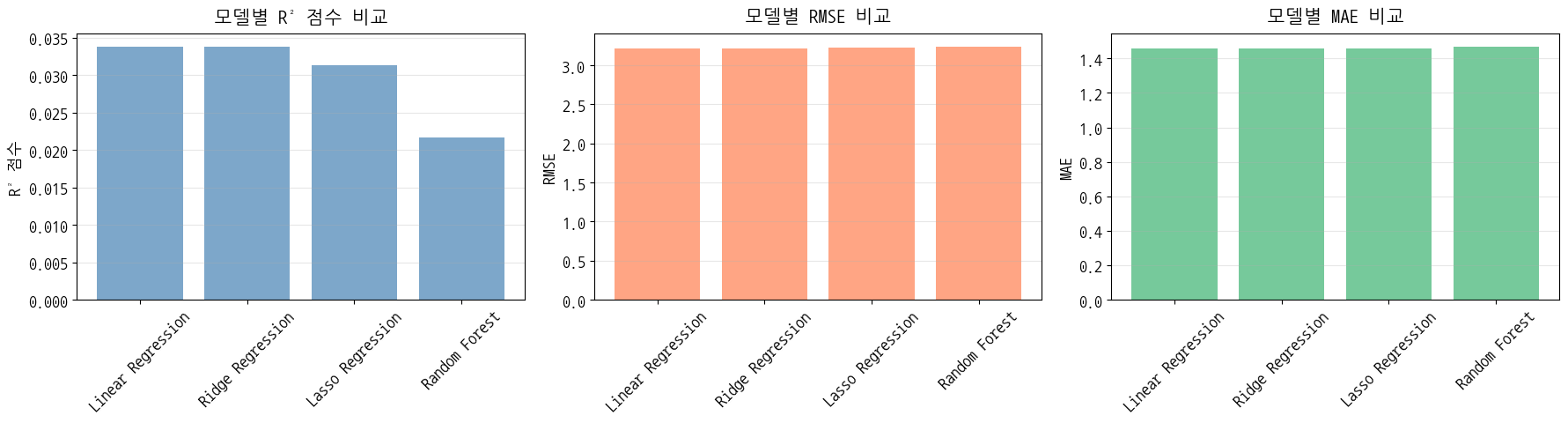
- Linear Regression:
- 학습 RMSE: 3.1428, 테스트 RMSE: 3.2213
- 학습 MAE: 1.4239, 테스트 MAE: 1.4562
- 학습 R²: 0.0316, 테스트 R²: 0.0338
- Ridge Regression:
- 학습 RMSE: 3.1429, 테스트 RMSE: 3.2214
- 학습 MAE: 1.4238, 테스트 MAE: 1.4561
- 학습 R²: 0.0315, 테스트 R²: 0.0338
- Lasso Regression:
- 학습 RMSE: 3.1474, 테스트 RMSE: 3.2255
- 학습 MAE: 1.4254, 테스트 MAE: 1.4585
- 학습 R²: 0.0287, 테스트 R²: 0.0313
- Random Forest:
- 학습 RMSE: 3.0495, 테스트 RMSE: 3.2416
- 학습 MAE: 1.3820, 테스트 MAE: 1.4696
- 학습 R²: 0.0882, 테스트 R²: 0.0216
- Linear Regression:
- 최적 모델 및 특성 중요도
- 최적 모델: Linear Regression (테스트 R²: 0.0338)
- 특성 계수 (선형 모델):
- pH: 16.8160
- Temperature: -6.8066
