
우리는 이걸 데이터 전처리라고 부르기로 했어요.
참고
사용한 데이터셋 : https://www.kaggle.com/uciml/glass
내 코드 보기 : https://www.kaggle.com/dapin1490/glass/notebook
노션에서 정리 보기 : https://dapin1490.notion.site/DIY-ae97a364485946ae832f52e8022bf202
알림 : 내가 이해한 대로 설명하는 것이니 틀린 부분이 있을 수 있다. 지적 환영!
지난 글 보기
딥러닝 모델에게 데이터 떠먹이는 방법 (1)
- 첨도와 왜도, 상관 관계
- K겹 교차검증은 원 핫 벡터를 인자로 전달할 수 없다
딥러닝 모델에게 데이터 떠먹이는 방법 (2)
- 데이터의 상태가 이상하다!
- 랜덤 언더, 오버 샘플링
- SMOTE 오버 샘플링
- ADASYN 오버 샘플링
이번 글 목차
1. 클래스 별 차등 가중치 부여하기
2. 꼭 결측치가 있어야만 속성을 삭제할 수 있는 건 아니다
1. 클래스 별 차등 가중치 부여하기
예부터 들어보자. 여기 걸리는 사람은 많지만 죽는 사람은 적은 어떤 병이 있다. 의사는 환자의 상태를 보고 이 환자가 살지 죽을지 예측하고 싶다. 사람이 일일이 데이터를 보고 예측하기는 어려우니 딥러닝 모델의 도움을 받기로 했다. 클래스는 “생존”과 “사망” 두 가지 뿐이지만 샘플 수의 비율은 8:2 정도로 불균형하다고 하자. 이제 모델을 만들어야 한다. 어떻게 해야 할까?
환자가 생존하는 데이터는 충분히 많다. 예측이 어렵지 않을 것이다. 그러나 환자가 사망하는 데이터는 적다. 그래도 가능한 정확하게 예측해야만 한다. 이럴 때 쓸 수 있는 게 사용자가 클래스 별로 서로 다른 가중치를 직접 부여하는 방법이다. 샘플이 많아 예측하기 쉬운 클래스에는 가중치를 작게 주고, 샘플이 적어 예측하기 어려운 클래스에는 가중치를 크게 준다. 이 가중치는 모델의 예측이 틀렸을 때 받는 일종의 패널티라고 생각하면 이해하기 좋다. 여기서는 8:2라고 했으니 가중치는 0.2 : 0.8 정도로 줄 수 있다. 샘플 수의 비율과 반대되는 비율로 준다고 생각하면 된다. 물론 반드시 그래야 하는 것은 아니고, 모델을 직접 실행하여 정확도를 보고 조정할 수 있다.
코드로 보자. 모델을 선언하여 층을 추가한 이후의 코드로, 컴파일과 fit 부분만 가져왔다. 이 모델의 데이터셋은 아쉽게도 내가 쓴 예시대로 환자의 생존률 예측은 아니고 이 글의 가장 처음에 나와 있는 유리 분류 데이터셋이다.
1
2
3
4
5
6
# 차등 가중치를 딕셔너리 자료형으로 지정
c_weight = {0:1, 1:0.2, 2:0.2, 3:0.65, 4:1, 5:0.75, 6:0.8, 7:0.55}
# 컴파일, 모델 실행
# class_weight 인자에 지정한 가중치를 전달한다
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=['accuracy'])
model.fit(X[train], Y_one_tr, validation_split=0.3, epochs=1000, batch_size=60, verbose=1, class_weight=c_weight)
주의사항이 있다. 원 핫 인코딩을 했다면 원 핫 벡터의 길이만큼 모든 인덱스에 가중치를 직접 주어야 한다. 해당 클래스의 샘플이 실제로 존재하지 않더라도 가중치는 주어야 한다. 클래스가 두 가지 뿐이라면 ‘class_weight=0.25’ 처럼 써서 가중치를 비율로 지정할 수 있다.
가중치 값은 모델의 정확도를 보고 조정하는 것이긴 하지만, 0이나 1에 너무 가까우면 정확도가 오히려 떨어지는 것 같았다. 다만 이 코드에서 0번과 4번 클래스에 가중치가 1로 주어진 이유는 실제로 그 클래스가 존재하지 않기 때문이었다.
2. 꼭 결측치가 있어야만 속성을 삭제할 수 있는 건 아니다
설명을 시작하기에 앞서 단어 하나만 알고 가자. 결측치란 측정되지 않아 비어 있는 부분(null)이 존재하는 데이터를 말한다. 사전을 찾아보니 영어로는 missing value, 말 그대로의 뜻이다.
