
우리는 이걸 데이터 전처리라고 부르기로 했어요.
참고
사용한 데이터셋 : https://www.kaggle.com/uciml/glass
내 코드 보기 : https://www.kaggle.com/dapin1490/glass/notebook
노션에서 정리 보기 : https://dapin1490.notion.site/DIY-ae97a364485946ae832f52e8022bf202
알림 : 내가 이해한 대로 설명하는 것이니 틀린 부분이 있을 수 있다. 지적 환영!
지난 글 보기
딥러닝 모델에게 데이터 떠먹이는 방법 (1)
- 첨도와 왜도, 상관 관계
- K겹 교차검증은 원 핫 벡터를 인자로 전달할 수 없다
이번 글 목차
0. 데이터의 상태가 이상하다!
1. 랜덤 언더, 오버 샘플링
2. SMOTE 오버 샘플링
3. ADASYN 오버 샘플링
다음 글 보기
딥러닝 모델에게 데이터 떠먹이는 방법 (3)
- 클래스 별 차등 가중치 부여하기
- 꼭 결측치가 있어야만 속성을 삭제할 수 있는 건 아니다
0. 데이터의 상태가 이상하다!
여기 서로 다른 두 데이터셋의 클래스 분포를 보여주는 히스토그램이 있다. 왼쪽은 유리 분류 데이터셋, 오른쪽은 별 유형 분류 데이터셋이다. 딱 봐도 비교되는 느낌이 온다. 왼쪽보다 오른쪽이 막대의 높이가 일정하다. 왜 저 히스토그램들을 비교해야 할까?
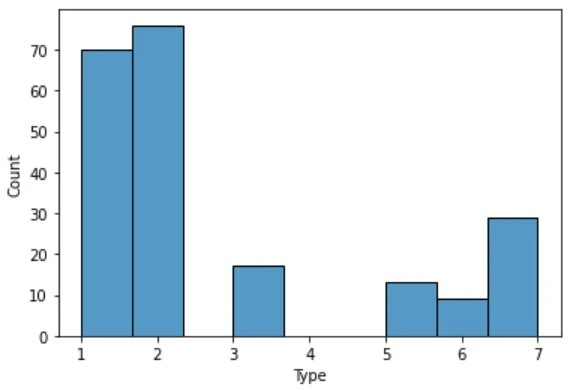
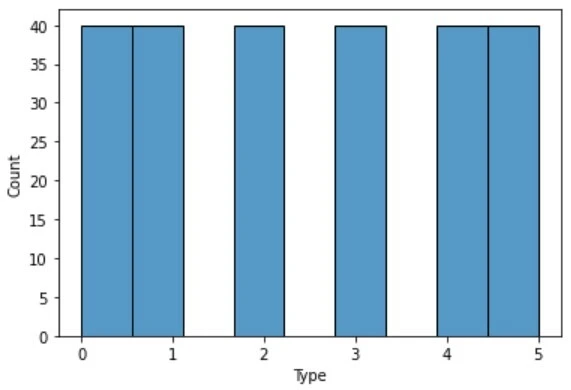
사람이 무언가 배우려면 충분한 경험이 필요한 것처럼 딥러닝 모델도 정확한 학습을 하려면 충분한 데이터(샘플)가 필요하고, 수험생이 공부를 할 때 특정 과목에만 집중하면 전체적인 성적이 떨어지는 것처럼 딥러닝 모델도 특정 클래스의 샘플만 너무 많으면 정확도가 떨어진다. 데이터를 준비하는 것은 사람이 하는 일이니 이런 문제를 미리 확인하고 다듬어줘야 한다. 그 방법은 여러 가지가 있겠지만 이번에는 언더, 오버 샘플링에 대해 설명한다.
1. 랜덤 언더, 오버 샘플링
언더 샘플링은 샘플이 많은 클래스의 데이터를 일부만 뽑아내어 샘플이 적은 클래스와 균형을 맞추는 방법이고, 오버 샘플링은 샘플이 적은 클래스의 데이터를 더 뽑아내어 샘플이 많은 클래스와 균형을 맞추는 방법이다. 공통점은 샘플의 수를 조작하여 클래스의 균형을 맞춘다는 점이고, 차이점은 어떤 샘플의 수를 조작하는지이다.