- unstable_condition: -2.7666
- ph_high: -2.7666
- temp_low: -2.7666
- ph_temp_interaction: -0.4755
- ph_squared: 0.9655
- temp_squared: 0.0893
- ph_distance_from_3: -2.7800
- temp_distance_from_45: -0.8663
- 절편: 230.3006
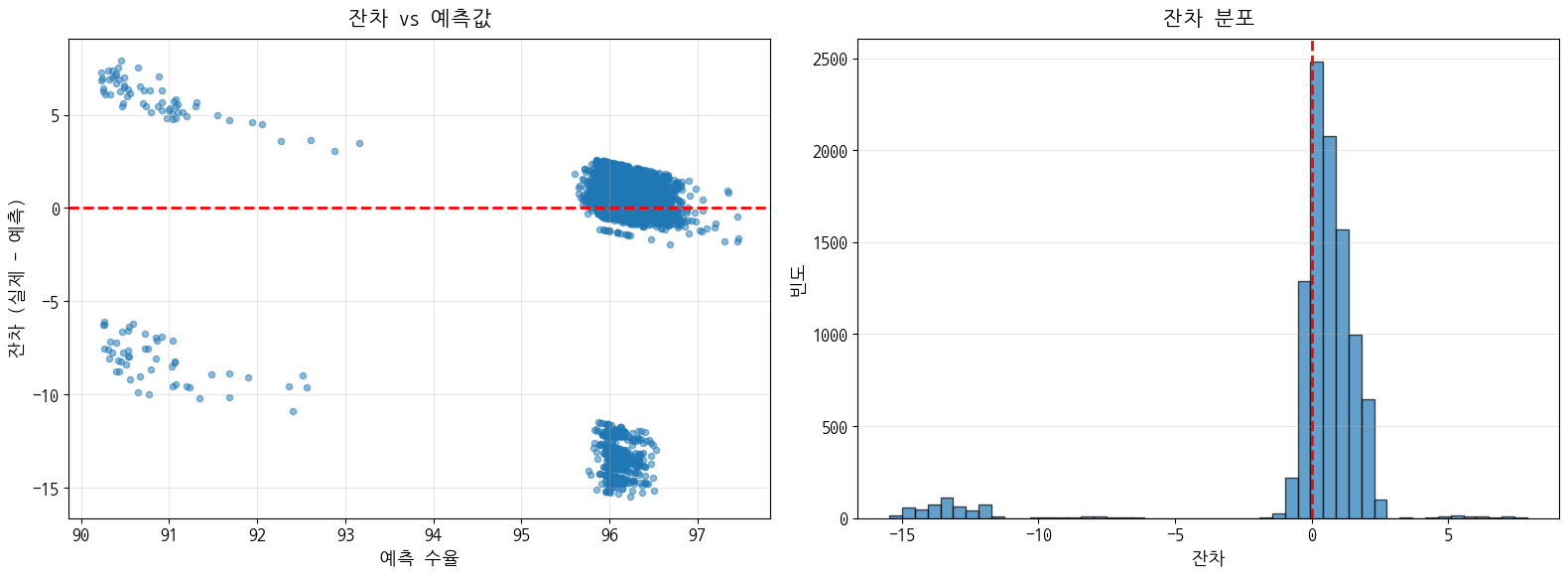
- 불안정 구간 성능 분석
- 불안정 구간 (pH>=3.0 & Temp<45):
- 데이터 수: 112
- RMSE: 7.1057
- MAE: 6.9190
- R²: -0.0178
- 안정 구간:
- 데이터 수: 9907
- RMSE: 3.1502
- MAE: 1.3944
- R²: 0.0010
- 성능 차이:
- RMSE 차이: 3.9555
- MAE 차이: 5.5246
- R² 차이: 0.0188
- 불안정 구간 (pH>=3.0 & Temp<45):
모델 예측 결과
![]()
![]()
![]()
![]()
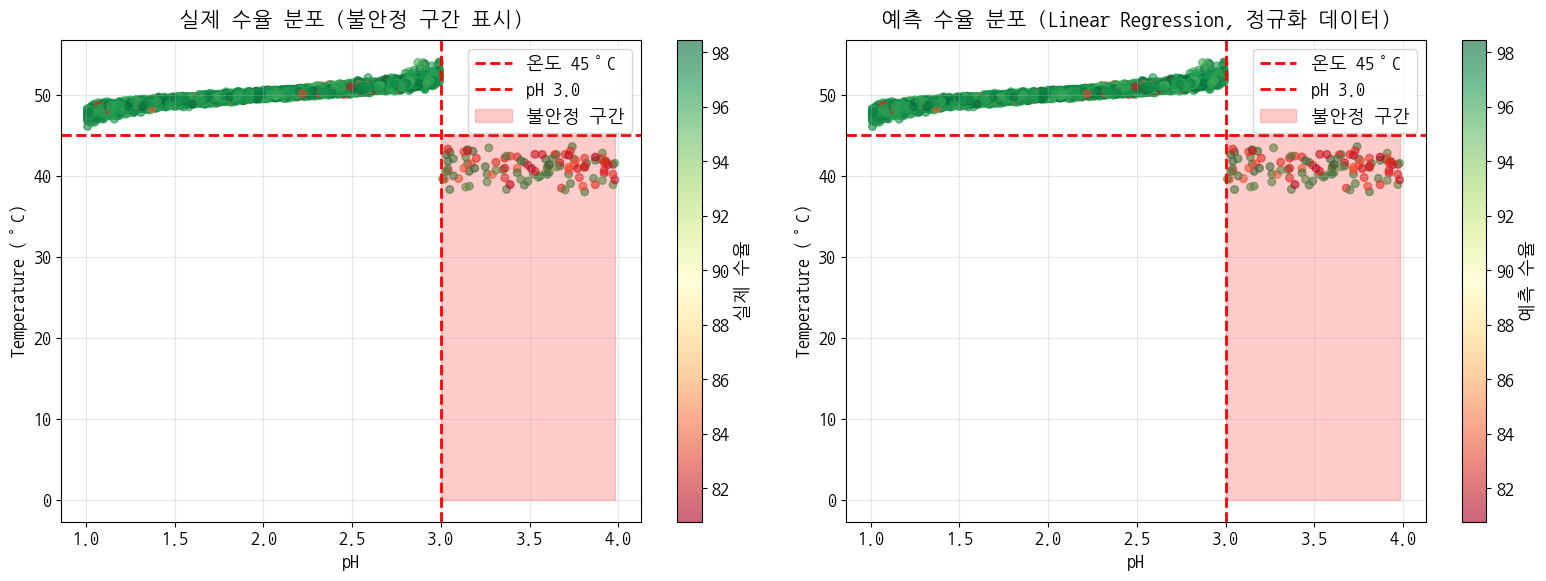
정규화 모델
- 데이터 준비나 그 구성은 비정규화 모델과 동일하나, 계산의 기반 데이터를 정규화된 데이터로 사용함