이번에도 예시로 생각해보자. 알기 쉽게 크고 극단적인 것으로 하겠다.
여기 지구 전체의 일기 데이터가 있다고 하자. 남극의 한 연구원은 이 데이터를 가지고 남극의 날씨와 펭귄의 번식 횟수 사이에 상관 관계가 있는지 알아보고 싶다. 이 연구원은 데이터를 전부 다 사용할까?
나는 남극에 가본 적도 없고 기후에 대해 아는 것도 고등학교 수준으로 한 지구과학이 다라서 남극의 날씨에 어떤 요소가 영향을 주는지는 알 수 없지만, 지구 전체의 데이터가 전부 필요할 거라는 생각은 들지 않는다. 딥러닝 모델은 예측에 필요하지 않은 데이터를 스스로 골라내는 기능이 없으니 사람이 골라줘야 한다. 데이터를 골라내는 방법은 속성 삭제와 샘플 삭제 두 가지가 있는데 지금은 속성 삭제에 대해서만 보겠다. 샘플 삭제에 대해 내가 아는 것을 간단히 언급하자면, 정보가 수집되지 않았거나 누락되어 빈 칸이 너무 많은 샘플을 주로 삭제한다고 한다. 다시 말해 총 속성이 10가지 정도 있을 때 그중 7가지 속성에 대한 값이 누락된 그런 샘플을 삭제한다는 말이다.
개별 케이스를 지우는 샘플 삭제와 달리 속성 삭제는 예측에 고려할 요소 하나를 통째로 삭제한다. 당연히 사람이 감으로 마구니를 찾아 제거하는 것이 아니고 먼저 어떤 속성을 삭제할지 정할 필요가 있다. 어떤 속성이 클래스와 관련이 적은지 어떻게 알 수 있을까?
파이썬에서는 다양한 라이브러리를 사용할 수 있다. 그중에는 데이터의 통계를 보고, 그것을 시각화하는 데 유용하게 사용할 수 있는 라이브러리가 있다.
1
2
3
4
import numpy as np # 넘파이 : 행렬이나 일반적으로 대규모 다차원 배열을 쉽게 처리 할 수 있도록 지원하는 파이썬의 라이브러리, 출처 위키백과
import pandas as pd # 판다스 : 데이터 분석. 데이터 불러오기를 할 때에도 사용
import matplotlib.pyplot as plt # 그래프 그리기
import seaborn as sns # 그래프 그리기
더 많은 정보는 이 링크에서 확인할 수 있다. 내가 첨도와 왜도, 상관 관계를 공부할 때 많은 참고가 되었던 문서다. 나는 아직까지 여러 라이브러리를 자유자재로 활용할 실력은 되지 못하니 아는 만큼만 보여주겠다.
데이터가 어떤 상태이고 어떻게 구성되었는지 보기 위해 알아보는 요소 중 “상관 관계”라는 것이 있다. 판다스 라이브러리의 함수를 사용하면 어떤 속성과 어떤 속성이 서로 얼마나 관련이 있는지를 실수로 표현할 수 있는데, 이 값이 -1에 가까울수록 반비례 관계이고, 1에 가까울수록 정비례 관계이다. 그러니 어떤 방향으로든 절댓값이 클수록 관계성이 크다는 말이다. 코드는 아래와 같이 쓴다. 여기서 클래스는 ‘Type’ 속성이다.
1
2
3
4
5
6
# 데이터셋에 존재하는 모든 속성 사이의 상관 관계를 보여준다
print("\n속성 간 상관 관계")
print(data.corr())
# 특정 속성과 나머지 속성 사이의 상관 관계만을 보여준다.
print("\n클래스와 각 속성의 상관 관계")
print(data.corr()['Type'])
결과는 다음 이미지와 같이 나온다.