언더 샘플링은 설명만 봐도 어떻게 하는지 알 것 같다. 필요한 샘플 수보다 데이터셋에 있는 샘플 수가 더 많으니 사용자는 그중에서 고르기만 하면 된다. 소제목에서 알 수 있듯이 이번에는 랜덤으로 고르게 된다. 코드를 봐야 써먹을 테니 일단 코드를 보자.
1
2
3
4
5
6
7
8
import imblearn # 샘플링 관련 라이브러리
print("\nimblearn 버전 확인\n{}".format(imblearn.__version__))
# under-sampling
# 참고 https://dining-developer.tistory.com/27
from imblearn.under_sampling import RandomUnderSampler
X_re, Y_re = RandomUnderSampler(random_state=0).fit_resample(X, Y)
# 결과 : 정확도 35% 미만
나도 인터넷 검색으로 배웠기 때문에 출처가 있다. 참고 링크는 이 문장을 클릭하면 된다.
이 코드는 내가 유리 데이터셋에 실제로 적용했던 것이다. 코드 마지막의 주석을 보면 알겠지만 정확도는 사람이 눈 뜨고 찍었다고 해도 믿을 만한 수치이다(어떠한 샘플링도 사용하지 않았을 때 이 모델의 정확도는 40% ~ 58% 정도 나왔다). 유감스럽게도 이 방법에는 크나큰 단점이 존재한다. 오로지 랜덤으로 샘플을 뽑아내고 기존의 샘플 중 일부만 사용하는 방법이라, 유용하고 중요한 데이터가 사용되지 않을 수 있고 전체 데이터셋의 크기가 작아지게 된다. 그러므로 정확도는 보장할 수 없다.
오버 샘플링은 어떨까? 기대했을지는 모르지만 아쉽게도 크게 다르지 않다. 코드부터 보자.
1
2
3
4
5
6
7
8
import imblearn # 샘플링 관련 라이브러리
print("\nimblearn 버전 확인\n{}".format(imblearn.__version__))
# over-sampling
# 참고 https://ichi.pro/ko/imblearn-laibeuleolilo-bulgyunhyeong-deiteo-seteu-cheoli-245596308465908
from imblearn.over_sampling import RandomOverSampler
X, Y = RandomOverSampler(random_state=0).fit_resample(X, Y)
# 결과 : 정확도 약 30%
참고 링크는 이 문장을 클릭하면 된다.
이 코드도 내가 적용해봤던 것이다. 정확도는 언더 샘플링과 비슷하게 사람이 눈 뜨고 찍는 수준이다. 이 방법의 단점은 아까와는 조금 다르다. 모든 데이터를 다 사용하긴 하는데, 샘플이 적은 클래스의 데이터를 일부 중복하여 사용하기 때문에 과적합에 취약하다. 사람으로 치면 공부는 많이 하는데, 똑같은 몇 문제만 수십 번을 보는 학생이다. 이 학생은 변형과 활용 문제에 약할 것이라고 예상할 수 있듯이 모델도 똑같이 약해진다.
이 문단은 내 생각이니 틀렸다면 지적해주길 바라며, 읽지 않고 넘어가도 무방하다. 여기까지만 보면 랜덤 언더/오버 샘플링은 쓸모가 없는 방법인 것 같다. 그럼 이 방법들이 왜 있을까? 내 경험에 비추어 보았을 때, 보통 이렇게 간단하고 효과가 나쁜 수단들은 다른 복잡하고 효과가 좋은 수단의 프로토타입인 경우가 많았다. 작년에 인공지능의 역사에 대해 조금 배웠는데, 초기의 인공지능은 미연시 게임처럼 논리로 구성된 선택지가 사람에 의해 프로그래밍되고 그 선택지대로만 행동했다고 한다. 사람 두 명과 인공지능 하나로 구성되어 인공지능의 “사람 같음”을 평가하는 튜링 테스트는 당연히 통과하지 못했다. 실패하긴 했지만 그런 시도가 계속해서 있었기 때문에 지금의 챗봇과 여러 인공지능이 있다. 말이 길어지니 좀 거창해졌는데, 랜덤 언더/오버 샘플링도 다른 샘플링 기법의 배경 지식 정도로 생각하면 된다고 생각한다.