- 사용한 기본 제공 속성
- lot
- pH_Standard
- Temperature_Standard
- ProcessRate
- 새로 만든 속성
- unstable_condition: (정규화 이전 기준) pH 3.0 이상 and 온도 45 미만
- pH 높음: (정규화 이전 기준) 3.0 이상
- 온도 낮음: (정규화 이전 기준) 45 미만
- 상호작용 특성: pH 값과 온도 값의 곱
- pH와 온도 각각의 제곱 값
- 수율 불안정 구간과의 거리 값:
pH - 3.0,온도 - 45
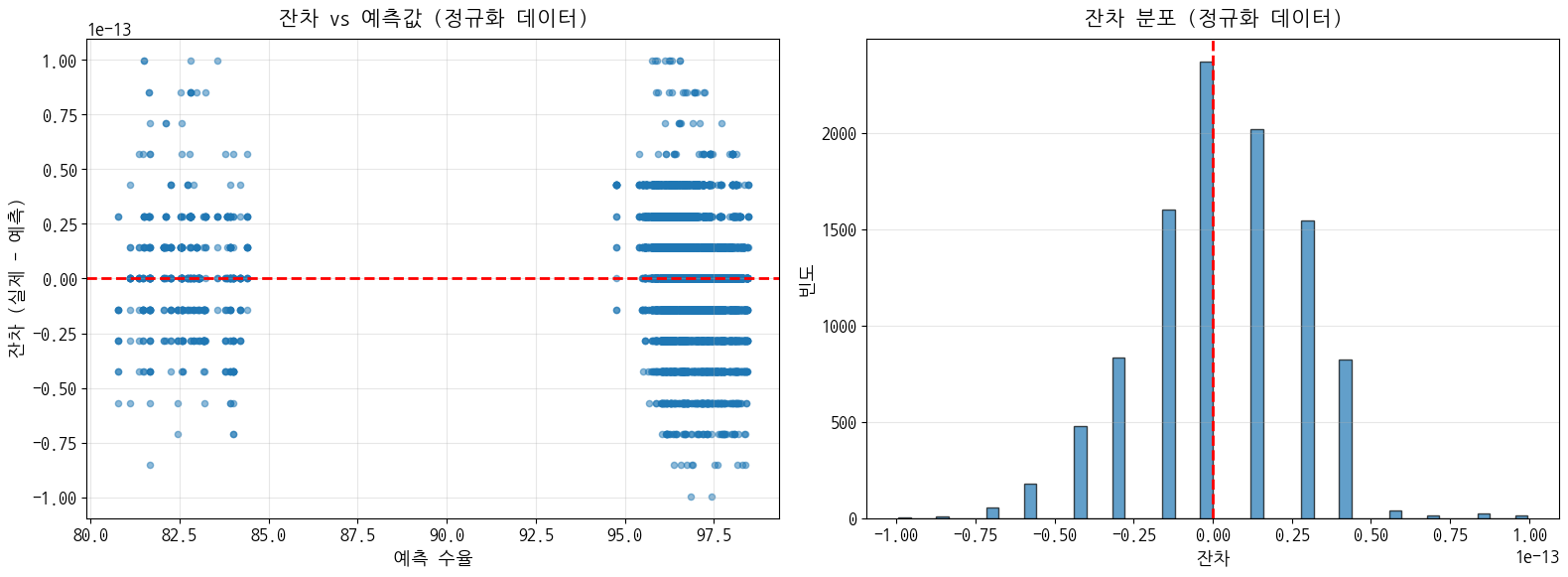
- 모델 학습 및 평가 (정규화된 데이터)
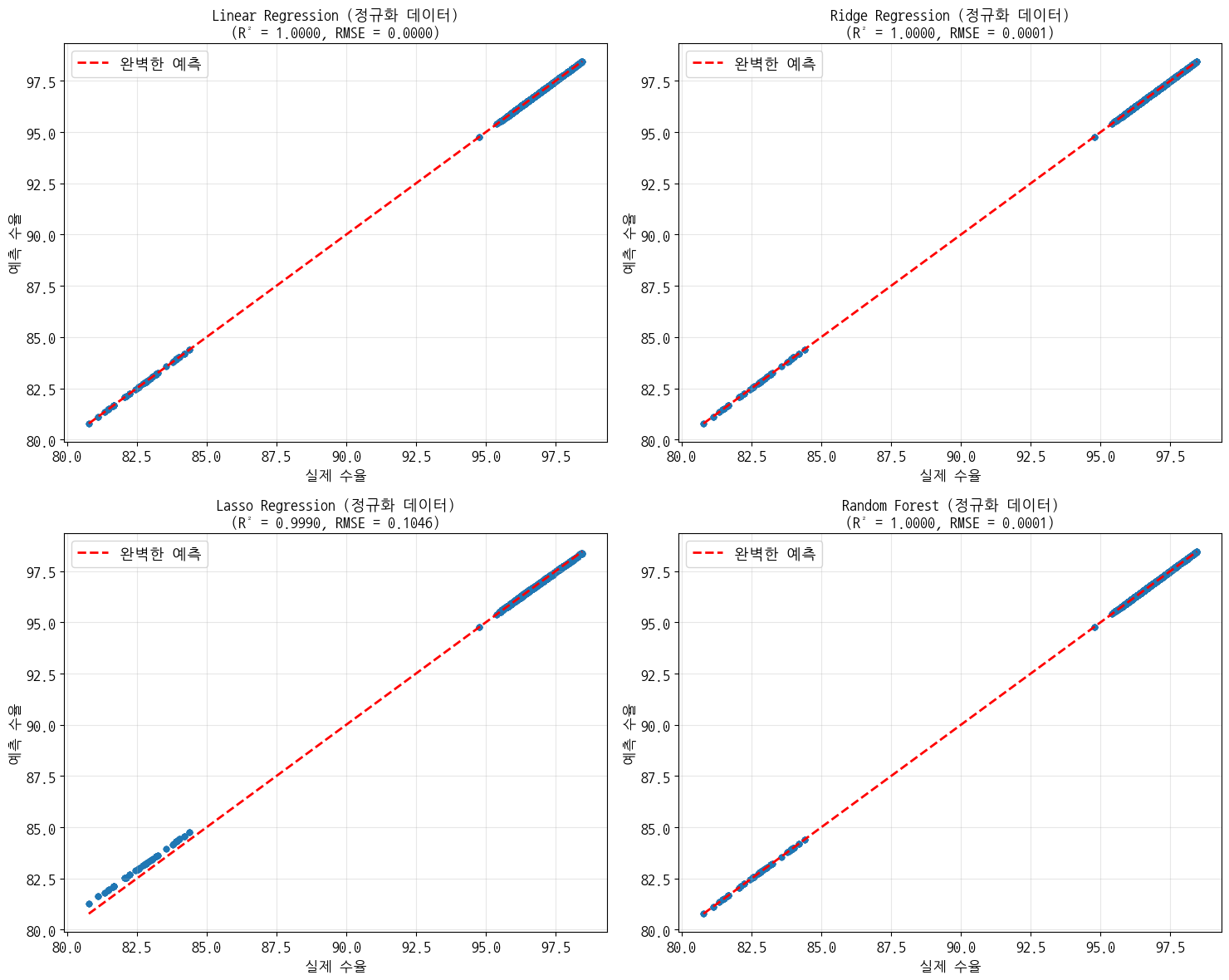
- Linear Regression:
- 학습 RMSE: 0.0000, 테스트 RMSE: 0.0000
- 학습 MAE: 0.0000, 테스트 MAE: 0.0000
- 학습 R²: 1.0000, 테스트 R²: 1.0000
- Ridge Regression:
- 학습 RMSE: 0.0001, 테스트 RMSE: 0.0001
- 학습 MAE: 0.0000, 테스트 MAE: 0.0000
- 학습 R²: 1.0000, 테스트 R²: 1.0000
- Lasso Regression:
- 학습 RMSE: 0.1019, 테스트 RMSE: 0.1046
- 학습 MAE: 0.0480, 테스트 MAE: 0.0490
- 학습 R²: 0.9990, 테스트 R²: 0.9990
- Random Forest:
- 학습 RMSE: 0.0001, 테스트 RMSE: 0.0001
- 학습 MAE: 0.0000, 테스트 MAE: 0.0000
- 학습 R²: 1.0000, 테스트 R²: 1.0000
- Linear Regression:
- 최적 모델 및 특성 중요도 (정규화된 데이터)
- 최적 모델: Linear Regression (테스트 R²: 1.0000)
- 특성 계수 (선형 모델):
- pH_Standard: 0.0000
- Temperature_Standard: 0.0000
- ProcessRate_Standard: 0.0000
- unstable_condition: -0.0000
- ph_high: 3.2106
- temp_low: 0.0000
- ph_temp_interaction: 0.0000
- ph_squared: 0.0000
- temp_squared: 0.0000
- ph_distance_from_threshold: 0.0000
- temp_distance_from_threshold: 0.0000
- 절편: 96.0642
- 불안정 구간 성능 분석 (정규화된 데이터)
- 불안정 구간 (pH_Standard>=1.8008 & Temp_Standard<-3.6245):
- 데이터 수: 112
- RMSE: 0.0000
- MAE: 0.0000
- R²: 1.0000
- 안정 구간:
- 데이터 수: 9907
- RMSE: 0.0000
- MAE: 0.0000
- R²: 1.0000
- 성능 차이:
- RMSE 차이: 0.0000
- MAE 차이: 0.0000
- R² 차이: 0.0000
- 불안정 구간 (pH_Standard>=1.8008 & Temp_Standard<-3.6245):
- 모델 예측 결과
![]()
![]()
![]()
![]()
종합 비교
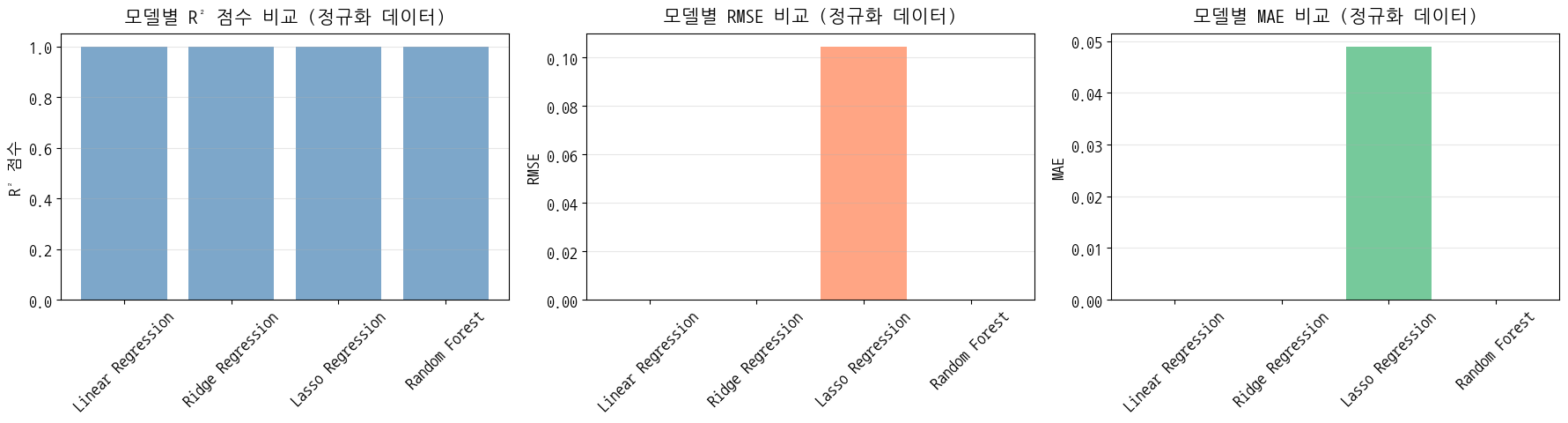
이전 모델(원본 데이터) vs 현재 모델(정규화 데이터) 비교
| 전체 테스트 성능 비교 모델 | 이전 R² | 현재 R² | 개선도 |
|---|---|---|---|
| Linear Regression | 0.0338 | 1.000 | +0.9662 |
| Ridge Regression | 0.0338 | 1.000 | +0.9662 |
| Lasso Regression | 0.0313 | 0.990 | +0.9676 |
| Random Forest | 0.0216 | 1.000 | +0.9784 |