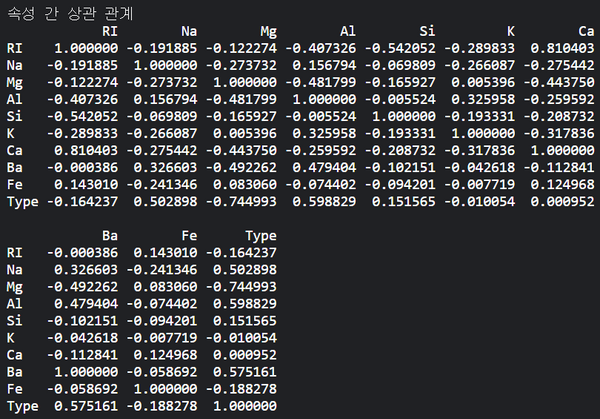
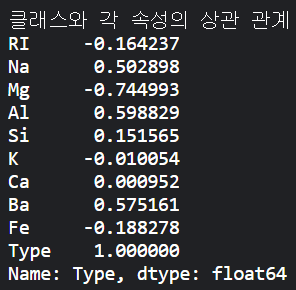
속성들이 서로 얼마나 관계가 있는지 알려주는 건 좋은데, 죄다 소수인데다 자릿수도 많으니 영 보기가 불편하다. 여기 이 이미지와 똑같은 정보를 알록달록한 이미지로 볼 수 있는 방법이 있다. 위에 써있는 네 가지 라이브러리 중 아래 두 가지 라이브러리를 사용하면 가능하다. 히스토그램과 히트맵을 볼 수 있는데, 나는 히트맵에 대해서만 설명하겠다. 히트맵은 간단히 열화상 카메라처럼 상관 관계 값이 클 수록 사용자가 지정한 색이 진하게 표시되고 값이 작을수록 색이 연해지는 그래프라고 보면 된다. 코드를 보자.
1
2
3
4
5
6
7
8
9
# 필요 라이브러리
import matplotlib.pyplot as plt
import seaborn as sns
print("\n상관 관계 시각화")
plt.figure(figsize=(10, 8)) # 히트맵 각 칸의 크기를 정한다. 가로, 세로 순서이다.
sns.heatmap(data.corr(), annot=True, cmap="YlGnBu", vmax=1)
# data.corr()는 히트맵에 들어갈 값이다. cmap은 히트맵의 색깔 테마를 정한다. vmax는 색이 얼마에 가까워질수록 진해질지 그 최댓값을 정한다.
plt.show() # 히트맵 보여주기
결과 이미지도 있다.
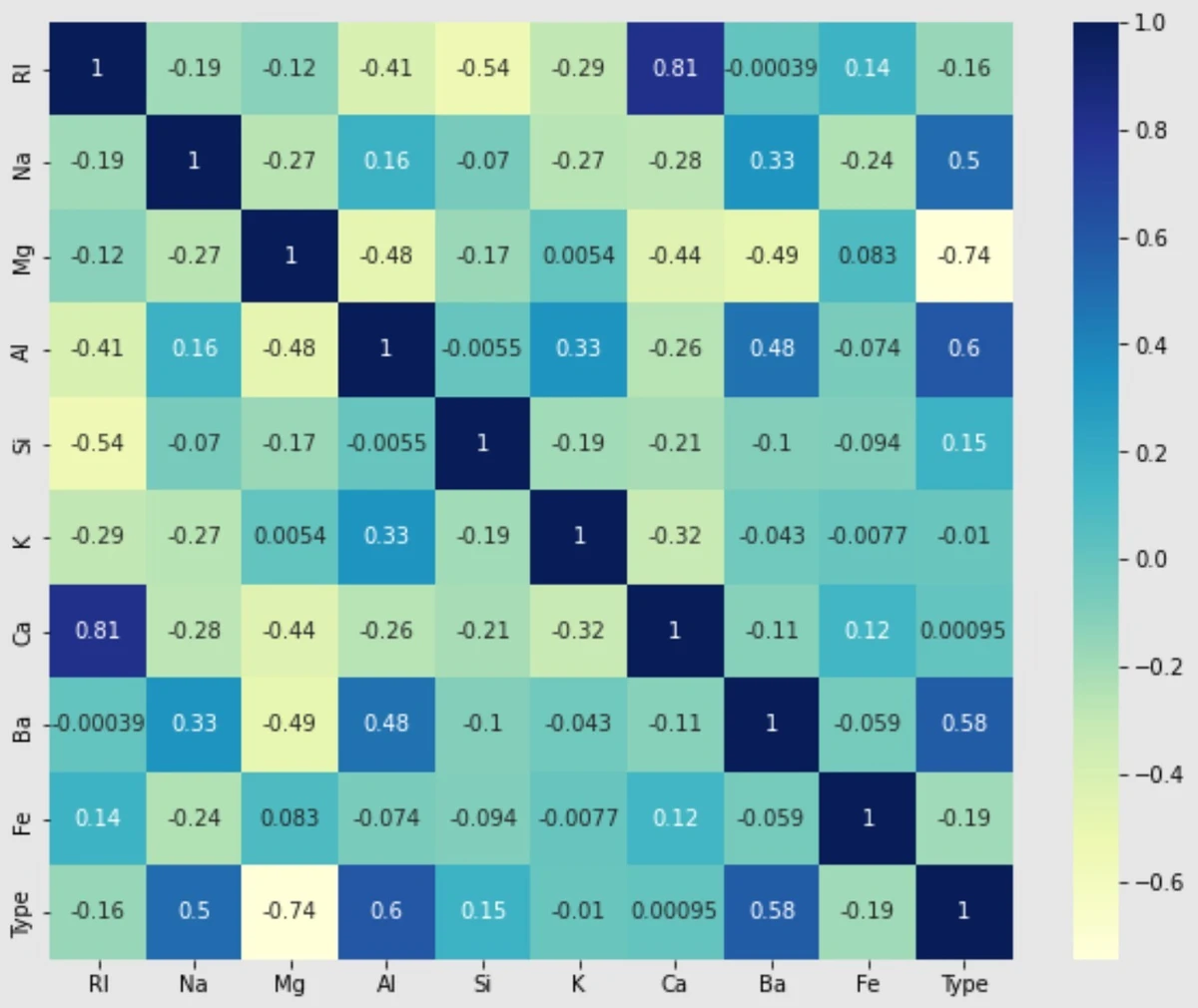
지금 봐야 할 것은 맨 아랫줄이다. 너무 밑에 있어서 불편하다면 맨 오른쪽 세로줄을 봐도 된다. 같은 값이 쓰여 있다.
축을 보면 각 속성의 이름이 쓰여 있다. 히트맵의 칸들은 좌표처럼 가로축의 속성과 세로축의 속성 사이의 상관 관계 값을 나타낸다. 아까도 말했듯 1에 가까울수록 정비례 관계이고 이 히트맵은 vmax가 1로 지정되어 있기 때문에 진한 파란색을 띄는 칸을 찾으면 금방 보인다. ‘Na’, ‘Al’, ‘Ba’ 속성의 색이 유독 진한 것을 볼 수 있다. 그리고 ‘Mg’ 속성의 색이 아주 연한 것도 보인다.