2. SMOTE 오버 샘플링
아까는 아무 데이터나 중복해서 뽑았기 때문에 정확도가 낮았으니 이번에는 좀 다르게 데이터를 뽑아보자. 머릿속에 깨끗한 평면을 하나 놓자. 그리고 클래스 별 각각의 샘플을 서로 구분되는 색의 점으로 찍는다고 생각해보자. 특정 클래스의 샘플이 적으니 그 색깔로 찍힌 점도 적을 것이다. SMOTE는 이 소수 클래스의 점들 사이에 선을 긋는다. 그리고 이 선들 위에 새로운 점을 찍어 원본과 비슷하지만 똑같지는 않은 데이터를 오버 샘플링한다. 이전의 방법들보다 과적합에 덜 취약하다.
내가 할 설명은 끝났으니 코드를 보자.
1
2
3
4
5
6
7
8
import imblearn # 샘플링 관련 라이브러리
print("\nimblearn 버전 확인\n{}".format(imblearn.__version__))
# SMOTE 오버 샘플링
# 참고 https://ichi.pro/ko/imblearn-laibeuleolilo-bulgyunhyeong-deiteo-seteu-cheoli-245596308465908
from imblearn.over_sampling import SMOTE
X, Y = SMOTE(random_state=0).fit_resample(X, Y)
# 결과 : 정확도 60% 이하. 기존의 모델에서 약간 개선되긴 하였으나 부족함.
참고 링크는 이 문장을 클릭하면 된다.
위에서도 언급하긴 했지만 내가 이 기법들을 공부할 당시 어떠한 샘플링도 사용하지 않은 내 모델의 정확도는 40~58%였다. 그 상태에서 60%가 나왔으니 미묘한 개선은 개선이지만, 영 부족하다. 아직 내가 아는 것이 적어 이 방법을 온전히 활용하지 못한 것 같다.
3. ADASYN 오버 샘플링
ADASYN은 SMOTE의 개량형이라고 보면 된다. 선을 긋는 것까지는 SMOTE와 같은데, 이 위에 새로운 점을 찍을 때 임의의 작은 값을 더해주어 좀 더 사실적이고 분산된 샘플을 생성한다고 한다.
코드를 보자.
1
2
3
4
5
6
7
8
9
import imblearn # 샘플링 관련 라이브러리
print("\nimblearn 버전 확인\n{}".format(imblearn.__version__))
# ADASYN 오버 샘플링
# 참고 https://dining-developer.tistory.com/27
from imblearn.over_sampling import ADASYN
strategy = {1:70, 2:76, 3:30, 5:30, 6:30, 7:29}
X, Y = ADASYN(sampling_strategy=strategy).fit_resample(X, Y)
# 결과 : 정확도 50% 미만.
참고 링크는 이 문장을 클릭하면 된다.
유감스럽게도 내 모델에서는 SMOTE보다 정확도가 떨어졌다. 저 코드를 쓸 때 약간의 문제가 있었는데, 코드 자체는 어떻게든 실행이 되게 만들었지만 이번에도 역시 내가 잘못 사용한 것 같다.
위의 코드를 보면 SMOTE 코드와 달리 sampling_strategy라는 인자가 들어간 것을 확인할 수 있다. 이 인자는 각 클래스의 샘플들을 어떤 비율로 오버 샘플링할지 정해주는 것인데, 클래스가 단 둘뿐이라면 sampling_strategy 인자에 직접 실수 형태로 전달하여 비율을 지정할 수 있고, 그렇지 않다면 위와 같이 각 클래스 별로 개수를 정해줘야 한다. 이때 개수는 해당 클래스의 원래 샘플 개수와 같거나 더 많아야만 하며 이유는 알지 못했지만 모든 클래스의 샘플 수를 똑같이 지정하면 오류가 난다.