아직까지 나는 어떤 기준을 갖고 속성을 삭제하는 게 적절한지는 모른다. 여러 데이터셋으로 이런저런 실험을 하면서 알아가는 중이다.. 이 데이터셋에서 나는 상관 관계 값이 음수인 속성을 모두 삭제했었다. 우연히 그 방법이 잘 통했는지 정확도가 20%p나 올랐었다.
다음은 그 코드이다. ‘log_K’와 ‘log_Ca’ 속성은 신경쓰지 않아도 된다. 첨도와 왜도가 높은 속성에 로그를 취했던 것인데 지금 중요한 부분은 아니다.
1
2
3
4
5
# 상관 관계가 반비례인 속성은 삭제하고 정비례에 가까운 속성만 남긴다
data.drop(['Mg', 'log_K', 'log_Ca', 'Fe'], axis=1, inplace=True)
# 지정한 속성을 삭제한다
print("\nafter drop")
print(data.info()) # 삭제 후 데이터 정보 확인
속성을 삭제하는 코드도 위에 링크한 문서에서 더 자세히 배울 수 있다.
내가 할 말은 다 끝났는데, 글이 길어져 무슨 말을 하려고 했던 건지 까먹었을 것 같으니 정리해보자. 데이터셋에는 결측치라는 것이 존재할 수 있다. 어떠한 문제로 인해 데이터에 구멍이 난 것인데, 그것을 채울 수 없거나 채우지 않는 게 낫다면 구멍난 부분을 삭제할 수 있다. 이때 특정 샘플만 구멍이 많다면 그 샘플을 삭제하고, 많은 샘플이 공통으로 구멍난 속성이 있다면 그 속성을 삭제한다.
하지만 속성 삭제라는 건 반드시 결측치가 있어야만 해도 된다고 정해진 것은 아니다. 어떤 속성이 예측에 방해가 될 정도로 클래스와 관계가 없거나, 원하는 방향이 아니라면 그 속성을 삭제하고 모델을 학습시키는 게 도움이 될 수 있다. 삭제할 속성을 고를 때는 히트맵을 참고할 수 있다. 당연히 어떤 속성을 삭제하는 게 옳다고 답이 정해진 문제는 아니니 적당히 골라야 한다!